最新综述:跨语言语音合成方法的发展趋势与方向

©PaperWeekly 原创 · 作者 | 音月

引言
语音合成(Text-to-Speech, TTS)是指文字转语音相关技术。随着人工智能技术的发展,TTS 的声学模型和声码器模型效果都在不断提高,单一语言在数据量足够的情况下已经可以合成较高品质的语音。研究人员们也逐渐开始关注跨语言语音合成领域,本文主要介绍了近年来跨语言语音合成方法的发展趋势与方向。

背景
早期人们为了合成跨语言的发音只能用多个语音合成系统来合成不同语言的文本,这样会导致不同语言发音时的音色差异较大,影响使用体验。为了改善这种问题,出现了双语语料库,即让同一个说话人录制多种语言的语音数据。虽然一定程度解决了这种问题,但是双语语料库的制作成本较高,音色数量也较难扩展。
另外也有研究人员根据各语言发音特点设计了源语言到目标语言的音素映射表,用于模仿目标语言的发音,但大多数语言常用的音素集不完全一致,依旧会存在一些无法发音或者发音错误的问题。研究人员开始考虑如何对不同语言的数据进行建模,以达到让目标说话人可以合成其他语言的语音。
下面介绍近年来的一些跨语言语音合成方法。

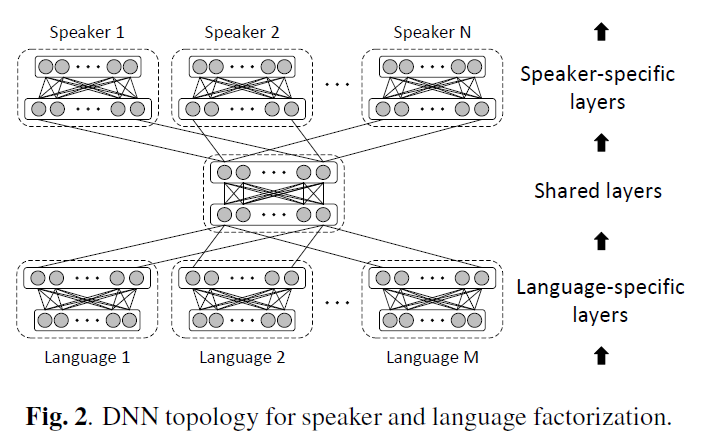
Statistical parametric speech synthesis based on speaker and language factorization(IEEE Trans 2012)[1] 中提出将说话人信息与语言信息分开建模的方法。
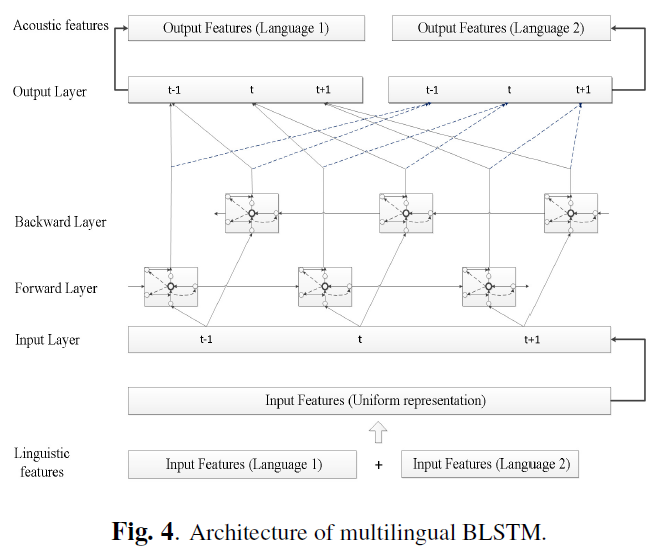
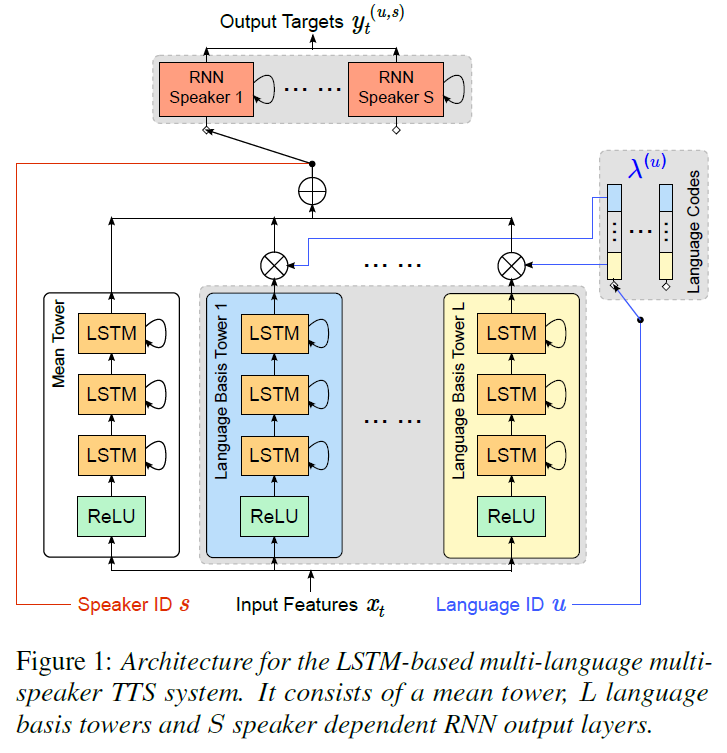
Learning cross-lingual information with multilingual BLSTM for speech synthesis of low-resource languages(ICASSP 2016)[2]

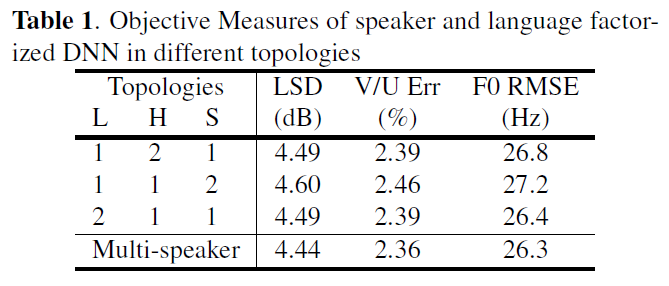
Speaker and language factorization in DNN-based TTS synthesis(ICASSP 2016)[3]
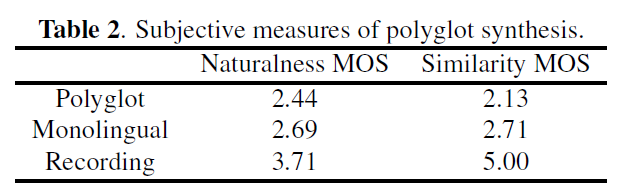
Unsupervised polyglot text to speech(ICASSP 2019)[4]
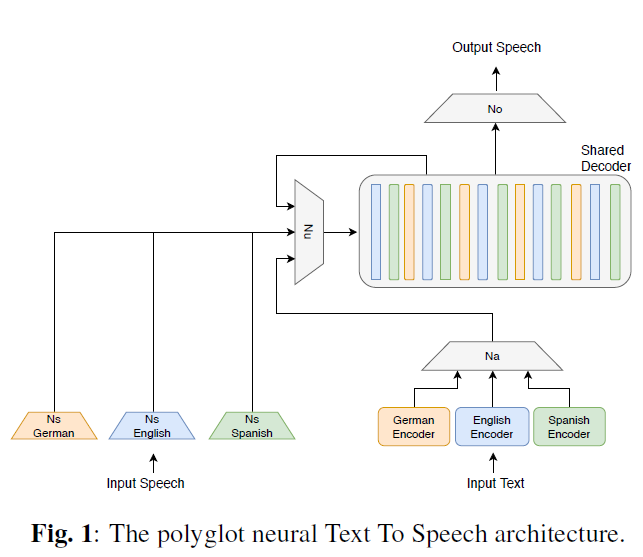
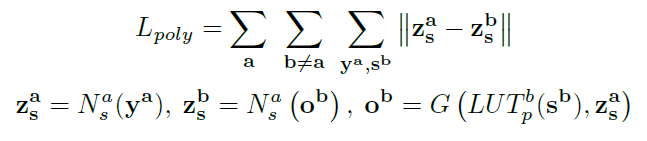
其中 ya 表示语言 a 的语音,用于提取说话人音色信息,sb 表示语言 b 的文本,LUT 为 look-up table,Na 表示语言 a 的 speaker encoder,G 表示 TTS 生成模型,
End-to-end Code-switched TTS with Mix of Monolingual Recordings(ICASSP 2019)[5]
