【论文导读】2022年论文导读第一期


论文导读
2022年论文导读第一期(总第四十一期)
目 录
|
1 |
Viewing From Frequency Domain: A DCT-based Information Enhancement Network for Video Person Re-Identification |
|
2 |
Learning Fine-Grained Motion Embedding for Landscape Animation |
|
3 |
SSFlow:Style-guided Neural Spline Flows for Face Image Manipulation |
|
4 |
DC-GNet: Deep Mesh Relation Capturing Graph Convolution Network for 3D Human Shape Reconstruction |
|
5 |
Towards Multiple Black-boxes Attack via Adversarial Example Generation Network |
|
6 |
Beyond OCR + VQA: Involving OCR into the Flow for Robust and Accurate TextVQA |
|
7 |
DSSL: Deep Surroundings-person Separation Learning for Text-based Person Retrieval |
01
Viewing From Frequency Domain: A DCT-based Information Enhancement Network for Video Person Re-Identification
基于离散余弦变换的视频行人重识别信息增强网络
作者:刘良辰1,杨曦*1,王楠楠1,高新波2
单位:1西安电子科技大学,2重庆邮电大学
邮箱:
lcliu79xidian@gmail.com
yangx@xidian.edu.cn
nnwang@xidian.edu.cn
gaoxb@cqupt.edu.cn
论文:
https://dl.acm.org/doi/pdf/10.1145/3474085.3475566
*通讯作者
行人重识别技术旨在利用计算机视觉技术在不同摄像头下检索特定的监控行人图像或视频,对辅助刑侦破案、实现高危人群联动监测等具有重要的研究意义。相较于传统的图像行人重识别,视频行人重识别利用了视频数据中丰富的时空信息,因而能够进一步提升检索精度。然而,现有的视频行人重识别方法没有充分挖掘视频数据中的信息,从而限制了模型的视频表征能力。本文认为视频中每一帧的判别性信息与整个序列的共享信息对视频表征来说均具有重要作用。

图1 共享信息和判别信息示意图
