从Transformer到扩散模型,一文了解基于序列建模的强化学习方法


Transformer与强化学习
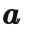 ,奖励(reward) r 和价值(value) v 构成的轨迹(trajectory)
,奖励(reward) r 和价值(value) v 构成的轨迹(trajectory)
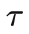 。其中价值目前一般是被用 return-to-go 来替代,可以被看成是一种蒙特卡洛估计(Monte Carlo estimation)。离线数据集就由这一条条轨迹构成。轨迹的产生和环境的动力学模型(dynamics)以及行为策略(behaviour policy)
。其中价值目前一般是被用 return-to-go 来替代,可以被看成是一种蒙特卡洛估计(Monte Carlo estimation)。离线数据集就由这一条条轨迹构成。轨迹的产生和环境的动力学模型(dynamics)以及行为策略(behaviour policy)
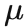 有关。而所谓序列建模,就是要建模产生产生这个序列的概率分布(distribution),或者严格上说是其中的一些条件概率。
有关。而所谓序列建模,就是要建模产生产生这个序列的概率分布(distribution),或者严格上说是其中的一些条件概率。
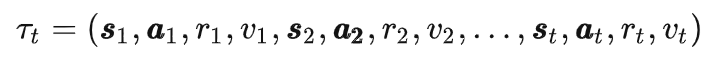

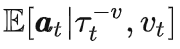 。这种思路很类似于 Upside Down RL[11],不过很有可能背后的直接动机是模仿 GPT2/3 那种根据提示词(prompt) 完成下游任务的做法。这种做法的一个问题是要决定什么是最好的目标价值
。这种思路很类似于 Upside Down RL[11],不过很有可能背后的直接动机是模仿 GPT2/3 那种根据提示词(prompt) 完成下游任务的做法。这种做法的一个问题是要决定什么是最好的目标价值
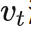 没有一个比较系统化的方法。然而 DT 的作者们发现哪怕将目标价值设为整个数据集中的最高 return,最后 DT 的表现也可以很不错。
没有一个比较系统化的方法。然而 DT 的作者们发现哪怕将目标价值设为整个数据集中的最高 return,最后 DT 的表现也可以很不错。
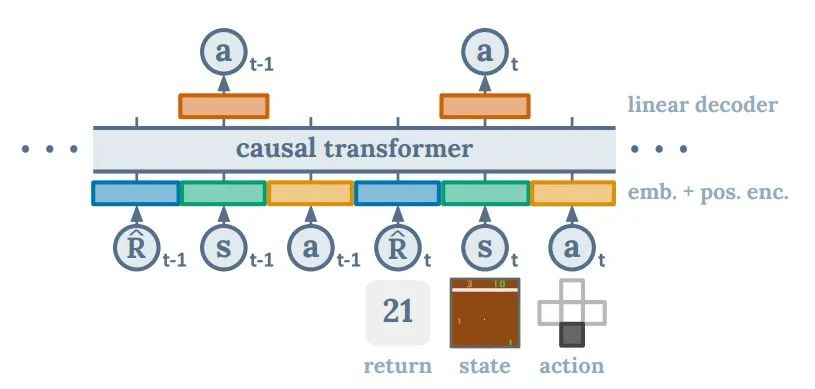