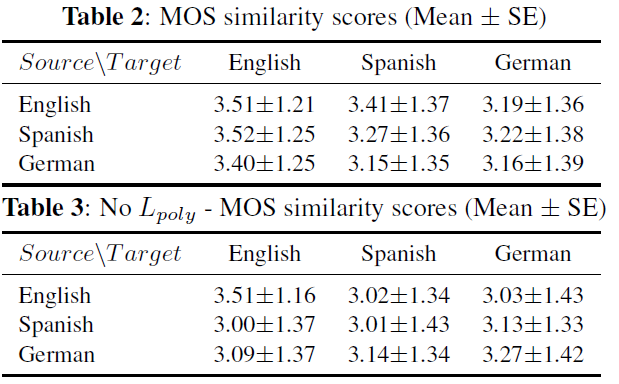
该论文使用了 character embedding,将普通话中的拼音及英语均表示为字母表字符,但直接使用这种 embedding 构造的 tacotron 模型在合成不同语言的语音时会出现音色不一致的情况,因为论文加入 language embedding,并对比了两种嵌入 language embedding 方法对跨语言语音合成效果的影响。
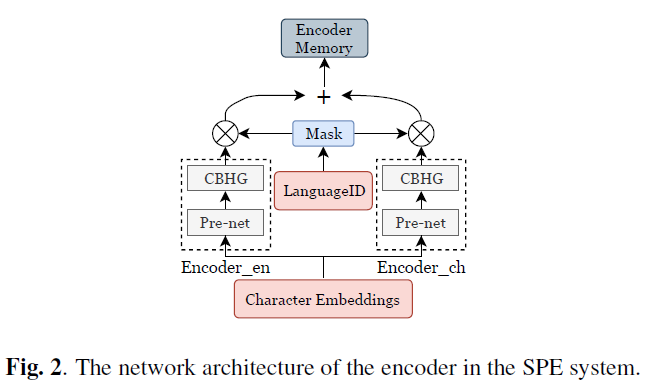

除了跨语言的中间特征,一些研究工作也在探索使用跨语言的文本表示来改善跨语言发音问题。
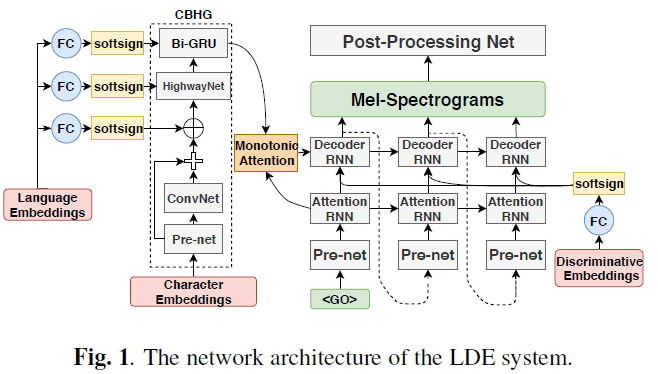
Learning to Speak Fluently in a Foreign Language: Multilingual Speech Synthesis and Cross-Language Voice Cloning(Interspeech 2019)[7]
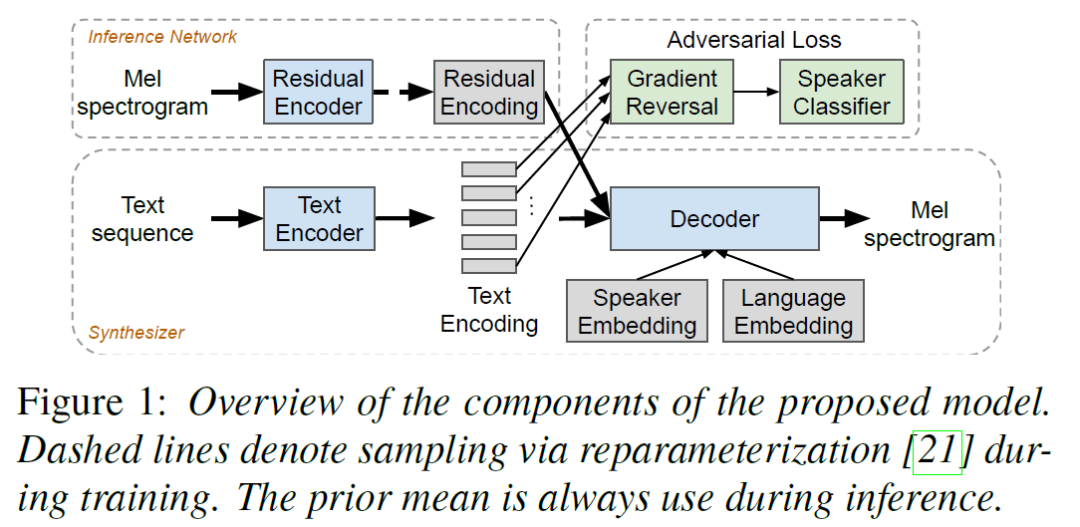
文中 utf-8 编码的 byte 表示方法是将文本字符转为 utf-8 编码,input tokens 为 256,像英语这种单比特字符,byte 表示和 grapheme 表示是一样的,不过对应普通话汉字则会映射得到多比特 utf-8 编码,这种 byte 表示对各种语言的处理方法都是一致的,这种方法的 input tokens 降维到了256(普通话至少有 4500 个常用汉字),可能会得到更好的通用表示。
论文主要基于 tacotron2 框架实现,为了更好的建模 TTS 中文本到语音一对多的问题,论文还加入了 residual encoder。另外,前文中的跨语言中间表示特征基本是通过共享中间网络参数实现的,并没有显式去除 language-dependent 的信息,论文除了在 tacotron2 的 decoder 部分加入 [5] 和 [6] 中使用的 language embedding,结合了对抗式训练方法引入了梯度反传层(GRL)来去除 text encoder 输出特征中 language-dependent 的信息。
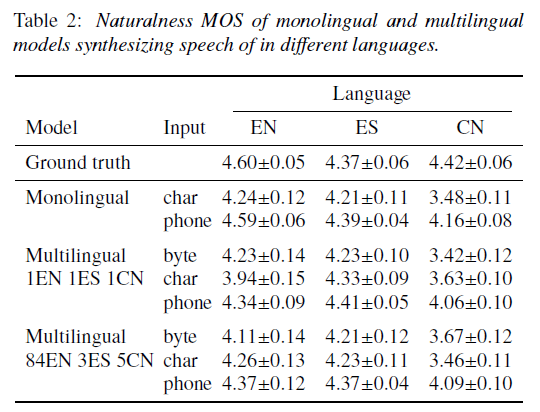
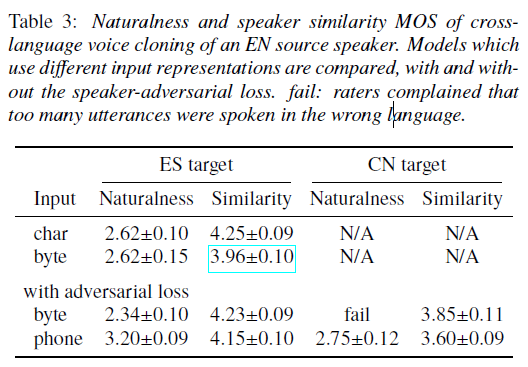
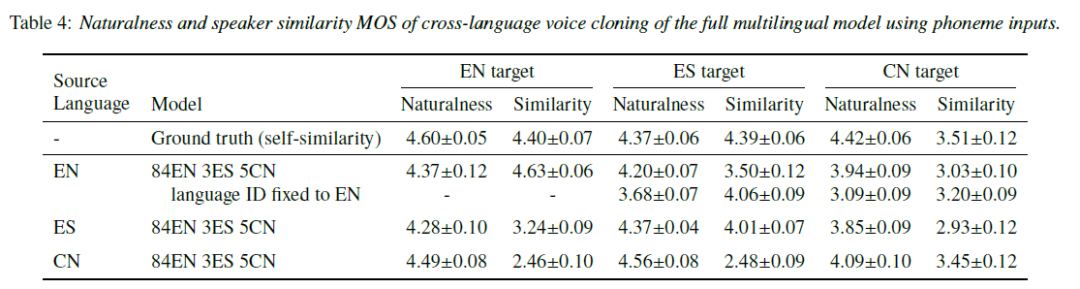
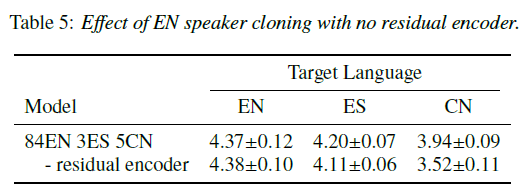
当然除了 byte 作为通用表示,也有研究工作继续尝试基于国际音标 IPA 作为跨语言的文本表示方法:
|
论文名称 |
主要思路 |
||
|
Cross-lingual, Multi-speaker Text-To-Speech Synthesis Using Neural Speaker Embedding (Interspeech 2019) [8] |