为解决上述问题,本文引入离散余弦变换,将问题转化到频域空间。结合频域分析理论,低频信息往往能够表征视频序列的共享特征,而高频信息更倾向于描述视频中每一帧的特有信息。本文方法利用离散余弦变换的最低频分量与平均池化结果等价这一特性,对backbone输出的特征图进行2D离散余弦变换,从而建立起两种信息之间的数学关联。同时,由于频域特征本身具有离散性,从而有效避免了传统空间特征划分存在的空间不对齐、空间关系破坏等弊端。

图2 传统空间特征划分弊端示意图
在上述理论基础上,本文方法为视频行人重识别任务设计了一种基于离散余弦变换的信息增强网络(DCT-IEN)。整个网络由两个分支组成:频域选择分支(FSM)和最低频分量分支(LFEM),分别学习每帧图像中的判别性信息和序列级的共享信息。频率选择分支将backbone提取出的特征图进行DCT变换,在频谱上进行划分,并利用二维attention map对判别性信息进行增强。最低频分量分支使用DCT最低频分量表示共享信息,同时利用正则化项拉近不同帧之间的特征图距离,实现共享信息的增强。通过同时利用两种信息,该网络实现了更完整的视频表征。
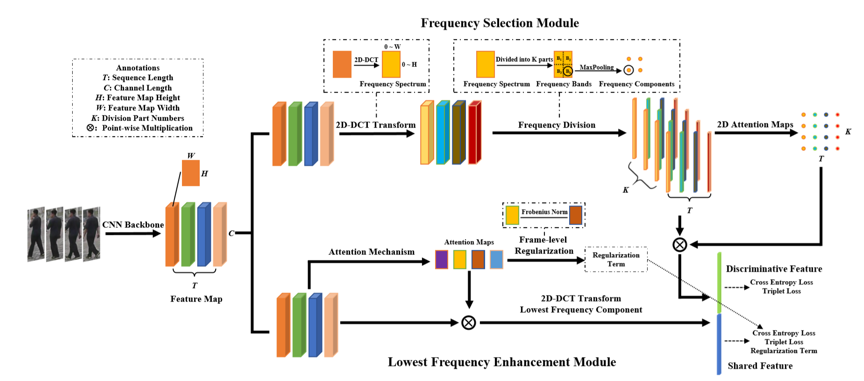
图3 基于离散余弦变换的信息增强网络的结构图
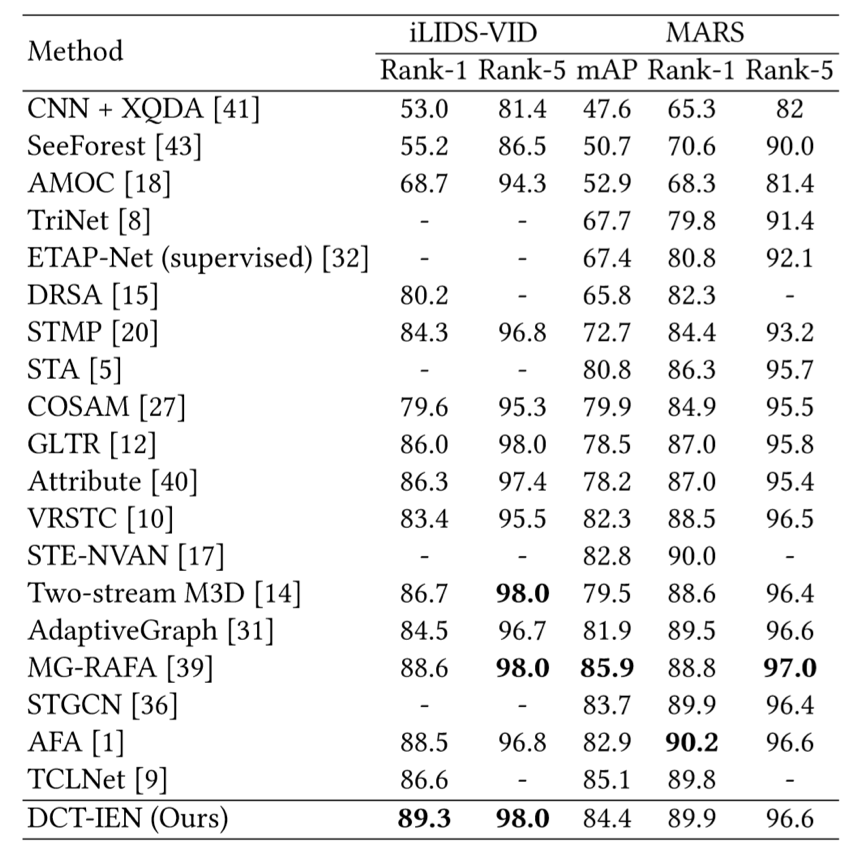
表1给出了本文方法在MARS数据集上的消融实验,验证了判别信息和共享信息对视频表征均具有重要意义的猜想。表2给出了本文网络结构的模型参数量,可以发现相比于基线模型,本文方法仅仅增加了0.04M的参数,实现了效率和性能的良好平衡。如图3所示,将DCT-IEN与前沿方法在MARS和iLIDS-VID数据集上进行比较,结果表明本文方法均达到SOTA性能。
表1 消融实验
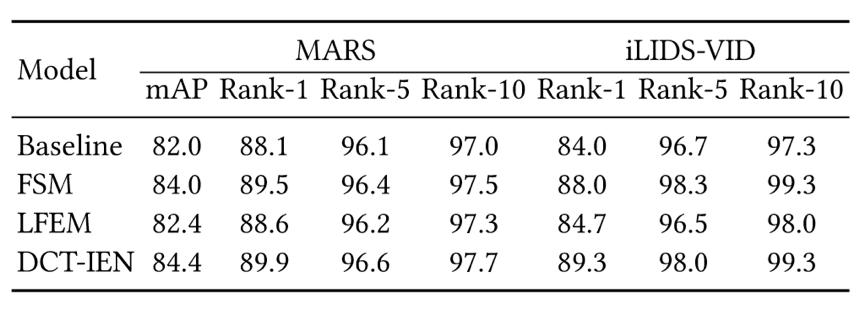
表2 模型参数量对比实验
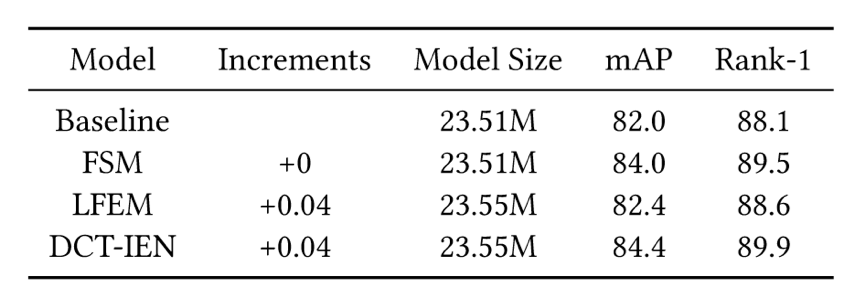
表3 前沿方法对比实验

02
Learning Fine-Grained Motion Embedding for Landscape Animation
用于风景图片动画化的细粒度运动信息学习
作者:薛宏伟1、刘蓓2、杨欢2、傅建龙2、李厚强1、罗杰波3
单位:1中国科学技术大学、2微软亚洲研究院、3罗彻斯特大学
邮箱:
gh051120@mail.ustc.edu.cn,
bei.liu@microsoft.com,
huayan@microsoft.com,
jianf@microsoft.com,
lihq@ustc.edu.cn,
jluo@cs.rochester.edu
论文:
https://dl.acm.org/doi/10.1145/3474085.3475421
图像动画化是指以自动的方式从静态图像生成动态视频。与静态图像相比,动态视频更加生动并具有表现力,因此可以提升用户的使用体验。在已有的工作中,对视频中运动信息学习仍不充分,会导致生成不真实的动态效果,如图一。本文专注于通过更加细粒度的学习运动空间,来生成更加真实的视频。

