【论文导读】2022年论文导读第三期


论文导读
2022年论文导读第三期(总第四十三期)
目 录
|
1 |
Selective Dependency Aggregation for Action Classification |
|
2 |
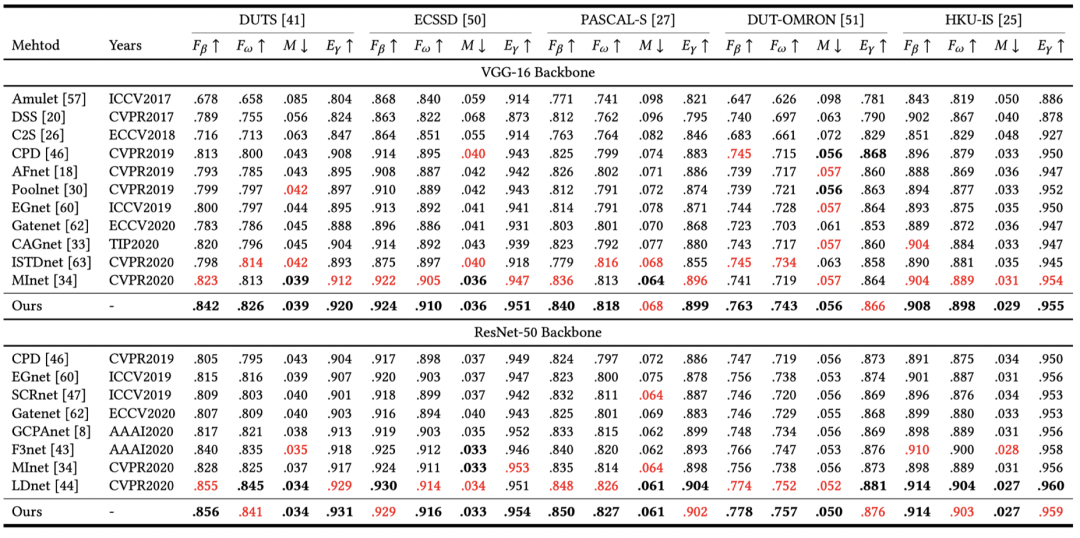
Auto-MSFNet: Search Multi-scale Fusion Network for Salient Object Detection |
|
3 |
TACR-Net: Editing on Deep Video and Voice Portraits |
|
4 |
Depth Quality-Inspired Feature Manipulation for Efficient RGB-D Salient Object Detection |
|
5 |
ZiGAN: Fine-grained Chinese Calligraphy Font Generation via a Few-shot Style Transfer Approach |
01
Selective Dependency Aggregation for Action Classification
用于动作分类的选择性依赖聚合
作者:谭懿1,郝艳宾1,何向南1,尉寅玮2,杨勋2
单位:1中国科学技术大学,2新加坡国立大学
邮箱:
ty133@mail.ustc.edu.cn
haoyanbin@hotmail.com
xiangnanhe@gmail.com
xweiyinwei@hotmail.com
hfutyangxun@gmail.com
论文:
https://dl.acm.org/doi/abs/10.1145/3474085.3475218
代码:https://github.com/ty-97/SDA
1. 引言
视频信号的3D特性增加了视频动作识别以及其他下游任务的难度。困难主要体现在两个方面:(1)视频信号的3D特性使得视频中的动作的范围相对于图片呈数量级上升,由此带来了视频信号的多时空依赖特性。当前的方法大都只关注一种时空依赖,如何组织视频中的时空依赖是视频动作分类中的关键问题;(2)视频模型相对于图像模型一般包含更多的参数而且需要更多计算量,使得模型难以训练。如何减少引入的计算量以及参数是另外一个关键问题。