IPA表示+speaker encoder提取speaker embedding |
||
|
End-to-End Adversarial Text-to-Speech(ICLR 2021)[9] |
IPA表示+soft dynamic time warping alignment |
||
|
Dynamic Soft Windowing and Language Dependent Style Token for Code-Switching End-to-End Speech Synthesis (Interspeech 2020) [10] |
IPA表示+Dynamic SoftWindowing Mechanism+language embedding |
||
|
Hierarchical Transfer Learning for Multilingual, Multi-Speaker, and Style Transfer DNN-Based TTS on Low-Resource Languages (EEE Access 2020) [11] |
IPA表示+reference encoder+language embedding |
||
|
Improve Cross-Lingual Text-To-Speech Synthesis on Monolingual Corpora with Pitch Contour Information (Interspeech 2021) [12] |
IPA表示+音高起伏特征 |
||
|
Phonological Features for 0-shot Multilingual Speech Synthesis (Interspeech 2020) [13] |
IPA表示衍生的语音学特征 |
||
|
Cross-lingual Low Resource Speaker Adaptation Using Phonological Features (Interspeech 2021) [14] |
IPA表示衍生的语音学特征在小数据合成的应用 |

|
论文名称 |
主要思路 |
||
|
One Model, Many Languages: Meta-learning for Multilingual Text-to-Speech (Interspeech 2020) [15] |
char表示+对抗训练 |
||
|
Cross-lingual Text-To-Speech Synthesis via Domain Adaptation and Perceptual Similarity Regression in Speaker Space (Interspeech 2020) [16] |
将对抗训练方法运用在speaker encoder |
||
|