图1 与已有方法生成的视频比较,选取一张生成的视频帧为例。右下角是可视化光流用来描述视频的运动信息。
如图一中AL的结果,显式地使用光流作为运动信息的表达使得运动和内容学习可以分开进行。然而由于光流本身缺乏语义性,很难直接从光流学到与图片的对应关系。为解决上述问题,本文使用语义信息为引导,将运动信息嵌入到不同的语义空间,得到更加细粒度的运动表示,从而生成具有更加真实动态效果的视频。如图二所示,模型的编码器使用部分卷积 (partial convolution) 来根据不同的语义分割图对整张光流进行嵌入学习,得到细粒度表达。再根据输入图片的语义分割图重新排列这种表达。模型的解码器根据以上信息生成下一帧的光流预测,从而循环地生成整段视频。
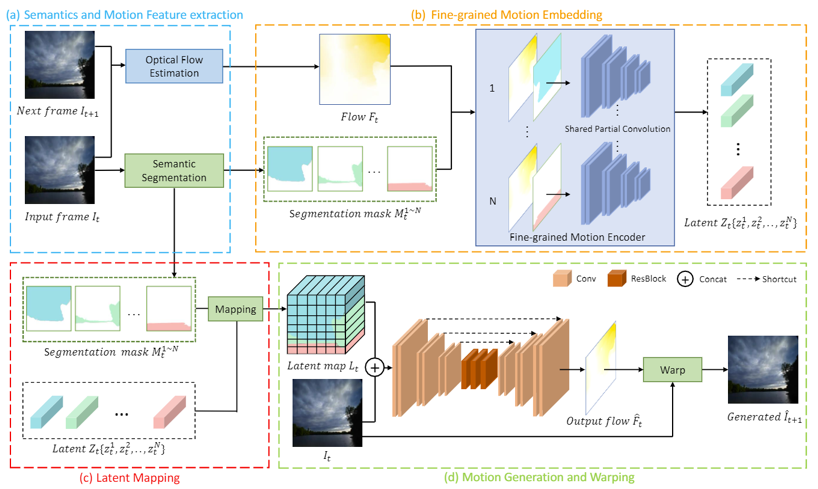
图2 模型整体框架图
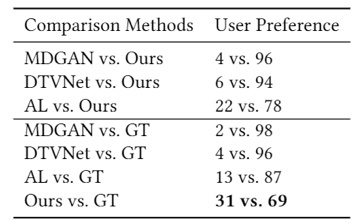
同时我们也基于Flickr收集了一个大规模的延时视频数据集 Time-lapse-D。该数据集是至今为止最大的、具有最多种类的延时视频数据集。在一系列客观和主观评测指标上,我们的模型都取得了至今为止最好的效果:图三、四。图三中我们同时选取图片和视频的评测用来衡量生成视频的帧和运动。图四中我们设计了一个用户评价来测量人类视觉上的主观感受。
表1 客观指标评测比较
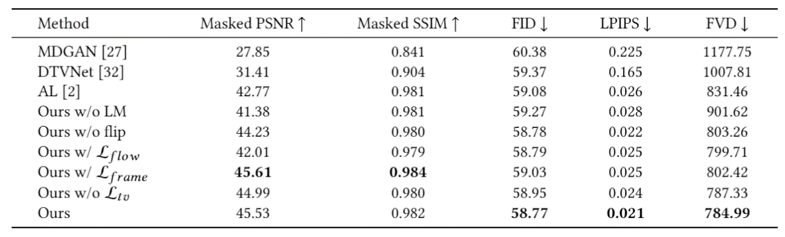
表2 主观评测指标比较
同时,由于我们的模型可以对不同语义区域的运动分别进行学习,这样可以使用不同的参考视频来对生成的视频进行控制。如图五,以水和天空为例,选取不同的参考可以使得生成的视频具有不同的动态效果。
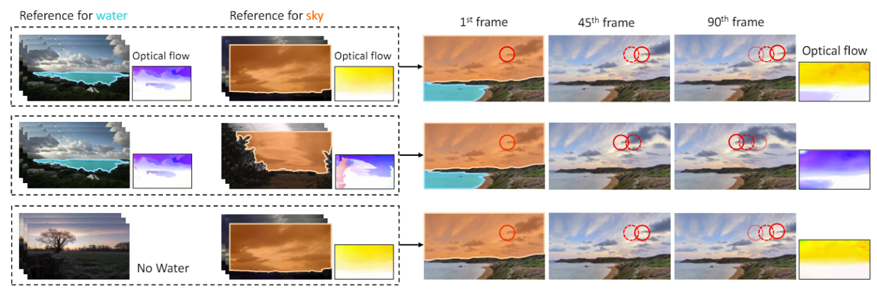
图3 不同参考视频对生成视频的控制
03
SSFlow:Style-guided Neural Spline Flows for Face Image Manipulation
作者:梁汉帮1,2,3,侯贤旭1,2,3,沈琳琳1,2,3,*
单位:
1深圳大学计算机学院计算机视觉研究所,
2深圳市人工智能与服务机器人研究院,
3广东省智能信息处理实验室
邮箱:
lianghanbang2019@email.szu.edu.cn,
hxianxu@gmail.com,
llshen@szu.edu.cn
论文:
https://dl.acm.org/doi/abs/10.1145/3474085.3475454
*通讯作者
基于预训练生成对抗网络的生成器进行人脸图像编辑的主要难点在于如何更准确地从生成对抗网络的先验分布去解耦出所需人脸语义属性。以基于预训练StyleGAN实现编辑的模型或方法为例,目前用无监督手段的方法缺点主要在于解耦效果差和需要探索所解耦出的元素所对应的语义信息;用有监督手段的方法则面临着灵活性问题,如一种标签需训练一个模型或者编辑图像时需要同事提供图像对应的额外信息如属性标签等。