2. 基于选择性依赖聚合(SDA)的动作识别模型
为了实现对视频信号中多时空依赖的建模,本文使用“特征压缩→依赖激活”的范式。具体来说,视频数据具有时空两个维度,对视频数据的某个维度进行平均池化即可实现视频特征的压缩以获取对应的时空依赖。之后,对另外一个维度进行卷积操作实现依赖的激活。除维度以外,上述特征压缩的尺度也决定了获取的依赖的特性,例如全局与局部特性。通过改变上述过程中池化/卷积核的大小以及维度,我们实现了长距离时空依赖(LST),长距离空间依赖(LS),长距离时间依赖(LT)以及短距离时空(S122)依赖的建模,如图1所示:

图1 多时空依赖建模
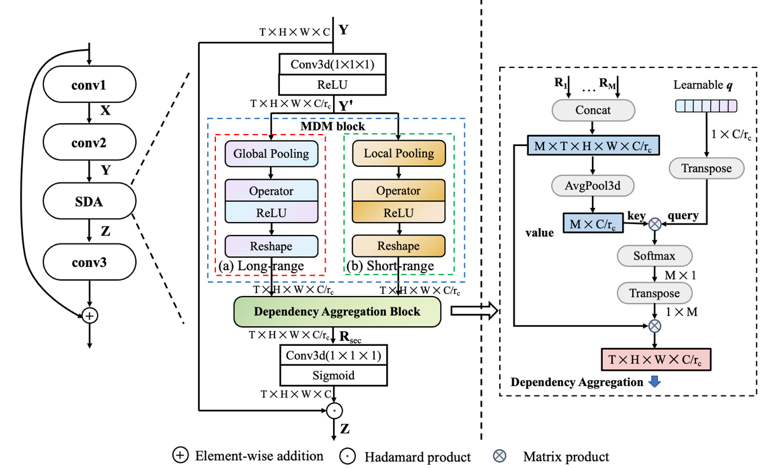
图2 SDA架构图(左)以及基于“询问”架构注意力的依赖聚合(右)
与此同时,为了使模型关注到对特定视频更重要的时空依赖,本文提出了基于“询问架构”的注意力机制,引入一维“询问”向量,通过比较各时空依赖特征与“询问”向量的内积大小自适应地赋予各个时空依赖权重并按权求和。最终获得的依赖特征以门控形式对视频特征进行调整,如图2(左)。
与此同时,我们通过将SDA插入ResNet架构的bottleneck处以及进一步降低SDA的通道数使得SDA仅引入相当有限的参数和计算量。
3. 实验
为了检验SDA对于视频动作分类的有效性,我们将SDA插入TSN以及TSM模型,表1-3分别展示了SDA在Something-Something V1&V2、Dinving48以及Epic-kitchen55上的性能表现。
表 1 SDA与其他SOTA方法在Something-Something V1&V2上的性能比较
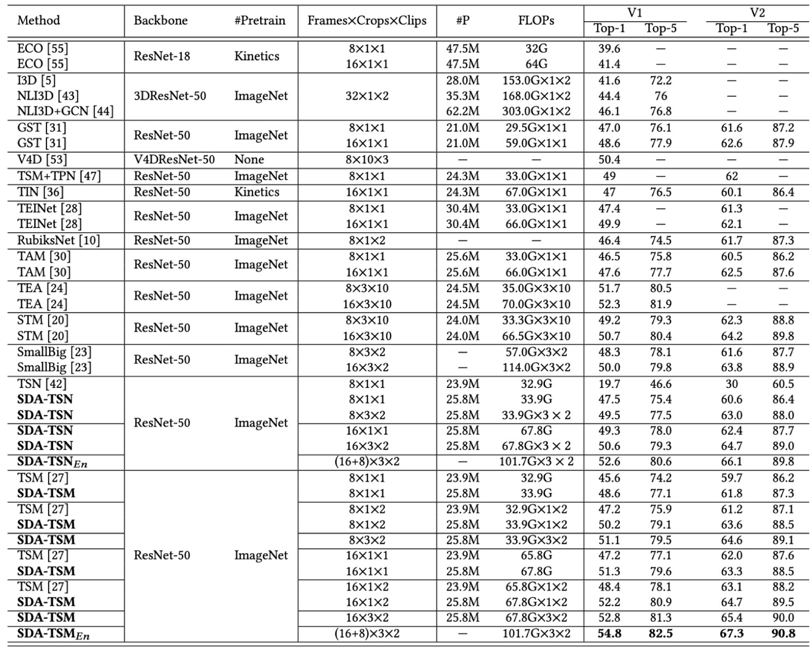
表2 SDA在Diving48上的性能,使用train/val split V2
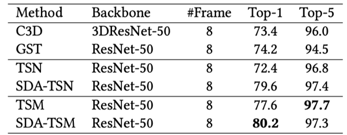
表3 SDA在Epic-kitchen55上的性能
