NeurIPS 2022 | Meta 提出二值transformer网络BiT,刷新NLP网络压缩极限
机器之心专栏
来自 Meta 和北京大学的研究者 在 BERT 模型上验证了二值化 tra nsformer 的可行性。

论文地址:https://arxiv.org/abs/2205.13016
代码地址:https://github.com/facebookresearch/bit
BiT 论文的方法主要分为两个部分: (1) 自由度更高的二值化方法 (2) 采用与 student 网络更相近的 teacher 网络进行知识蒸馏。
方法
作者发现,在 transformer block 中, 有两层的输出激活值 (activation) 是非负的,即 Softmax 的输出和前馈网络中的 ReLU 的输出(BiT 采用 ReLU 作为非线性函数),所以作者提出将这些非负的激活值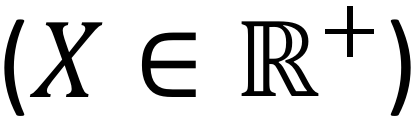

如下图所示
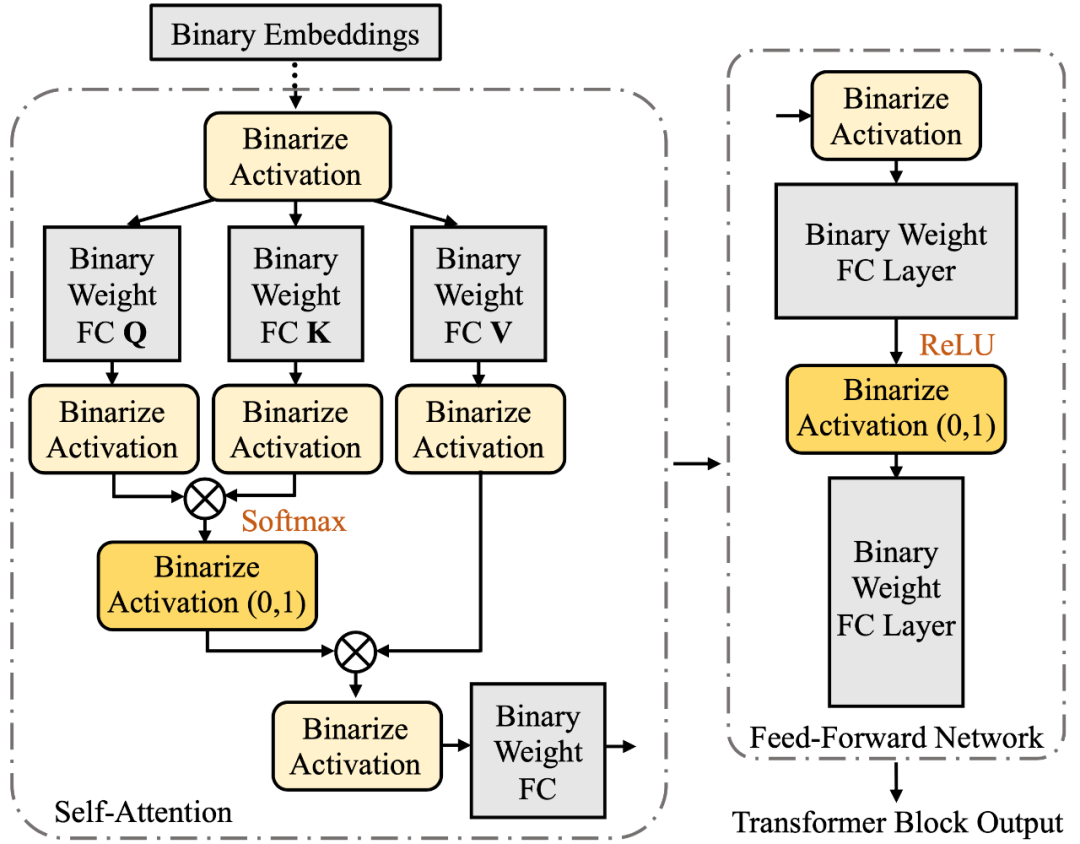
进一步地,作者提出自由度更高的二值化方程。它通过学习对实数值的缩放和偏移,将实数值置于更加合适的量化范围,从而得到更优的二值化输出。