本文提出一种基于Conditional Normalizing Flows的模型SSFlow,用其去拟合StyleGAN W空间的条件分布。我们对StyleGAN W空间进行语义属性解耦,结合人脸图像对应在W空间下的隐变量w,与人脸图像对应的任意语义属性编辑,如性别、年龄、眼镜等,作为训练数据,并结合Neural Spline Flows提出适用于w向量的网络,其中包括增添非线性和向量元素位置打乱的1x1分块可逆卷积,和使得将w转化成flows先验z过程更依赖语义属性条件c的转换函数(生成Spline Flows的参数),去拟合w向量以给定条件c下的条件分布。以极大似然估计作为损失训练最终得到一个可逆神经网络的模型,如图1所示,通过将w和对应属性标签c进行前向编码得到z,再通过编辑属性标签c中任意语义属性所对应的维度,最后将z和编辑侯的标签通过模型逆向过程得到编辑后的w向量。编辑后的向量通过StyleGAN生成器即为对应编辑后的人脸图像,被编辑的内容与属性标签被修改的维度有关。
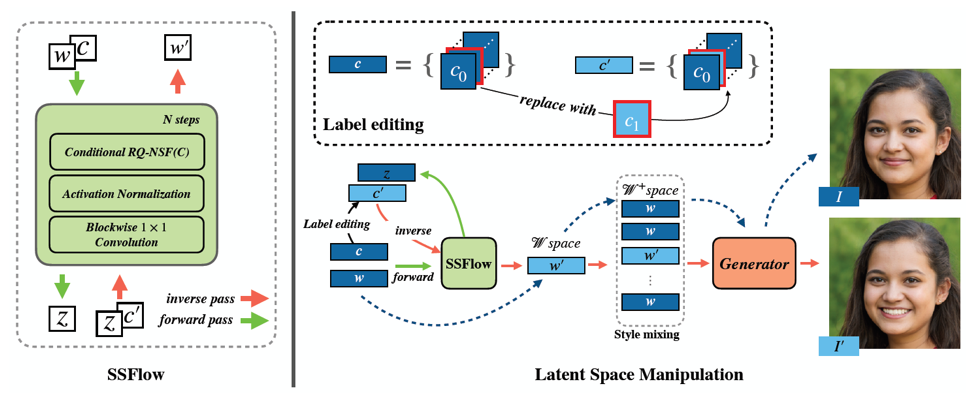
图1 人脸编辑流程
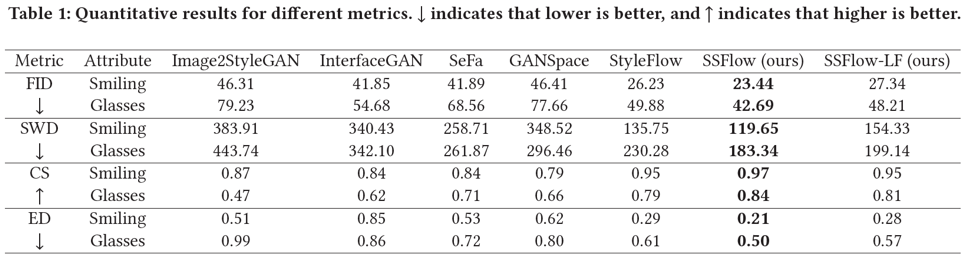
因为上述过程对一张人脸图像编辑需要提供该人脸的全部对应属性标签,对使用时不便利且不便于编辑无法提取到属性标签的图片,如艺术画人脸,且基于对我们模型编辑某种语义后的向量观察发现语义信息能被提取成方向向量,因此本文提出一种基于训练好的SSFlow,提取出每种语义属性对应的方向向量,使得编辑只需要让w向量沿着方向向量上移动即可实现。部分实验结果如图2所示。如表1所示我们在FFHQ数据集上也表现出更好的效果。

图2 FFHQ图像和跨域图片编辑效果
表1 FFHQ数据集上FID表现与现有方法对比
04
DC-GNet: Deep Mesh Relation Capturing Graph Convolution Network for 3D Human Shape Reconstruction
作者:周世豪1,江梦茜1,蔡珊珊1,雷蕴奇1
单位:1厦门大学
邮箱:
shzhou@stu.xmu.edu.cn,
jiangmengxi@stu.xmu.edu.cn,
sscai@stu.xmu.edu.cn,
yqlei@xmu.edu.cn
论文:
https://dl.acm.org/doi/10.1145/3474085.3475242
补充材料:
https://dl.acm.org/action/downloadSupplement?doi=10.1145%2F3474085.3475242&file=mfp0438aux.zip