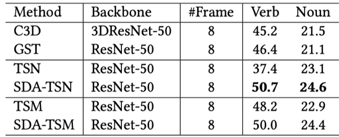
综合来看,SDA在不同骨干网络上均带来了较大性能提升。与此同时,插入了SDA的骨干网络在性能以及效能上相对其他SOTA都展现出了优势。
4. 可视化
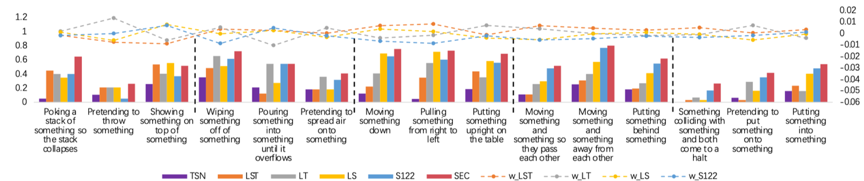
图3 各时空依赖对不同动作类别的有效性展示
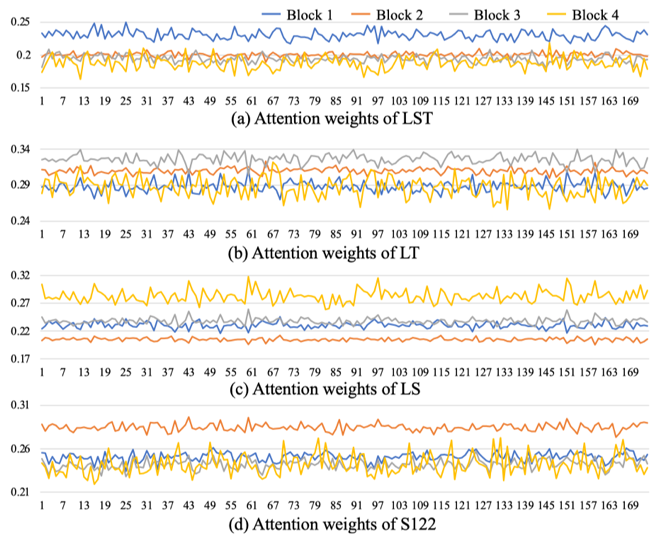
图4 随着网络深度变化,各时空依赖被赋予不同的权重

02
Auto-MSFNet: Search Multi-scale Fusion Network for Salient Object Detection
作者:张淼、刘廷位、朴永日、姚舜禹、卢湖川
单位:大连理工大学
邮箱:
miaozhang@dlut.edu.cn;
tingwei@mail.dlut.edu.cn;
yrpiao@dlut.edu.cn;
ysyfeverfew@mail.dlut.edu.cn;
lhchuan@dlut.edu.cn;
论文:
https://dl.acm.org/doi/abs/10.1145/3474085.3475231
代码:
https://github.com/LiuTingWed/Auto-MSFNet
人类的视觉系统在面对自然场景时具有快速搜索和定位感兴趣目标的能力,这种能力已经成为人们日常生活中处理视觉信息的重要手段,而在计算机视觉领域中,如何从海量的图像和视频数据中快速定位感兴趣目标,显著性检测扮演着及其重要的角色。近年来,基于卷积神经网络的显著性检测方法已经取得了不错的进展。在这些卷积神经网络中,不同层级的特征代表显著性物体不同特点。比如,低级特征往往能表现出显著物体的纹理,细节信息居多;高级语义特征往往能定位显著物体的位置。所以,高效融合高低级特征的互补信息会对显著性检测网络产生积极影响。然而,现有的一些网络在设计融合策略时需要大量专家知识,不断对设计出的策略反复实验试错,消耗了大量的人力物力。本文提出了一种基于神经网络架构搜索的新型多尺度特征融合框架,旨在自动搜索最优策略来引导网络融合多尺度特征。此外,我们提出了一种新的损失函数来减轻低级和高级特征融合时对显著物体边缘的不利影响。
