[预训练语言模型专题] Transformer-XL 超长上下文注意力模型

本文为预训练语言模型专题系列第十篇,同时增录之前的两篇为第十一和十二篇。
快速传送门
1-4:[萌芽时代]、[风起云涌]、[文本分类通用技巧] 、 [GPT家族]
5-8:[BERT来临]、[浅析BERT代码]、[ERNIE合集]、[MT-DNN(KD)]
9-12:[Transformer]、[Transformer-XL]、[UniLM]、[Mass-Bart]
感谢清华大学自然语言处理实验室对预训练语言模型架构的梳理,我们将沿此脉络前行,探索预训练语言模型的前沿技术,红框中为已介绍的文章,本期介绍的是Transformer-XL模型,欢迎大家留言讨论交流。
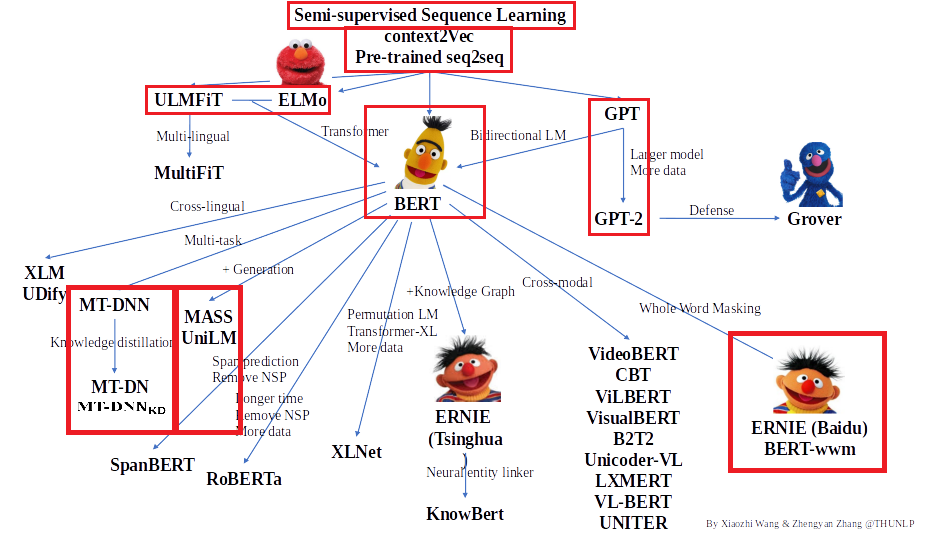
Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context(2019)
本期带来的是卡内基梅隆大学和Google Brain一同撰写的论文Transformer-XL,HuggingFace上也有代码的重现,大家有兴趣可以对照着看。
上期我们了解到Transformer是有能力学习到文本的长时依赖的,但是我们也不能不注意到,Transformer的复杂度是O(n^2)。所以随着文本的加长,Transformer的速度会下降得很快,所以大部分预语言模型的输入长度是有限制的,一般是512,当超过512时,长时文本的依赖Transformer是捕捉不到的。本文就提出了一种网络结构Transformer-XL,它不但可以捕捉文本更长时的依赖,同时可以解决文本被分成定长后产生的上下文碎片问题。据摘要中叙述,Transformer-XL能学习到的文本依赖比RNN长80%,比vanilla Transformer长450%。同时,它比vanilla Transformer在某些条件下evaluation时快了1800倍,而且短文本和长文本上都取得了不错的结果。
Vanilla Transformer Language Models
我们公众号之前也有跟大家分享过阅读理解竞赛的内容,在处理任意长的文本的时候,因为有限的算力和内存,通常的做法是把长文本分割成短片段比如512来进行处理。这样的缺点是,超越512长度的长时依赖就没有了,因为在片段之间,信息不会进行流动,会导致信息的碎片化。另外在模型evaluate的时候,为了利用之前511个token做context来解码,所以segment的区间每次都要滑动一位进行逐位解码,这相比train的时候是相当昂贵的。接下来,我们来介绍下Transformer-XL是如何解决这个问题。