(1) 对于输出只有非负值的层
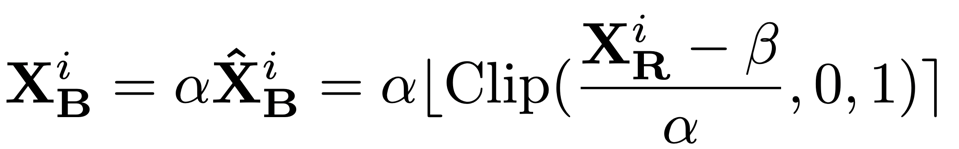
这里的缩放系数 α 和偏移系数 β 都通过导数直接学习。
关于 α 的导数,通过 straight-though estimator (STE) 将不可导的取整函数近似作 CLIP 函数:
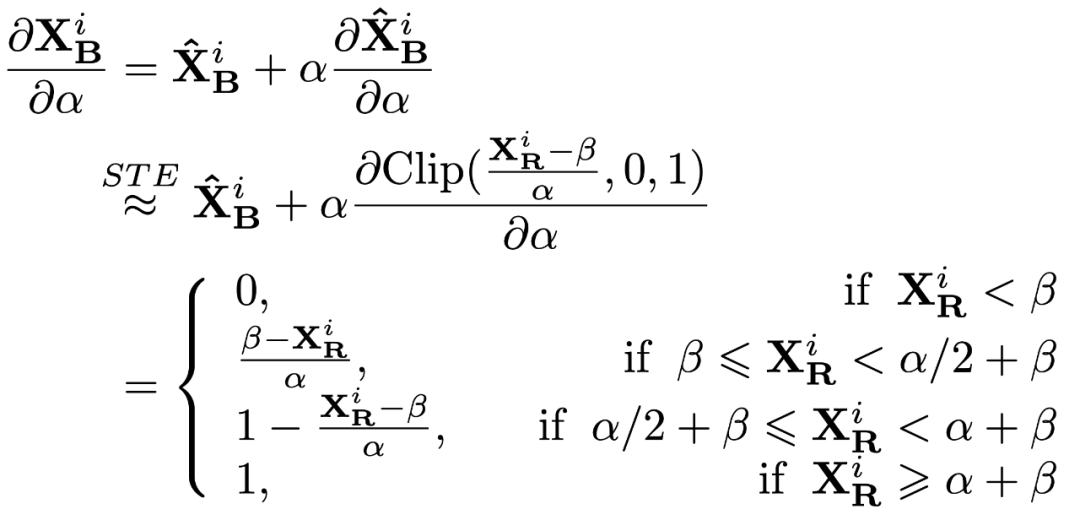
类似地,可以得到对于 β 的导数:
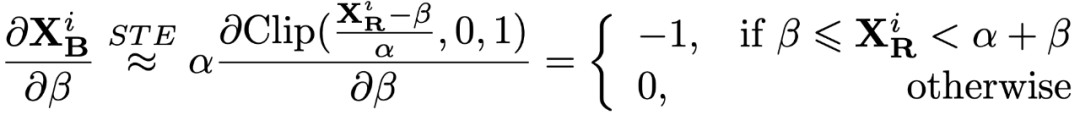
(2) 而对于输出既有正值也有负值的层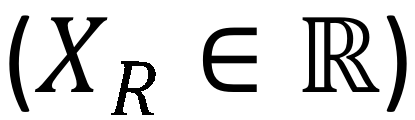
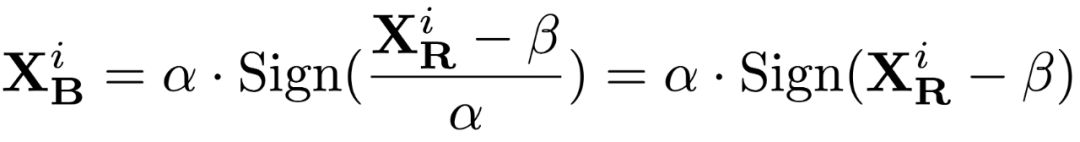
此场景下对缩放系数 α 的求导就非常简单:
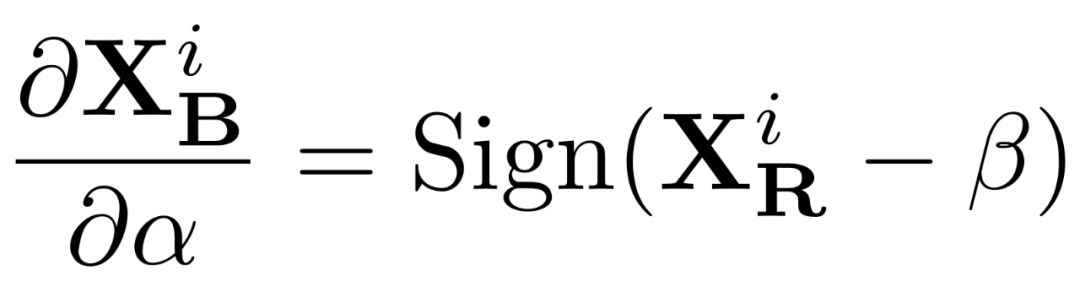
除此之外,作者发现直接用全精度网络蒸馏二值化网络效果并非最优,猜想原因是全精度网络与二值化网络之间的分布差距过大,因此作者提出采用一个 W1A2 网络,即参数值 (W) 为 1 bit, 激活值 (A) 