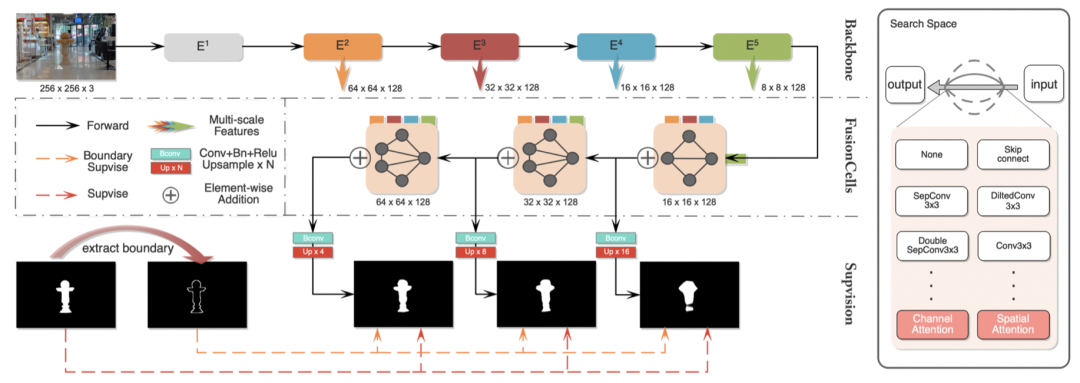
图 1 网络架构
图一展示了网络架构,主要有三部分构成:用于多尺度特征提取的编码器、可搜索的融合细胞和渐进抛光损失函数。如图所示,在提取到多尺度特征后,会将这些特征分别发送给可搜索的融合细胞,最后会使用提出的损失函数进行多阶段的监督以加快收敛速度,最后得到预测图。值得注意的是,在可搜索的细胞中,每条黑色线条代表着一个可搜索的操作。搜索空间如图所示,考虑到显著性物体高低级特征依赖的注意力机制的不同,特别地将空间注意力操作和频道注意力操作加入搜索。
图二展示的是我们提出的可搜索的融合细胞,与普通的细胞不同,我们直接将从编码器拿到多尺度特征作为融合细胞的搜索节点,让网络有更多可以选择的融合策略,进一步提高模型性能,于此同时,我们将该细胞的部分可搜索边进行了裁剪,这样做的目的在于可以将搜索时间从10小时缩短至3小时。
在实验阶段,我们验证了提出的损失函数的有效性,表1和图3分别从数值和可视化的角度验证。我们可以从表1(1)和(5)子实验看出,当使用了该损失函数,数值上有不错的提升。如果对实验细节感兴趣,不妨点开上面论文阅读更多细节。
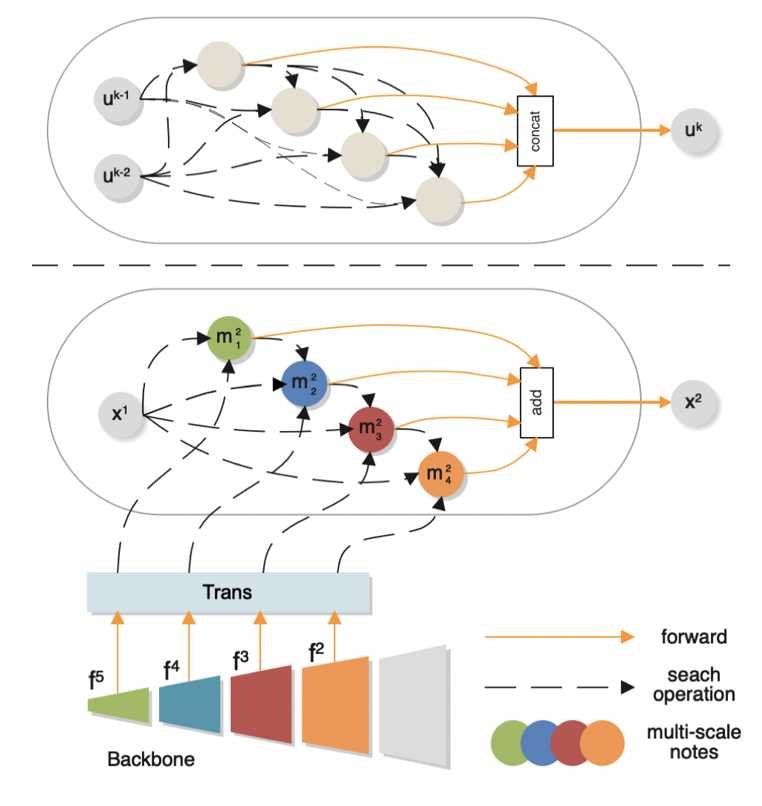
图2 提出的融合细胞和普通的搜索细胞
表1 渐进抛光损失函数消融实验
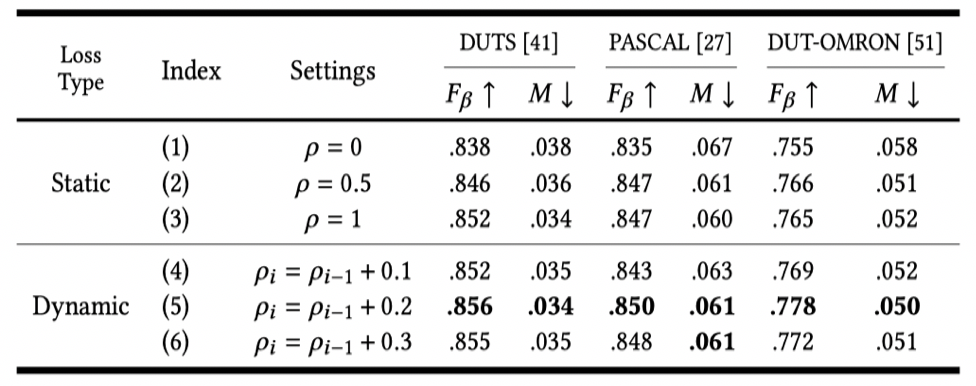
图3 渐进抛光损失函数的可视化对比图
03
TACR-Net: Editing on Deep Video and Voice Portraits
基于音视频联合的动态面部肖像视频编辑
作者:宋路川, 刘斌,殷国君,董潇逸,张宇飞,白家璇
单位:中国科学技术大学 (网络空间安全学院), 美团
邮箱:
slc0826@mail.ustc.edu.cn;
flowice@ustc.edu.cn;
gjyin@mail.ustc.edu.cn;
dlight@mail.ustc.edu.cn;
zhangyufei08@meituan.com;
bjx@mail.ustc.edu.cn.
论文:
https://dl.acm.org/doi/abs/10.1145/3474085.3475196
演示demo:
https://youtu.be/HhgkuKgmmzs
生成具有视听真实感的说话肖像视频是一个具有挑战性的工作,它主要包含有三个方面的难点,1. 声学特征和身份特征没有完全解耦,难以获得全局的语音到面部混合形状的映射函数;2. 由简单的UNET结构组成的面部coarse-to-fine的渲染网络难以补获长时间视频,并且生成的视频通常缺乏时间一致性和空间相关性,导致细节变化的一致性存在缺陷;3)之前的伪造方法都是在帧或者视频级的伪造,缺乏考虑语音上的伪造,包含语音伪造的多媒体内容更具有视听真实感。基于以上存在的三个问题,本文提出了一种新颖的面部音视频内容编辑方法(TACR-Net),它由主要由三个部分构成,语音到面部表情混合参数转换模块,语音音色渲染模块以及视频渲染模块三部分构成。其中语音到面部表情混合参数转换模块可以实现将任意输入的语音提取特征后转化为对应的面部表情混合参数,这里和我们不需要对于不用的身份的视频进行重新训练,音色渲染模块可以将在语音到面部表情混合参数转换模块使用的语音特征同步转化为不同的身份的语音,同时保持说话的内容不变。最后通过视频渲染模块将通过漫反射渲染的粗糙纹理面部合成为具有视觉真实感的面部视频。整体的流程在 图.1 中, 这里我们将英语女主播的视频使用特朗普的语音进行编辑,编辑后的结果是唇形与特朗普语音对齐的女主播视频,于此同时语音也被编辑为特朗普马的语音内容,但是音色依旧保持不变。

图1 英语女主播音视频编辑流程。输入为女主播的原始音视频内容和目标特朗普的语音,输出为转换后的语音和对应的唇形匹配的视频。这里我们使用三维面部形变模型作为中间过渡特征。
对于语音到面部表情混合参数转换模块,本文主要解决的问题在于将任意的语音特征转化为面部表情参数,直接使用语音的语义特征会带来面部表情的抖动,这是由于语音语义特征往往是尖峰信号,直接使用会带来抖动,因此本文使用波形差分特征这样的的连续量作为泰勒展开中的小量对于合成的表情做时序增强。同时语音语义特征和波形差分特征被输入到声码器和解码器中用于音色渲染,这里的声码器和解码器是提前进行预训练的。最后,我们通过粗糙面部 (图.1 Edit Video via Speech中间行) 生成视觉真实面部,这里我们使用的是自回归的生成对抗网络结构,将之前的输出用作当前的输入条件,整体网络流程如图.2所示。
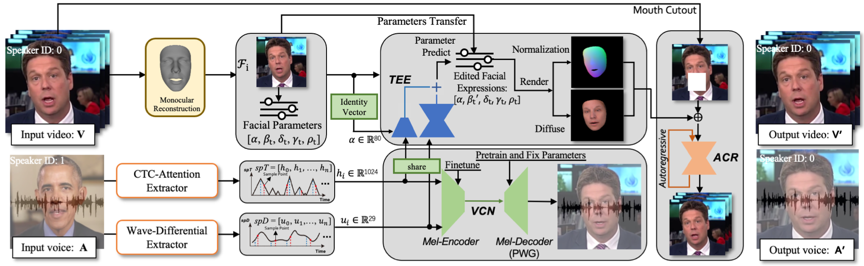
图2 TACR-Net网络整体流程图。其中TEE,VCN和ACR分别对应于语音到面部表情混合参数转换模块,语音音色渲染模块以及视频渲染模块。