Segment-Level Recurrence with State Reuse
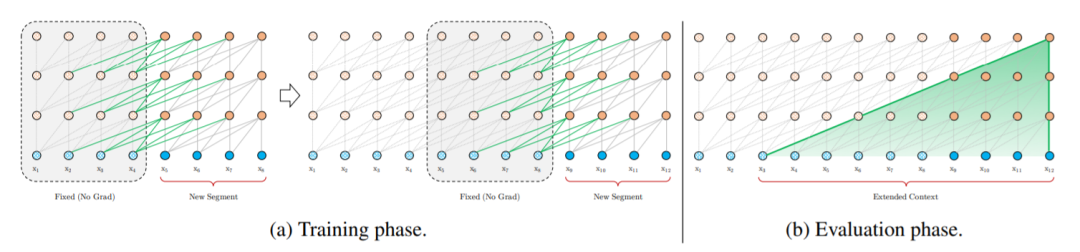
为了解决短片段信息碎片等问题,文章对Transformer结构提出了一种片段重用的循环机制。
在训练的过程中,当处理新的Fragment的时候,之前计算的hidden_state已经被修补存储起来,会作为context信息来进行重用。虽然训练梯度依旧只在一个fragment之间流转,但过去的历史信息是可以实实在在传递到新的fragment训练中。
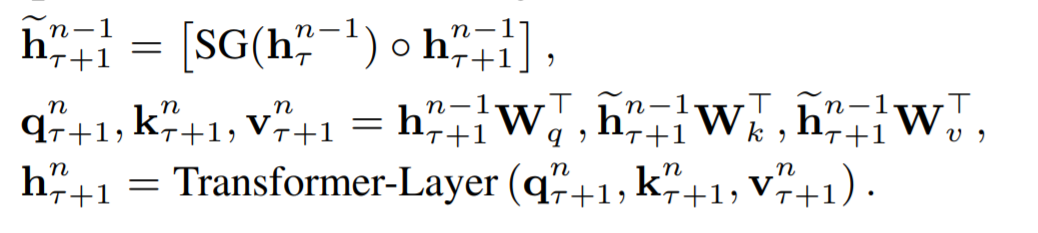
就像上面公式中描述的一样,第一个公式的о代表的是concat,SG代表stop gradient。首先将 τ时刻 n-1层的hidden_state 和 τ+1时刻n-1层的hidden_state拼接形成新的隐层向量。然后经过计算得到当前的q, k, v向量再通过Transformer的层来获得 τ+1时刻第 n 层的 hidden_state。可以看到它和标准Transformer的关键区别是,τ+1时刻的k和v向量是包含有 τ时刻 hidden_state的信息的。如此一来,两个片段之前的上下文信息可以进行有效的传递。
在上述的循环机制中,有一点问题没有解决。就是在重用之前片段的信息时,我们如何保持原来的位置编码信息。之前Transformer中介绍过,在一个片段中,我们会根据token在片段中的位置,将这个位置对应的token的embedding和位置编码相加,因此位置编码是与token位置对应的绝对编码。这样就会遇到问题,当我们重用之前片段的信息时,前一个片段和本片段的相同位置使用的是同样的位置编码,没有办法区分。为了避免这种情况发生,本文提出了一种解决方案。
使用相对位置编码替代绝对位置编码。相比于原来在Embedding的绝对位置一起累加,作者提出在attention中当每两个位置进行attend时,根据他们的相对位置关系,加入对应的位置编码。这样的话,在重用前一段文本的时候,我们可以通过相对距离来进行区分,这样保持了文本的距离和相对位置信息。
首先我们看看标准的Transformer,Q和K的乘积可以分解成以下的四项。E为token的Embedding,U为绝对位置编码。
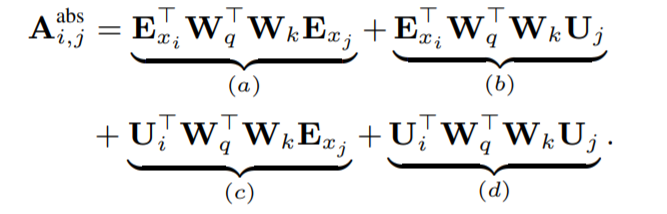