Trajectory Transformer
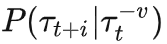 。因为建模了后续序列的分布,TT 其实就成为了一个序列生成模型。通过在生成的序列中寻找拥有更好的估值(value estimation)的序列,TT 就可以输出一个“最优规划”。至于寻找最优序列的方法,TT 用了一种自然语言常用的方法:beam search 的一种变种。基本上就是永远保留已经展开的序列中最优的一部分序列
。因为建模了后续序列的分布,TT 其实就成为了一个序列生成模型。通过在生成的序列中寻找拥有更好的估值(value estimation)的序列,TT 就可以输出一个“最优规划”。至于寻找最优序列的方法,TT 用了一种自然语言常用的方法:beam search 的一种变种。基本上就是永远保留已经展开的序列中最优的一部分序列
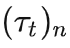 ,然后在它们的基础上寻找下一步的最优序列集
,然后在它们的基础上寻找下一步的最优序列集
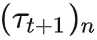 。
。
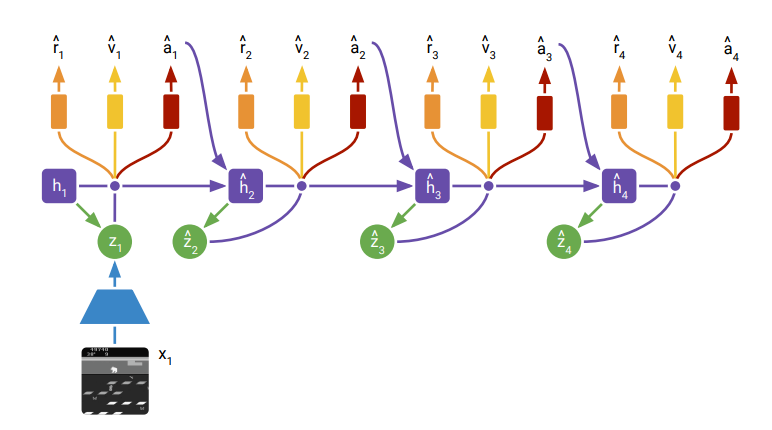
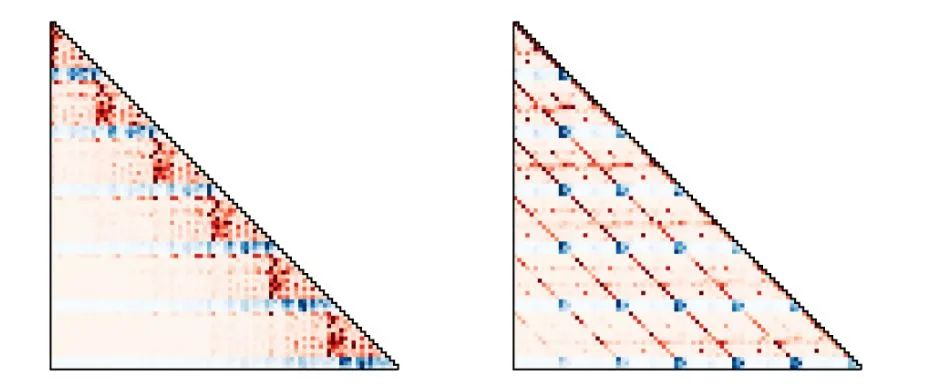
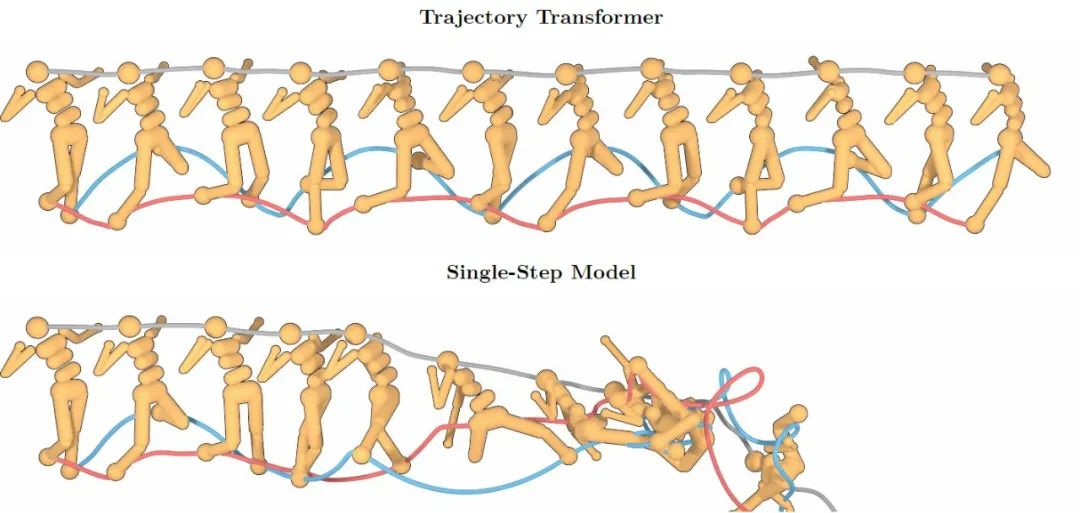
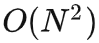 ,这使得从 TT 中采样一个对未来的预测变得非常昂贵。哪怕 100 维以下的任务 TT 也需要数秒甚至数十秒来进行一步决策,这样的模型很难被投入实时的机器人控制或者在线学习之中。
,这使得从 TT 中采样一个对未来的预测变得非常昂贵。哪怕 100 维以下的任务 TT 也需要数秒甚至数十秒来进行一步决策,这样的模型很难被投入实时的机器人控制或者在线学习之中。