三维人体重建是计算机视觉领域中一项重要且具有挑战性的任务,也是其他诸如虚拟现实、运动重定向等相关技术的基础。现有的三维人体重建方法通常都直接或间接的依赖于一个预定义的邻接矩阵来描述人体各节点间的正相关关系,因而忽视了三维人体中的深层拓扑关系,如图1(a)所示。此外,受益于室内数据集的规模不断扩展,现有方法已在受限实验室环境中实现了明显的性能提升,但在真实场景下仍然难以恢复出精确的三维人体。
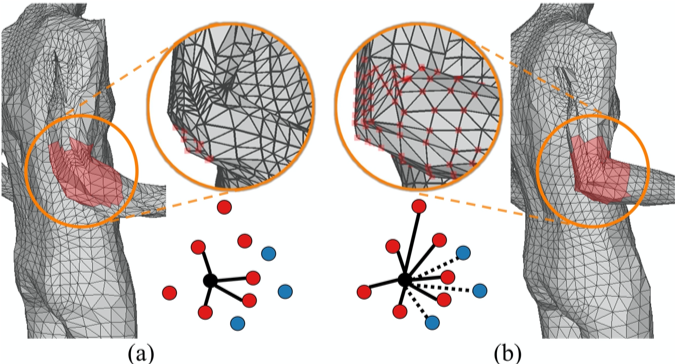
图1 不同的局部结构推理策略
针对上述问题,本文提出了一个深层网格关系捕捉图卷积神经网络(Deep Mesh Relation Capturing Graph Convolution Network, DC-GNet)。首先,通过引入一个自适应邻接矩阵来同时学习人体节点间的正负相关的关系。通过学习人体内部节点间更细微的关系,模型从而习得捕捉复杂的人体局部结构的能力,如图1(b)所示。此外,提出了一个形状补全任务,即人为的在人体模型的表面上制造孔洞。而为了恢复缺失的信息,迫使网络模型从现有存在的邻接节点中推理必要的信息,如图2所示。户外环境下存在大量的遮挡情况,而大多数现有的室内数据集则缺少必要的遮挡样例。基于这样的数据集训练得到的模型通常会遭遇急剧的性能下降,而基于该形状补全任务训练的模型则能够从现存富有的室内数据库中习得人体遮挡的先验信息,从而很好的处理自然环境中的遮挡情况。该方法的流程示意图如图3所示。
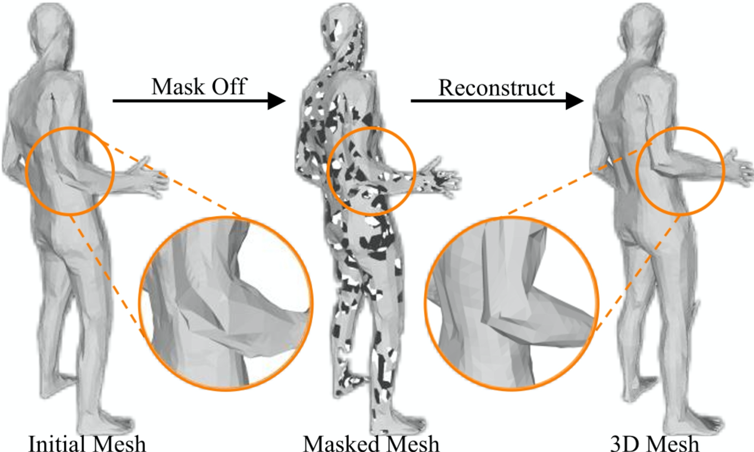
图2 不同的局部结构推理策略
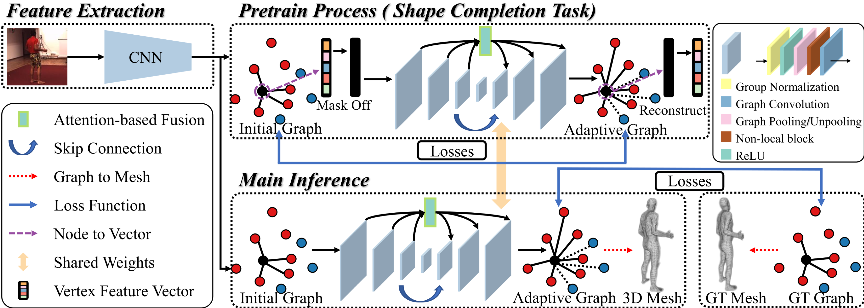
图3 DC-GNet网络流程图
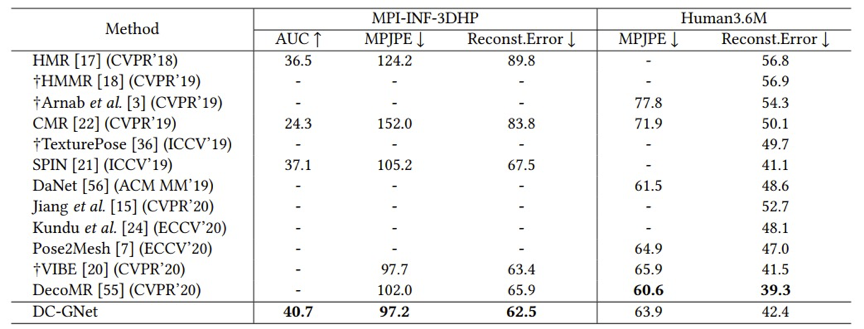
在公开数据集MPI-INF-3DHP与Human3.6M上的实验结果如表1所示。相比现有的SOTA方法,DC-GNet方法在室内数据集Human3.6M上取的有竞争性的结果,并在户外数据集MPI-INF-3DHP上取得最佳结果。
表1 DC-GNet与其他方法的精度对比
同时,与现有算法进行了定性分析对比。DC-GNet不仅在室内环境能生成精确的人体模型,在室外环境也能重建出稳定的结果,如图4与图5所示。

图4 与现有节点回归方法进行比较

图5 与现有参数回归方法进行比较
05
Towards Multiple Black-boxes Attack via Adversarial Example Generation Network
作者:段明星1,李肯立1,谢凌曦2,田奇2,肖斌3
单位:1湖南大学,2华为技术有限公司,3香港理工大学
邮箱:
duanmingxing@hnu.edu.cn,
lkl@hnu.edu.cn,
198808xc@gmail.com
tian.qi1@huawei.com
b.xiao@polyu.edu.hk
论文:
https://dl.acm.org/doi/abs/10.1145/3474085.3475542