Cross-lingual Speaker Adaptation using Domain Adaptation and Speaker Consistency Loss for Text-To-Speech Synthesis (Interspeech 2021) [17] |
在 [16] 的基础加入语言无关的SRE模型及类似 [4] 的Adaptation方法 |
||
|
Incorporating Cross-speaker Style Transfer for Multi-language Text-to-Speech (Interspeech 2021) [18] |
style encoder+对抗训练 |

|
论文名称 |
主要思路 |
||
|
End-to-end Text-to-speech for Low-resource Languages by Cross-Lingual Transfer Learning (Interspeech 2019) [19] |
使用ASR系统来自动学习源语言与目标语言的发音映射关系 |
||
|
Building a mixed-lingual neural TTS system with only monolingual data (Interspeech 2019) [20] |
使用平均音色模型fine-tune+phoneme-informed attention机制+speaker embedding位置选择 |
||
|
Multi-Lingual Multi-Speaker Text-to-Speech Synthesis for Voice Cloning with Online Speaker Enrollment (Interspeech 2020) [21] |
设计了一套新的共享的phoneme set |
||
|
Tone Learning in Low-Resource Bilingual TTS (Interspeech 2020) [22] |
加入了声调分类模型 |
||
|
On Improving Code Mixed Speech Synthesis with Mixlingual Grapheme-to-Phoneme Model [23] (Interspeech 2020) |
使用跨语言的G2P模型 |
||
|
Code-Switched Speech Synthesis Using Bilingual Phonetic Posteriorgram with Only Monolingual Corpora (ICASSP 2020) [24] |
使用ASR系统提取跨语言的PPG+Lf0+VUV声学特征+speaker embedding生成Mel频谱 |
||
|
End-to-End Code-Switching TTS with Cross-Lingual Language Model (ICASSP 2020) [25] |
训练跨语言的语言模型提取跨语言的word embedding |
||
|