为 2 bit 的网络来作为中间过渡,用全精度网络蒸馏 W1A2 网络,再用 W1A2 网络作为 teacher 蒸馏二值化 (W1A1) 网络,从而进一步提升二值化网络的效果。
3. 实验
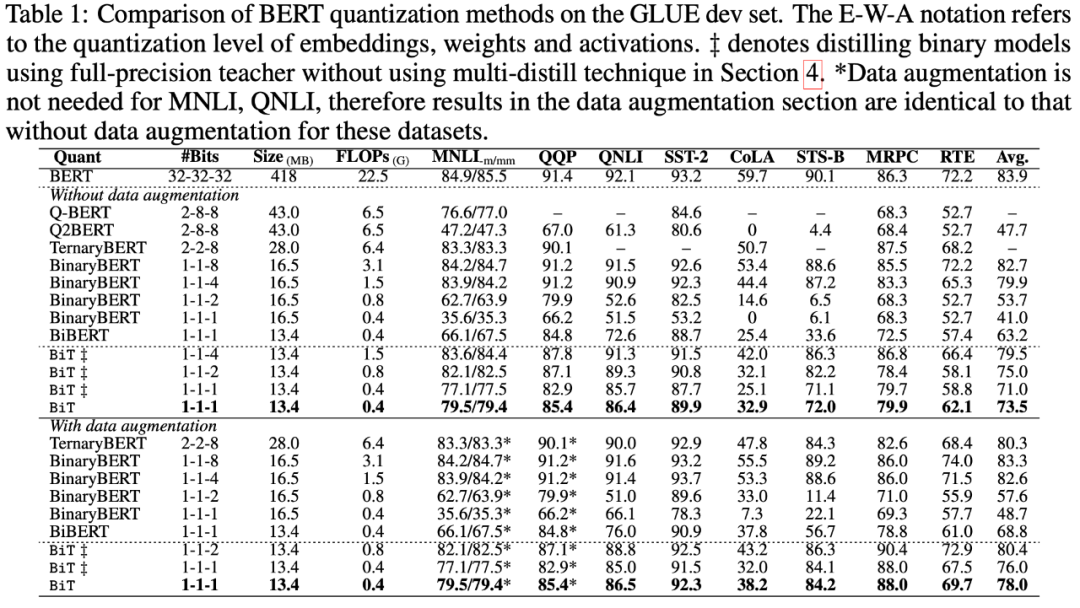
这些看似简单的改进能给二值化网络带来巨大的精度提升。消融实验表明,自由度更高的二值化方程(Elastic binarization )在 GLUE 数据集上带来了 15.7% 的提升,而分布蒸馏进一步带来了 2.5% 提升。

最终结果远超之前的 SOTA 模型 BiBERT,将与全精度网络的差距缩小到了仅 6%。
4. 局限性
本文主要在 BERT 模型上验证了二值化 transformer 的可行性,而其在其他各种预训练 transformer 上的可行性有待进一步试验。并且作者认为,相比于自然语言分类任务,文本生成类任务(比如翻译,文本总结)将会是更具有挑战的任务,也会是一个非常有意思的进一步探索方向。此外该方法在不同领域(例如视觉图像和语音处理)上的性能也会值得研究。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com