Gato
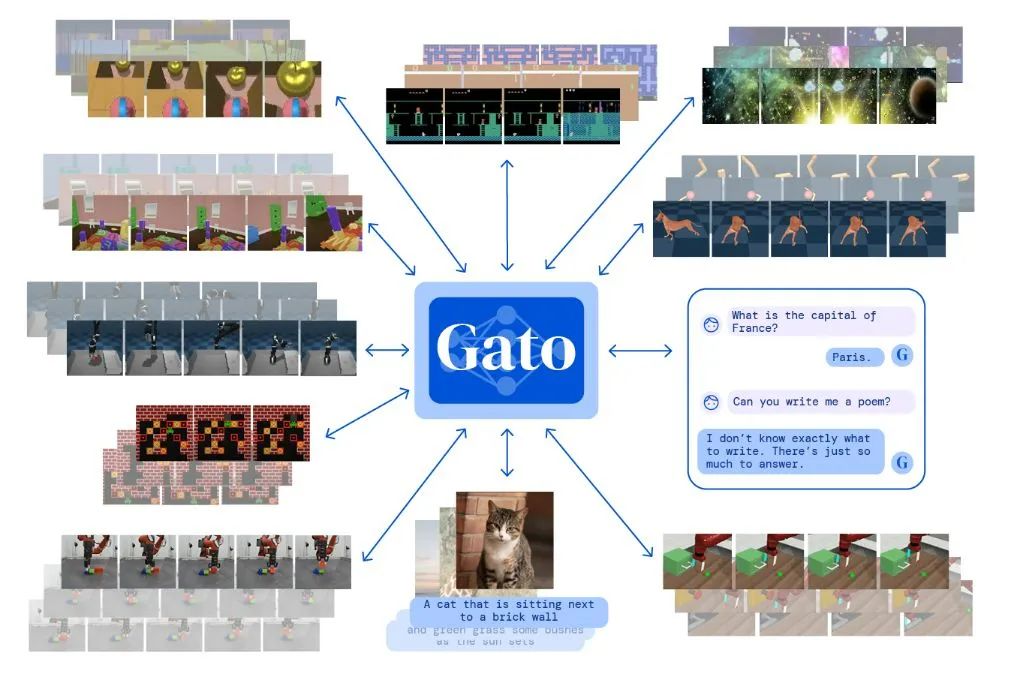

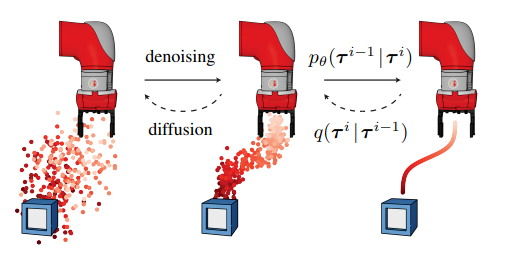

参考文献
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧

登录查看更多
相关内容

强化学习(RL)是机器学习的一个领域,与软件代理应如何在环境中采取行动以最大化累积奖励的概念有关。除了监督学习和非监督学习外,强化学习是三种基本的机器学习范式之一。
强化学习与监督学习的不同之处在于,不需要呈现带标签的输入/输出对,也不需要显式纠正次优动作。相反,重点是在探索(未知领域)和利用(当前知识)之间找到平衡。
该环境通常以马尔可夫决策过程(MDP)的形式陈述,因为针对这种情况的许多强化学习算法都使用动态编程技术。经典动态规划方法和强化学习算法之间的主要区别在于,后者不假设MDP的确切数学模型,并且针对无法采用精确方法的大型MDP。



相关VIP内容
相关资讯