Towards Natural Bilingual and Code-Switched Speech Synthesis Based on Mix of Monolingual Recordings and Cross-Lingual Voice Conversion (Interspeech 2020) [26] |
使用ASR系统提取跨语言的PPG特征进行语音转换生成多语言训练跨语言TTS模型 |

参考文献
[1] Statistical parametric speech synthesis based on speaker and language factorization
[2] Learning cross-lingual information with multilingual BLSTM for speech synthesis of low-resource languages
[3] Speaker and language factorization in DNN-based TTS synthesis
[4] Unsupervised polyglot text to speech
[5] End-to-end Code-switched TTS with Mix of Monolingual Recordings
[6] Multi-Language Multi-Speaker Acoustic Modeling for LSTM-RNN based Statistical Parametric Speech Synthesis
[7] Learning to Speak Fluently in a Foreign Language: Multilingual Speech Synthesis and Cross-Language Voice Cloning
[8] Cross-lingual, Multi-speaker Text-To-Speech Synthesis Using Neural Speaker Embedding
[9] End-to-End Adversarial Text-to-Speech
[10] Dynamic Soft Windowing and Language Dependent Style Token for Code-Switching End-to-End Speech Synthesis
[11] Hierarchical Transfer Learning for Multilingual, Multi-Speaker, and Style Transfer DNN-Based TTS on Low-Resource Languages
[12] Improve Cross-Lingual Text-To-Speech Synthesis on Monolingual Corpora with Pitch Contour Information
[13] Phonological Features for 0-shot Multilingual Speech Synthesis