深度学习模型极易受到攻击,因此当前很多研究设计攻击算法去攻击这些目标模型,从而测试它们的鲁棒性能,进而人们根据这些反馈结果来提高这些模型的防御能力。当前对抗攻击主要分为白盒攻击和黑盒攻击,白盒攻击算法较为成熟,而黑盒攻击依旧充满挑战。如图1所示,当前所有黑盒攻击算法都是针对单个目标,即一个算法对应一个攻击目标,当有多个攻击目标时候,需要训练多个攻击算法系统,这需要大量计算开销和时间开销。而实际应用中,有许多黑盒系统是有相同的输入,即训练集相同而输出不同;也有些黑盒系统输入是同类别数据集,而输出是相同的分布。我们可以看出这些模型有相似的地方,是否存在这样攻击算法,利用这些共性对多个具有上述相似功能的目标系统发动攻击。
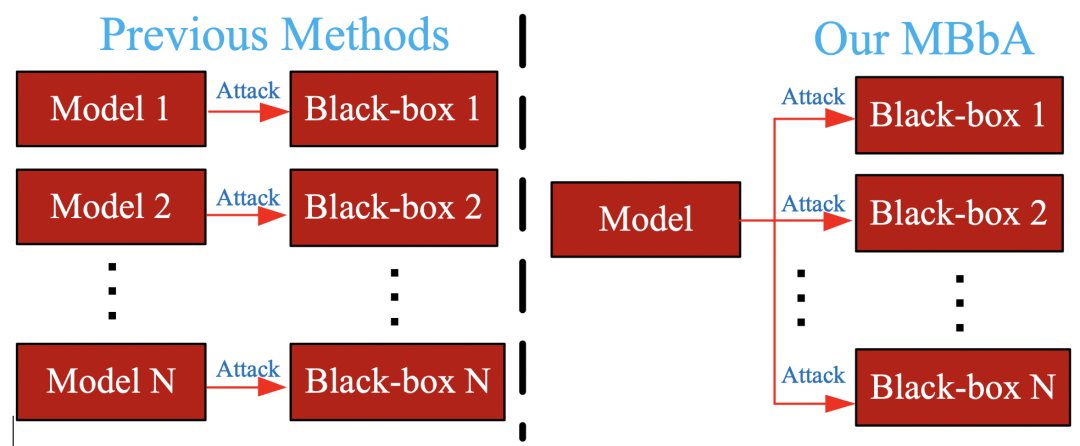
图1 当前黑盒攻击算法和我们提出的算法
为解决上述困惑,本文提出多黑盒攻击算法简称为MBbA。如图2所示,该方法主要针对两种场景:相同训练集(SI)和相同输出(SO)。MBbA首先采取多个编码器将输入图像和攻击目标编码到关联空间中,然后解码器根据编码器输出特征去生成相应的对抗样本,此时多个损失函数来确保生成对抗样本的有效性。最后这些对抗样本用于攻击目标模型,同时也用于提升模型的防御能力。
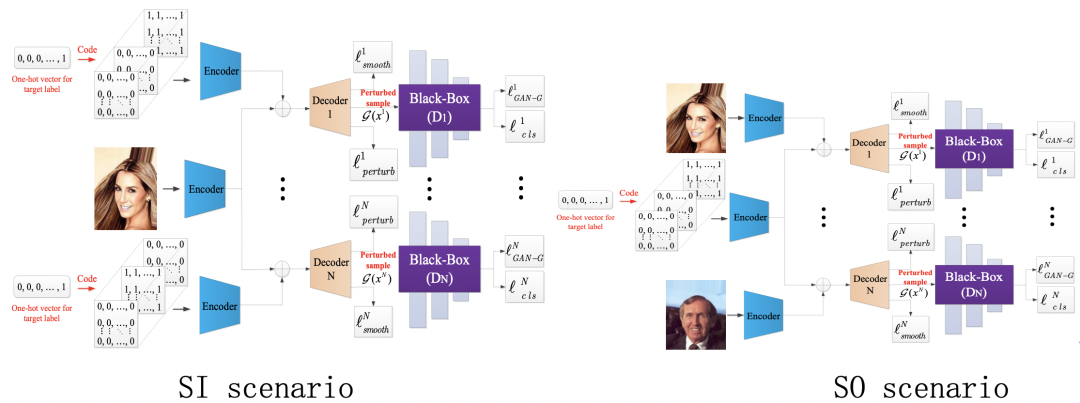
图2 多黑盒攻击算法系统框架
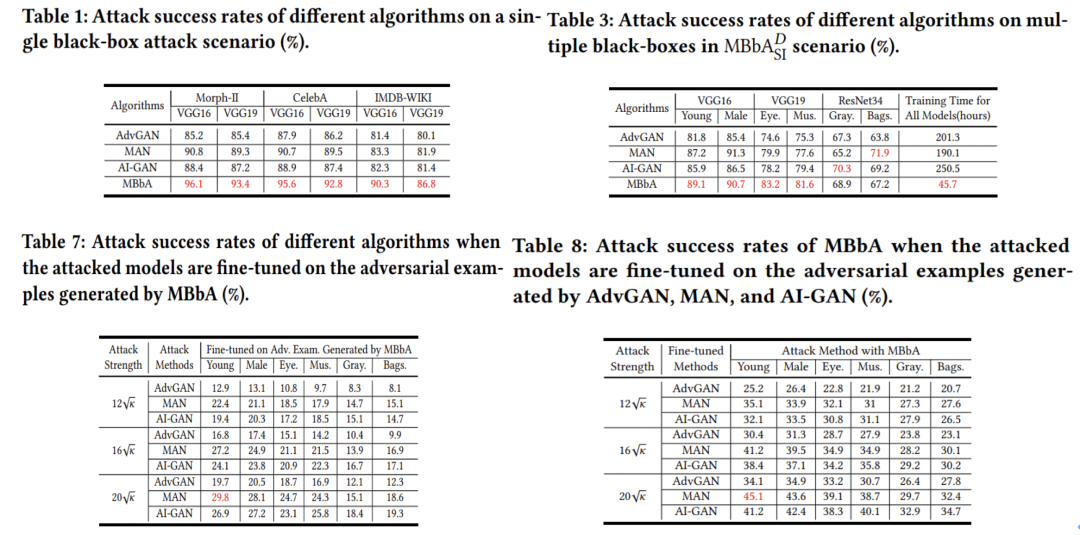
表1,3给出MBbA在单个黑盒系统和多黑盒系统上攻击结果,从图中我们可以看到,MBbA在所有比较算法中,大多数攻击性能是最好的,且花费的时间最少。同时我们将MBbA生成对抗样本用于训练目标模型的学习,这些学习后的模型防御性能提升很多,当这些算法再次攻击这些模型时候,攻击成功率大大下降,但依旧MBbA攻击成功率在大多数是最好的。其它实验结果可以具体参考原文。
06
Beyond OCR + VQA: Involving OCR into the Flow for Robust and Accurate TextVQA
作者:曾港艳1,张远1,周宇2,3*,杨晓萌2,3
单位:1中国传媒大学,2中国科学院信息工程研究所,3中国科学院大学网络空间安全学院
邮箱:
zgy1997@cuc.edu.cn;
yzhang@cuc.edu.cn;
zhouyu@iie.ac.cn;
xiaomeng.17@intl.zju.edu.cn
论文:
https://dl.acm.org/doi/10.1145/3474085.3475606
*通讯作者