运用相对位置编码的思想,我们首先会把(b)项和(d)项中的Uj替换成相对的位置编码Ri-j。这样的改变可以让原本与j的绝对位置有关的编码部分转为了只与两者之间的相对位置有关,这个相对位置编码和原来的绝对位置编码一样也是不可学习的,只与i-j有关。另外将原来在(c)项和(d)项中一样的Wk,变成了与Embedding对应的Wk,E 以及与位置编码对应的Wk,R。最后,作者引入了两个可学习的变量u和v,用以替代(c)项和(d)项中的绝对位置编码和query矩阵的乘积,因为在这里乘得的query相关向量应该与绝对位置无关。
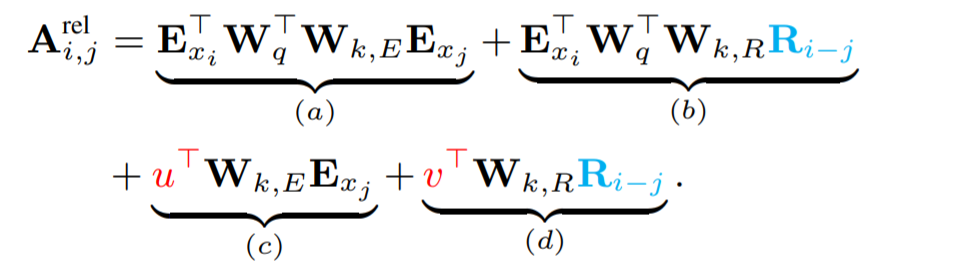
经过了这样的替换,作者认为,每一项都有了一个具体含义,(a)项是content based addressing,也即主要是基于内容的寻址。(b)项是content dependent positional bias ,和内容相关的位置编码偏置。(c)项是global content bias ,全局的内容偏置。(d)项是global positional bias,全局的位置偏置。
最后,结合循环机制和相对位置编码,Transformer-XL一层的完整公式如下所示:

Experiment
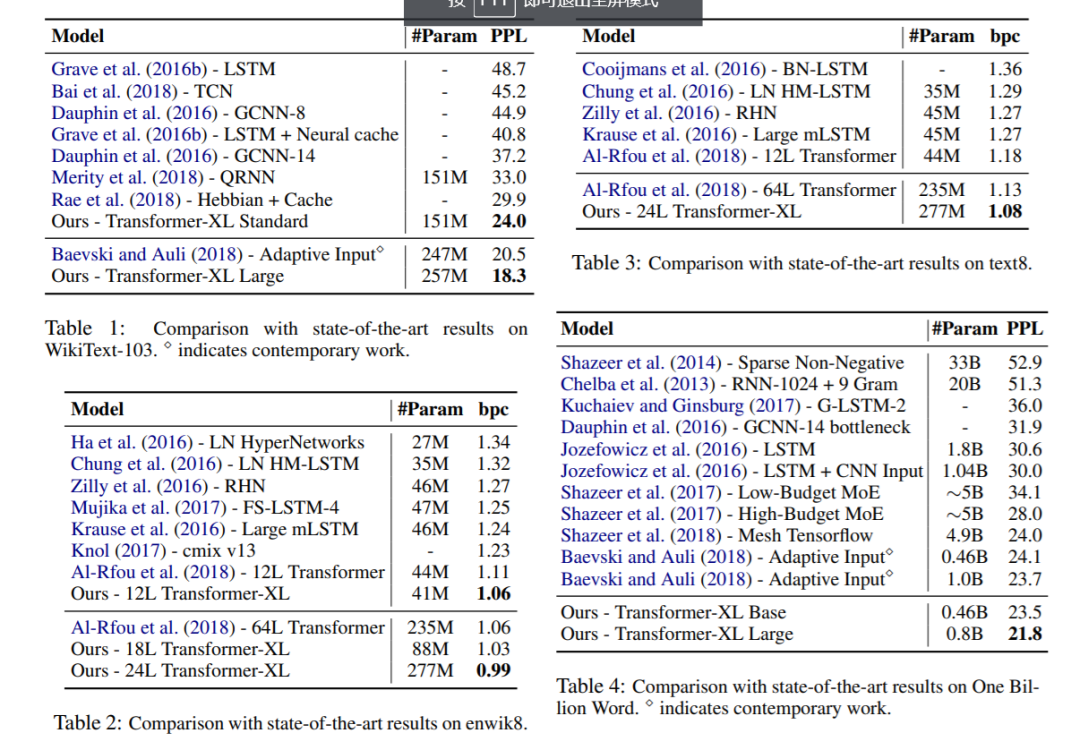
作者在语言模型任务上将Transformer-XL和其他state-of-art的模型进行对比,效果拔群。其中One Billion Word数据集中不包含长时文本的依赖,可以看到效果也是相当好的。
另外,作者做了一系列对比实验,证实了循环机制和相对位置编码的重要性,不再赘述,比如下面这张图是表明在片段长度较长的时候,其和vanilla Transformer的速度的差距。

未完待续
本期的论文就给大家分享到这里,感谢大家的阅读和支持,下期我们会给大家带来其他预训练语言模型的介绍,敬请大家期待!
推荐阅读
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
太赞了!Springer面向公众开放电子书籍,附65本数学、编程、机器学习、深度学习、数据挖掘、数据科学等书籍链接及打包下载
深度学习如何入门?这本“蒲公英书”再适合不过了!豆瓣评分9.5!【文末双彩蛋!】
数学之美中盛赞的 Michael Collins 教授,他的NLP课程要不要收藏?
From Word Embeddings To Document Distances 阅读笔记
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
可解释性论文阅读笔记1-Tree Regularization
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。