我们复现或者遵循官方开源代码重演了其他基于语音的面部合成算法,并且将这些算法和我们的算法进行对比,对比可视化结果如 图.3 所示。从 图.3 中可以发现我们的方法能够合成最为真实的帧级的面部图像。例如,在和当前最为流行的方法 Neural Voice Puppetry: Audio-driven Facial Reenactment x相比,我们的方法在面部表情差异较大时合成的面部更加真实,这是由于我们的方法不需要对于渲染后的面部进行贴合到背景之中,不会产生明显的面部边缘贴合纹理,这种痕迹通常是由于原始表情和编辑后的表情有较大差距导致的。额外的,对于其他的相关方法,我们的方法无论是在背景还是在面部纹理上都有着明显的优势。对于视频级的结果,我们将其添加在视频附件中。

图3 我们的方法和其余的方法进行对比。我们使用红色的尖头以及红色的框放大其他方法和我们的方法之间的差异,对于NVP方法,面部边缘贴合纹理是值得关注的。
04
Depth Quality-Inspired Feature Manipulation for Efficient RGB-D Salient Object Detection
基于深度质量启发特征控制的高效RGB-D显著性物体检测
作者:张文博1,2,季葛鹏3,王卓1,2,傅可人1,2,*,赵启军1,2
单位:1四川大学计算机学院, 2四川大学视觉合成图形图像技术国家级重点实验室, 3阿联酋人工智能研究院
邮箱:
zhangwenbo@stu.scu.edu.cn;
imwangzhuo@stu.scu.edu.cn;
gepengai.ji@gmail.com;
fkrsuper@scu.edu.cn;
qjzhao@scu.edu.cn
论文:
https://dl.acm.org/doi/abs/10.1145/3474085.3475240
代码:
https://github.com/zwbx/DFM-Net
相关介绍:
https://zhuanlan.zhihu.com/p/399406272
*通讯作者
1. 引言
自深度传感器的普及以来,RGB-D显著物体检测(Salient object detection,SOD)任务吸引了越来越多学者的研究兴趣。然而,现有的RGB-D SOD模型难以兼顾效率和精度,不便于移动设备的部署。我们指出深度图质量是影响检测精度的关键因素,基于该观察,提出一种深度图质量启发的特征控制(Depth quality-inspired feature manipulation,DQFM)过程,它可以根据深度图质量过滤深度特征,有效提升模型精度,并且具有轻量高效的特性。
此外,我们还设计了轻量编码器-解码器框架,包括定制深度骨干(Tailored depth backbone,TDB)和两阶段解码器(Two-stage decoder)以进一步提升模型效率。最后,将DQFM嵌入到该框架中构建出名为DFM-Net的高效RGB-D SOD模型。大量实验结果表明,即使与非轻量模型对比,DFM-Net的精度也达到了最先进的水平,同时其在CPU上的推理耗时为140ms(约为现有最快模型速度的2.2倍),模型体积仅有8.5Mb(约为现有最轻量模型的14.9%)。
动机:深度图的不稳定质量是影响RGB-D SOD精度的关键因素,现有多数方法对该问题并没有针对性地进行处理,因为直接对深度图自身质量进行评估是比较困难的。如图1所示,我们观察到高质量的深度图往往能够精准地对齐相应的RGB图像,这一现象被称为“边缘对齐”。可将其作为深度图质量的良好指标,由此我们提出了深度图质量启发的特征控制(Depth Quality-Inspired Feature Manipulation,DQFM)过程。它可以根据深度图质量过滤深度特征,有效提升模型精度,并且具有轻量高效的特性。
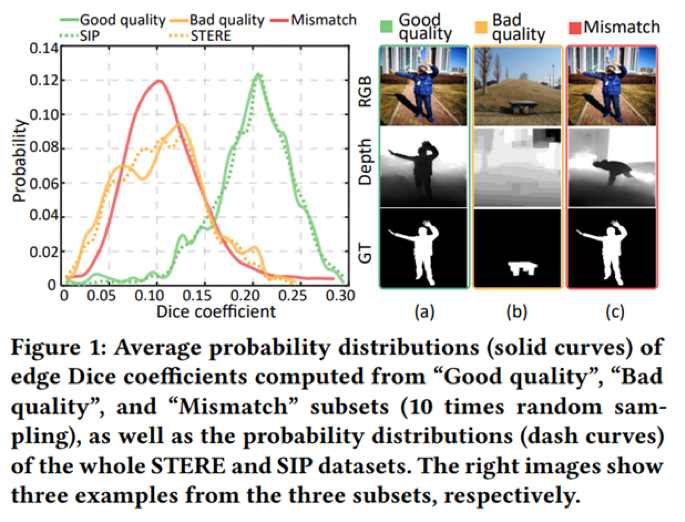
图1 深度图质量评估指标示意图
2. 方法概述
如图2所示,我们构建了一个轻量编码器-解码器框架,包括定制的深度骨干网络和两阶段解码器以进一步提升模型效率,并将DQFM作为门控嵌入到该框架以提升其精度,得到高效RGB-D SOD模型。
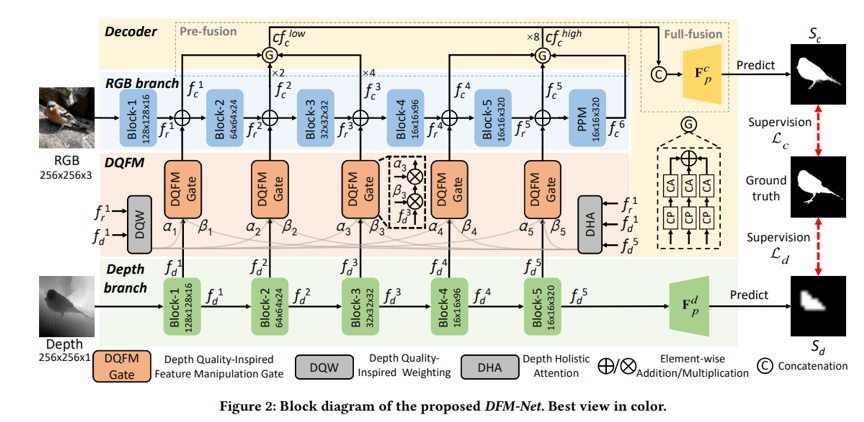
图2 DFM-Net 模型结构图
深度图质量启发的特征控制(DQFM)
DQFM非常高效,其体积仅为0.05Mb。它包含深度图质量启发加权(Depth quality-inspired Weighting,DQW)和深度整体注意力(Depth holistic attention,DHA)。如果深度图质量不佳,就赋予其特征一个较低的加权系数,有效地避免噪声和误导性的深度图特征,以此来提升检测精度。DQW预测的加权项是一个标量,决定了“多少比例”的深度特征的参与融合, DHA预测的加权项是一个空间注意图,决定关注深度特征的“哪些区域”,通过与深度特征进行连续相乘实现特征控制。下方的可视化图3-4分别展示了DQW、DHA的表现。

图3 DQW(深度质量启发加权)可视化图

图4 DHA(深度整体注意力图)可视化图
3. 实验结果
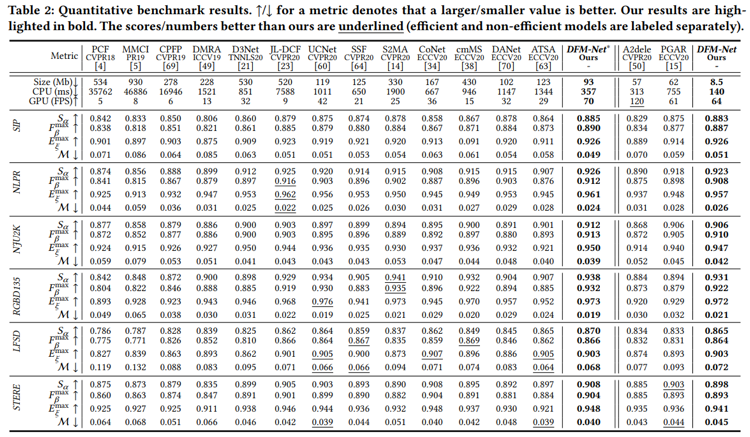
本文方法与15个先进方法标准评估结果对比如表1所示。本文方法在模型大小和CPU推理速度方面都取得了新的记录,其精度超越现有轻量级方法,即使是与非轻量方法比较,其精度也具有相当的竞争力。
表1 标准评估结果
模型性能可视化结果对比如图5所示(其中圆形图例面积表示模型体积)。本文方法在推理速度、模型大小、准确率上的表现均超过了以JL-DCF为代表的先进方法,特别是在模型体积和推理速度方面与现有方法拉开了较大的差距。
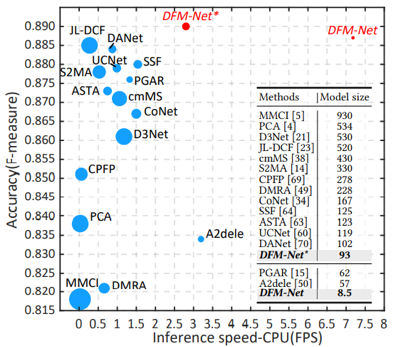
图5 模型性能可视化结果
05
ZiGAN: Fine-grained Chinese Calligraphy Font Generation via a Few-shot Style Transfer Approach
基于少量数据的字体风格迁移
作者:温琦1,李爽2,韩秉峰2,袁燚1*
单位:1网易伏羲人工智能实验室、2北京理工大学
邮箱:
wenqijay@gmail.com
shuangli@bit.edu.cn
bfhan@bit.edu.cn
yuanyi@corp.netease.com
论文:
https://dl.acm.org/doi/abs/10.1145/3474085.3475225
*通讯作者
与英文字母相比,由于汉字数量众多以及汉字字形相当复杂,对汉字的风格迁移是一个非常具有挑战性的问题。同时,书法大师的笔画常常比较不规则,并且在现实场景中很难获得。最近几年,几种基于生成对抗网络的字体生成方法被提出,但其中一些方法需要大量的参考数据,而另一些则需要繁琐的预处理步骤。在本文中,我们提出了一个简单但功能强大的端到端中文书法字体生成框架 ZiGAN,该框架不需要任何手动操作或冗余的预处理,只需要少量的目标风格字符作为参考即可生成精细的目标风格字体。具体来说,ZiGAN利用配对的样本来获得不同风格的字体结构之间的相关性。同时,利用未配对的样本来对齐不同风格字体的特征分布,以获取更多风格知识并加强对字符内容的粗粒度理解。通过这样做,只需要少量的目标汉字就可以生成高质量的的风格迁移汉字。

图1 汉字风格迁移。第一行为输入的宋体,第二行为生成的瘦金体
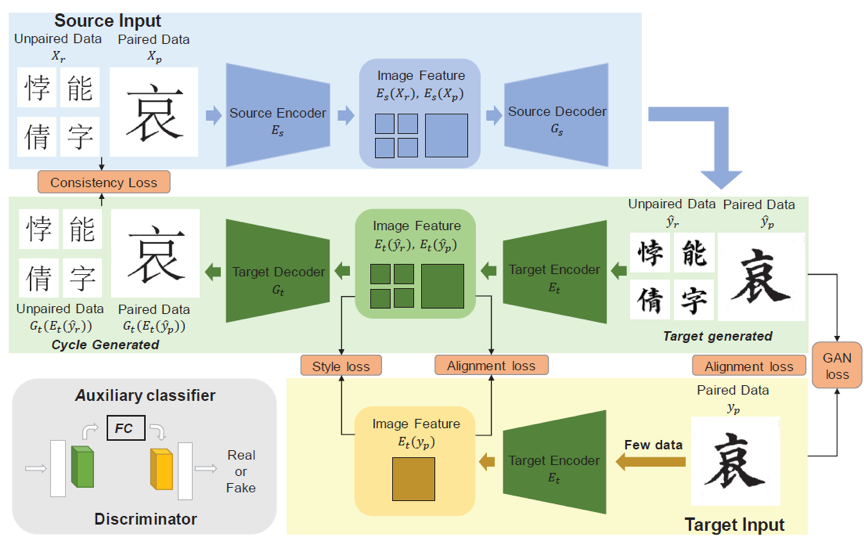
图2 网络结构
图1展示了ZiGAN将宋体迁移为瘦金体。ZiGAN的网络结构展示在图2中。首先,我们基于循环的思想,提出了一种端到端网络。该网络不仅只需要少量的目标风格字符作为参考,且可以快速适应新的任务。其次,我们创新性地利用了不配对的字符的信息以进行学习。虽然我们只能获得少量的目标风格的字体,但是我们可以轻易地获得大量的源字体,而在源字体中仍然含有非常丰富的结构知识。在实验中我们使用宋体作为源风格字体。在训练过程中,我们使用配对的字来学习不同风格的字体间精细的结构关联。同时,使用了最大均值差异(MMD)以在特征维度上最大限度地学习不配对的字的结构信息。
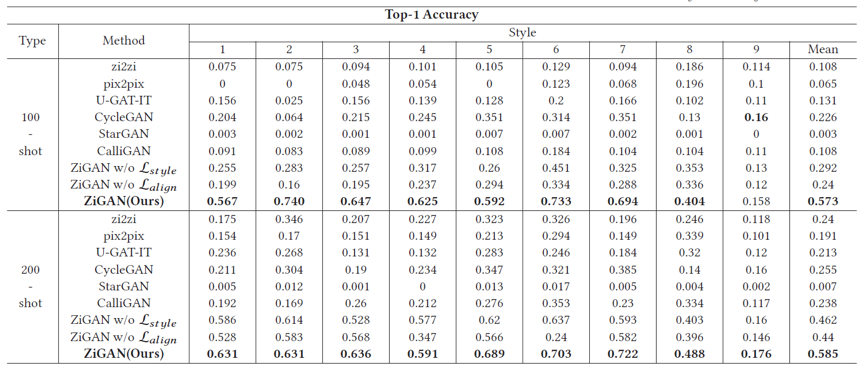
我们从风格和形态两个层面来定量评价ZiGAN的结果。如表1和表2所示,结果表明ZiGAN在少量数据的字体风格迁移领域,和其他的先进方法相比取得了更好的效果。
表1 九种不同风格的字体数据集上的IOU指标
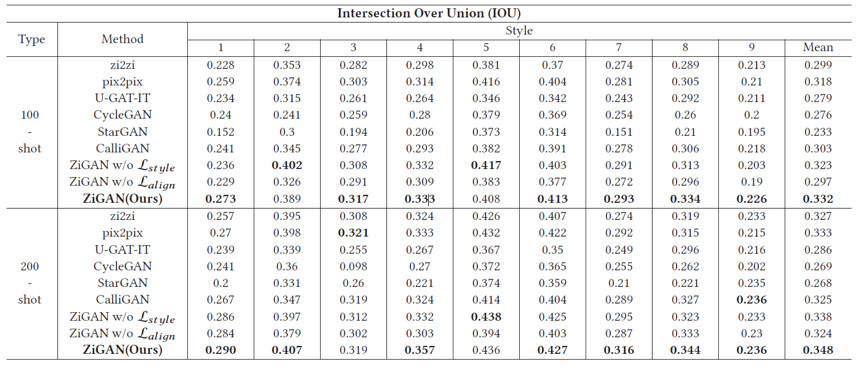
表2 九种不同风格的字体数据集上的分类准确率指标

编辑人:桑基韬、聂礼强
专委会责任副主任:徐常胜