为了解决通用视觉问答(VQA)方法无法处理图像中文字信息的缺陷,文本视觉问答(TextVQA)任务被提出。TextVQA为了回答与图像中文字相关的问题,需要同时考虑视觉场景和文字等多个模态的信息及其关系,具有很大挑战。目前主流的方法通过引入一个外部的光学字符识别(OCR)模块作为前处理,再将其与VQA框架结合预测答案,这会使得TextVQA性能很大程度上受到OCR精度的影响,具体表现为以下两种误差累积传播现象:1)OCR错误使得对文字的直接语义编码错误,导致多模态信息的交互推理过程出现偏差,从而无法定位出准确的答案。2)即使是在推理和定位答案正确的情况下,OCR错误仍然会导致最终从OCR结果中“复制”的答案错误。另外,视觉物体模态与图像文字、问题模态交互时存在语义间隔,使得多模态信息无法有效融合。
针对以上问题,本文提出了一个对文字识别结果鲁棒的文本视觉问答方法BOV:通过将OCR融入TextVQA的前向处理流程,即借助来自文字检测和文字识别两个阶段的多模态线索,实现在没有准确识别文字的情况下也能获取对文字的合理的语义表示,并利用TextVQA任务丰富的上下文信息对解码的答案进行自适应修正。
图1是BOV模型的整体框架,它基于Transformer网络实现问题、图像文字和视觉物体三种模态信息的交互。区别于之前的方法,BOV在文字模态和物体模态分别设计一个模块来实现视觉到语义的映射,从而获得视觉增强的文字表征和语义导向的物体表征,目的是增强特征表示的鲁棒性,减小OCR错误和物体识别错误对推理的影响。另外在答案预测模块提出一个如图2所示的上下文感知的答案修正模块(CRM)对“复制”的答案词进行校正。
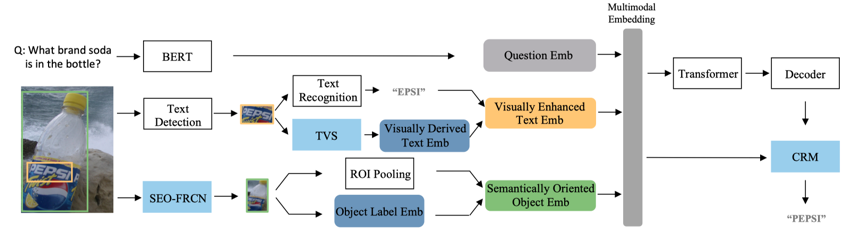
图1 BOV模型整体框架
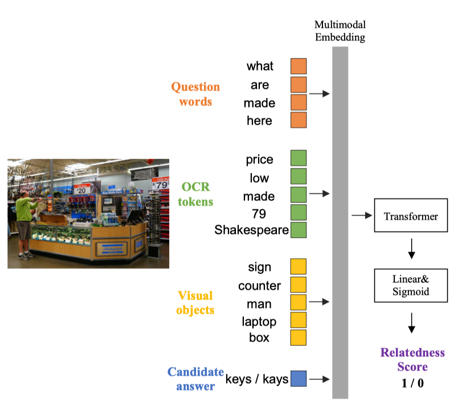
图 2 上下文感知的修正模块(CRM)结构图
BOV在两个广泛使用的数据集(TextVQA、ST-VQA)上进行了实验。如表1所示,它相较于已有的方法获得了显著的提升。由图3的实验结果表明,与基准模型M4C相比,BOV在不同OCR条件下都能取得较好的性能,证明了模型的鲁棒性,更适用于实际应用场景。图4展示了一些定性比较结果。
表 1 BOV与已有方法在TextVQA数据集上的比较
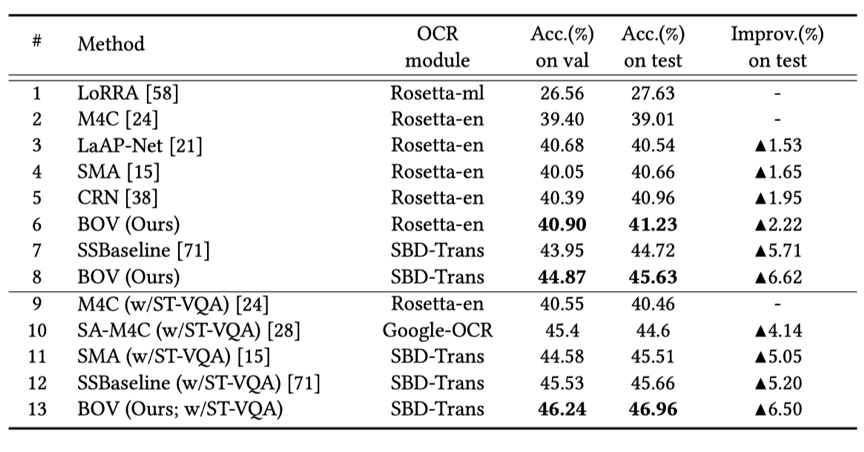
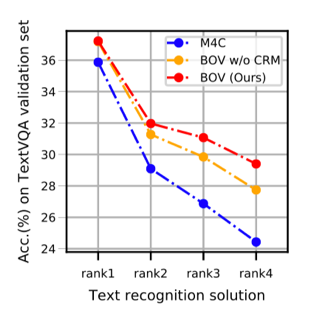
图 3 BOV与M4C在不同OCR结果时的比较(rank1至rank4的OCR准确率逐步下降)
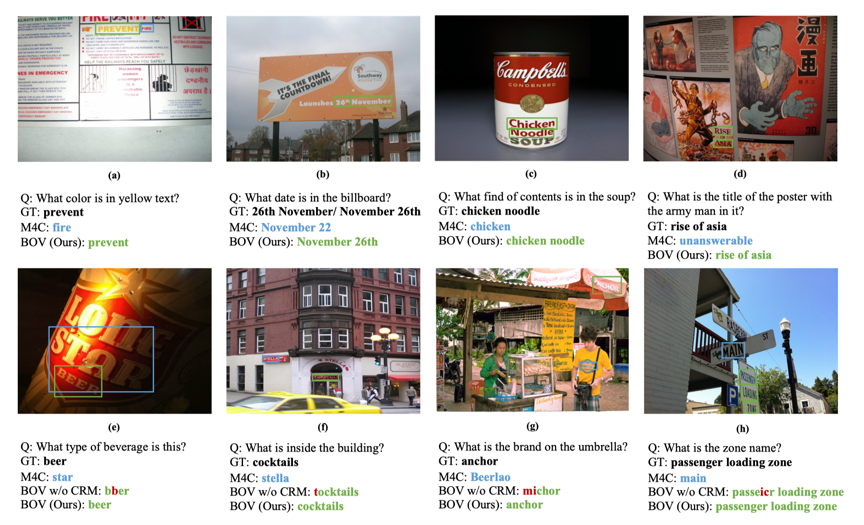
图 4 BOV与M4C的定性比较
07
DSSL: Deep Surroundings-person Separation Learning for Text-based Person Retrieval
作者:朱艾春、王子杰、李义丰、万夕里、金晶、王田、胡方强、华钢
单位:南京工业大学、北京航空航天大学、中国矿业大学
邮箱:aichun.zhu@njtech.edu.cn
论文:
https://dl.acm.org/doi/10.1145/3474085.3475369
数据集:
https://github.com/NjtechCVLab/RSTPReid-Dataset
基于文本描述的行人重识别任务致力于根据所提供的文本描述在大规模的图像数据库中检索得到相应的行人图像。本研究针对跨模态行人重识别任务展开研究,并提出了一种深度环境行人分离学习模型(Deep Surroundings-person Separation Learning model, DSSL)。现有算法一般都致力于学习一个公共空间映射,以从异质的多模态数据中提取富有鉴别能力的特征。但由于高维数据的复杂性,无约束的映射方法很难在正确捕捉行人特征的同时剥离掉干扰信息。直观上看,图像数据中包含的信息可以分为行人信息与环境信息,二者为互斥关系。
在大多数实际应用场景中,文本描述的提供者并不知道目标行人所处的场景与环境,因而文本中基本只包含行人信息。基于这一观点,论文中提出了一种深度环境行人分离学习模型(DSSL)进行高效精准的行人特征提取与匹配。如图1、 2所示,环境行人分离与融合机制(SPSM+SPFM)起到了关键性的作用,在信息正交约束下,通过行人特征的分离与跨模态融合重构匹配,采用五种不同的跨模态多粒度信息对齐方式,在训练过程中相互制约与引导,从而实现精准的环境行人剥离与匹配,极大提升了模型精度。
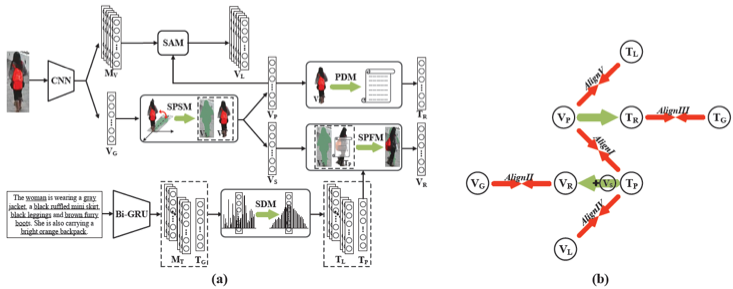
图 1 模型结构图
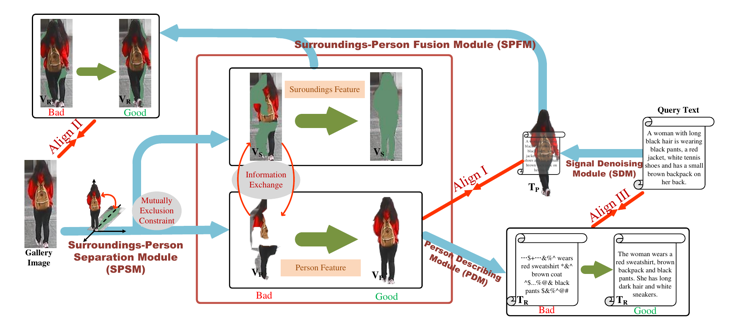
图 2 环境行人分离与融合机制
为了进一步推动该课题后续研究的发展,本研究团队在MSMT17基础上,构建了一个全新的真实场景跨模态行人重识别数据集(Real Scenarios Text-based Person Reidentification dataset, RSTPReid),其中每个行人的5张图像均由不同相机在不同的时间、地点、天气、光照、视角等条件下拍摄得到,共计20000余张图片,40000余条文本标注信息(如图3所示)。与CUHK-PEDES相比,RSTPReid更加复杂、更具挑战性,且更加接近实际的应用场景。目前,该数据集发布在GitHub上:
https://github.com/NjtechCVLab/RSTPReid-Dataset

图3 RSTPReid数据集高频词云与行人图像示例
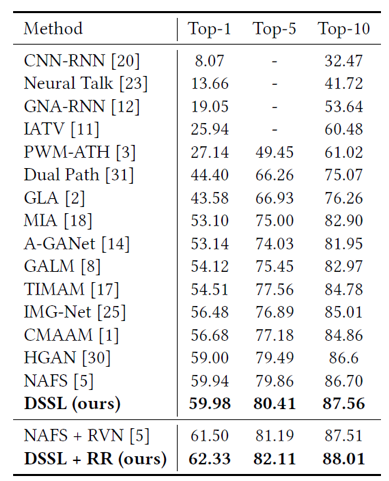
此外,本文在CUHK-PEDES数据集验证了DSSL有效性,算法模型的表现基于前k准确率(top-k accuracy)进行评估。如表1所示,DSSL在Top-1、Top-5 及Top-10 准确率评估准则下的表现均超越此前所有的方法,由此也可以说明通过行人特征的分离与跨模态融合重构匹配,实现精准的环境行人剥离与匹配,进而使得检索精度得到了较大的提升。
表1 在CUHK-PEDES数据集与相关算法的性能比较

编辑人:桑基韬、聂礼强
专委会责任副主任:徐常胜