[14] Cross-lingual Low Resource Speaker Adaptation Using Phonological Features
[15] One Model, Many Languages: Meta-learning for Multilingual Text-to-Speech
[16] Cross-lingual Text-To-Speech Synthesis via Domain Adaptation and Perceptual Similarity Regression in Speaker Space
[17] Cross-lingual Speaker Adaptation using Domain Adaptation and Speaker Consistency Loss for Text-To-Speech Synthesis
[18] Incorporating Cross-speaker Style Transfer for Multi-language Text-to-Speech
[19] End-to-end Text-to-speech for Low-resource Languages by Cross-Lingual Transfer Learning
[20] Building a mixed-lingual neural TTS system with only monolingual data
[21] Multi-Lingual Multi-Speaker Text-to-Speech Synthesis for Voice Cloning with Online Speaker Enrollment
[22] Tone Learning in Low-Resource Bilingual TTS
[23] On Improving Code Mixed Speech Synthesis with Mixlingual Grapheme-to-Phoneme Model
[24] Code-Switched Speech Synthesis Using Bilingual Phonetic Posteriorgram with Only Monolingual Corpora
[25] End-to-End Code-Switching TTS with Cross-Lingual Language Model
[26] Towards Natural Bilingual and Code-Switched Speech Synthesis Based on Mix of Monolingual Recordings and Cross-Lingual Voice Conversion
特别鸣谢
感谢 TCCI 天桥脑科学研究院对于 PaperWeekly 的支持。TCCI 关注大脑探知、大脑功能和大脑健康。
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧




