文本主题发现(一)-- 数据预处理
点击蓝字关注这个神奇的公众号~

作者:赵镇宁 R语言中文社区特约作者

往期回顾:
主题发现能够帮助我们处理和分析大规模信息并从中发现文本主要内容和主题,相关探测方法有文本聚类法、主题建模、多维尺度分析等等。这些分析方法的前期数据处理都不同程度的涉及分词、建立文档-词条矩阵、生成词条相似(相异)矩阵等关键步骤,本期主要是对前期数据预处理流程的大致总结,主要内容包括:
(1)分词:分词引擎+自定义词典+停用词词典
(2)特征(核心词)提取:高频词法+TF*IDF算法
(3)文档-词条矩阵(数据矩阵)建立:语料库+特征词+生成矩阵+稀疏矩阵处理
(4)词条相似性(相异度)矩阵建立:主要相关系数计算
本文用到的包有:

1. 数据收集
本文以《复仇者联盟3》500条热门豆瓣短评作为示例数据,数据抓取代码如下:
```
library(RCurl) # 网络请求
library(XML) # 网页解析
library(magrittr) # 管道操作
Cookie='your cookie'
headers <- c('Accept'='text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Content-Type'='text/html; charset=utf-8',
'User'='Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36',
'Cookie'=Cookie
)
comments<-c() # 短评
errorurl<-c() # 错误url
start<-0
i<-0
while(TRUE){
start=20*i
tryCatch({
url<-sprintf("https://movie.douban.com/subject/24773958/comments?start=%s&limit=20&sort=new_score&status=P&percent_type=",start)
web<-getURL(url,httpheader=headers)%>% htmlParse()
comment<-xpathSApply(web,"//div[@class='comment']//p[@class='']",xmlValue)
if(length(comment)==0) break
comments<-c(comments,comment)
cat(sprintf("第%s页抓取成功",i),sep = "\n")
},error = function(e){
errorurl<-c(errorurl,start)
})
Sys.sleep(runif(1,0.5,1.5))
i = i +1
}
save(comments,file="comment.Rdata")
```
2 文本预处理
以聚类为例,目前大多聚类算法通常选择两种代表性的数据结构,一是数据矩阵(对象-属性结构),即用P个变量(属性)来表现n个对象,如用年龄、身高、性别等属性来表现对象“人”,可以看成一个n*p的矩阵;二是相异度矩阵(对象-对象结构或属性-属性结构),即存储n个对象或p个属性两两之间的差异性,可以看成一个n*n(对象与对象之间)或p*p(属性与属性之间)的矩阵。对应在主题发现中,数据矩阵表现为文档-词条矩阵,相异度矩阵表现为词条-词条矩阵。因此接下来的文本预处理包括:分词、特征(核心词条)提取、建立文档-词条矩阵和建立词条-词条相异度矩阵几个关键步骤。
2.1 分词准备
R中常用的分词包有Rwordseg和jiebaR,其中,Rwordseg使用rJava调用Java分词工具Ansj,Ansj基于中科院ictclas中文分词算法,采用隐马尔科夫模型(HMM),当前版本的Rwordseg完全引用了Ansj包,在这个Java包的基础上开发了R接口,并在Rforge(https://r-forge.r-project.org/R/?group_id=1054)进行维护,我们可以下载安装包进行本地安装。jiebaR是“结巴”中文分词(https://github.com/fxsjy/jieba)(Python)的R语言版本,支持隐马尔科夫模型、混合模型、最大概率法等八种分词引擎,同时具有词性标注,关键词提取,文本Simhash相似度比较等功能,本文选取jiebaR进行分词。
A. 关于分词引擎选择
本文选择的是混合模型,混合模型(MixSegment)结合使用最大概率法和隐马尔科夫模型,在分词引擎里面分词效果相对较好。
B. 关于自定义词典
为提高分词准确率,本文首先以搜狗细胞库提供的《复仇者联盟3》词库作为自定义词典,需要注意的是,搜狗词库scel文件是二进制,需要把二进制的词典转成可以使用的文本文件,jiebaR包的作者同时开发了一个cidian项目,可以转换搜狗的词典,目前托管在github,可通过devtools::install_github("qinwf/cidian")进行安装。此外,基于《复仇者联盟3》自定义词典进行分词后查看初步结果,不断往里面添加进行完善。
```
library(jiebaR)
library(cidian)
decode_scel(scel = "mydic.scel",cpp = TRUE)#将scel文件进行转换
output file: mydic.scel_2018-05-30_22_29_33.dict
scan(file="mydic.scel_2018-05-30_22_29_33.dict",what=character(),nlines=20,sep='\n',encoding='utf-8',fileEncoding='utf-8')#查看转换后的词典
Read 20 items
[1] "艾瑞克 n" "艾什莉 n" "埃文斯 n" "奥创 n" "奥创纪元 n"
[6] "奥克耶 n" "巴顿 n" "班纳 n" "鲍尔斯 n" "保罗 n"
[11] "贝坦尼 n" "变身巨人 n" "变种人 n" "变种人兄弟会 n" "波蒂埃 n"
[16] "波兹 n" "布鲁斯 n" "布鲁斯班纳 n" "布思 n" "操纵物体 n"
```
C. 关于停用词词典
首先在网上下载了一份常用停用词词典(结合哈工大停用词表、四川大学机器智能实验室停用词库、百度停用词表等),进行试分词,根据初步分词结果往停用词表中添加会对数据结果造成较大影响的停用词。
D. 关于特征(核心词条)提取
受研究工具、统计分析过程限制以及出于提高结果分析与可视化效用的目的,我们通常提取部分关键词(特征)来进行后续分析,通常用到的筛选方法有高频词法和TF*IDF算法,其中高频词法是将所有词汇按词频从高到底排序,根据经验或某一法则(如齐普夫法则)确定某一阈值,高于该阈值的为特征词,其核心思想是“一个词在文章中出现的次数越多,则它就越重要”;TF*IDF算法则考虑到“一个词语在一篇文章中出现次数越多, 同时在所有文档中出现次数越少, 越能够代表该文章”,本文利用TF*IDF算法提取。
jiebaR包在安装目录中的idf.utf8文件为IDF的语料库,idf.utf8文件每一行有2列,第一列是词项,第二列为权重。通过计算文档的词频(TF),与语料库的IDF值相乘,就可以得到TF-IDF值,从而提取文档的关键词。
```
term<-c()
for(i in 1:500)
term<-segment(comments[i], wk ) %>% c(term,.)
termFreq<-freq(term) # 统计词频
termFreq<-termFreq[order(termFreq$freq,decreasing = TRUE),]
rownames(termFreq)<-as.character(1:4541)
head(termFreq)
char freq
1 灭霸 181
2 电影 96
3 漫威 96
4 反派 58
5 宇宙 57
6 英雄 48
keys<-worker(type="keywords",topn=1500) %>% vector_keywords(term,.) # 利用tf-idf提取核心词
keydf<-data.frame("tf-idf value"=names(keys),"term"=as.character(keys),stringsAsFactors = FALSE)
head(keydf)
tf.idf.value term
1 2124.8 灭霸
2 1126.96 漫威
3 766.037 反派
4 639.156 电影
5 540.003 复联
6 419.996 宇宙
write.csv(keydf,file="keydf.csv", fileEncoding = "GBK")
```
2.2 进行分词
后期建立文档词条矩阵时需要特定的数据格式,因此利用jieba分词后,需要设置成符合tm包格式的输出,即分词之后每条评论存成一个单独的字符串,并用空格对词语进行分隔。
```
wk = worker(type = "mix", user = "mydic.scel_2018-05-30_22_29_33.dict",
stop_word = "stopword.txt") # 加载jiebaR库的分词引擎
commentseg<-c()
for(i in 1:500)
commentseg[i]<-segment(comments[i], wk ) %>% paste(.,collapse=" ")
str(commentseg)
chr [1:500] "复联 讲 猪队友 顺风 浪 一波 团灭 故事 卡魔拉 倒霉 爸爸 疯子 男朋友 傻子" ...
write.csv(commentseg,file="commentseg.csv", fileEncoding = "GBK")
```
2.3 建立文档-词条矩阵
A. 建立语料库
tm包中有一个Corpus对象用以存储原始预料,可以直接从文件中读取或者由R中的某个对象来转换,这里使用分词之后的向量对象commentseg。由于语料对象包含所有的文档的信息,不方面使用常规的方式对它们进行查看,可以使用inspect函数来查看。
```
library(tm)
ss<-read.csv("commentseg.csv",fileEncoding = "GBK",stringsAsFactors = FALSE)
docs<-ss$x %>% tolower()
d.corpus<-VCorpus(VectorSource(docs)) # 建立语料库
d.corpus
<
> Metadata: corpus specific: 0, document level (indexed): 0
Content: documents: 500
inspect(d.corpus[1:2]) # 查看语料库
<
> Metadata: corpus specific: 0, document level (indexed): 0
Content: documents: 2
[[1]]
<
> Metadata: 7
Content: chars: 42
[[2]]
<
> Metadata: 7
Content: chars: 137
```
B. 建立文档-词条矩阵
文本分析的基础对象是文档-词条矩阵,该数据结构在tm包中有一个专门的DocumentTermMatrix对象来实现,在文档-词条矩阵中每一行是一篇文档(评论),每一列是一个词,行和列的节点是该文档中包含该词的数目。此外,字典是一个字符集,它可以作为一个控制参数传入DocumentTermMatrix(),从而选择我们需要的词条建立文档-词条矩阵,这里以前面基于TF*idf算法得出的1500个词作为我们的词条。
```
keyword<-read.csv("keydf.csv", fileEncoding = "GBK",stringsAsFactors = FALSE)
keyword<-keyword$term %>% tolower() # 之前通过tf-idf筛选的核心词汇
dtm <- DocumentTermMatrix(d.corpus,control = list(wordLengths=c(1,Inf),dictionary=keyword)) # 注意wordLengths的取值设定
df_mat<-as.matrix(dtm) # 转换为矩阵形式
write.csv(df_mat,file="df_mat.csv")
```
C. 稀疏矩阵处理
```
dtm
<
> Non-/sparse entries: 4663/745337
Sparsity : 99%
Maximal term length: 22
Weighting : term frequency (tf)
```
Non-/sparse entries表示矩阵内有4663个元素大于0,而有745337个元素等于0,这种由大部分元素为0组成的矩阵成为稀疏矩阵,99%表示矩阵的稀疏程度为99%,我们可以通过tm包内的removeSparseTerms设定稀疏度大小阈值,对每个词汇做稀疏度筛选,下文将稀疏度阈值设定为0.7,表示原始矩阵的每个词汇稀疏度大于70%以上,就不予以放入DocumentTermMatrix中,下文得到的矩阵(500条评论,1词汇),矩阵内有153个元素大于347个元素是0,整体稀疏度为69%。考虑到本文评论文本规模以及经稀疏度处理后词汇量较少(小于5),因此这里不再做稀疏处理。
```
dtm_sub<-removeSparseTerms(dtm,0.7)
dtm_sub
<
> Non-/sparse entries: 153/347
Sparsity : 69%
Maximal term length: 2
Weighting : term frequency (tf)
```
2.4 建立相似(相异度)矩阵
相似矩阵存储 n 个对象两两之间的相似性,目前我接触到的相似性计算方法大致可以分为三类,一是基于共现频次这一基本统计量衍生出来的,如互信息度、association strength、inclusion index、Jaccard’s coefficient、Salton’s cosine(Ochiia系数)等;二是借助知网(HowNet)、WordNet 等通用本体库以及领域词典的知识体系(包括词汇的定义及词汇间的相关关系),设计许多有用的算法来衡量词汇之间的相似程度;三是进行词向量化,如Word2vec。本文利用Salton’s cosine(Ochiia系数)来测度词语之间的相似性,具体算法如下(设文档词条矩阵为A):
(1)由文档-词条矩阵A生成共现矩阵C:
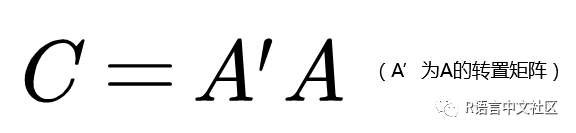
(Cij表示两两词条在同一文档中共现的频次,其中当i=j[即矩阵对角线]时表示词条本身在所有文档中出现的频次)
(2)由共现矩阵C生成相似矩阵S或相异矩阵D(1-S)
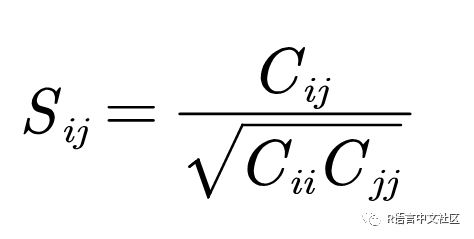
(上式表示两个词在同一评论中的共现频次/两个词出现频次的积的平方根)
```
cooccurance_mat<-t(df_mat)%*%df_mat# 共现矩阵
similarity_mat<-matrix(nrow=ncol(df_mat),ncol=ncol(df_mat)) # 利用Salton’s cosine得相似矩阵
dimnames(similarity_mat) <- list(colnames(df_mat),colnames(df_mat))
for(i in 1:ncol(df_mat))
for(j in 1:ncol(df_mat))
ifelse(i==j,similarity_mat[i,j]<-1,similarity_mat[i,j]<-cooccurance_mat[i,j]/(sqrt(cooccurance_mat[i,i]*cooccurance_mat[j,j])))
dissimilarity_mat<-1-similarity_mat # 相异度矩阵
write.csv(similarity_mat,file="similarity_mat.csv")
write.csv(dissimilarity_mat,file="dissimilarity_mat.csv")
```
3 总结
A. 乱码问题
使用tm包建立文档-词条矩阵时经常遇到乱码问题,导致数据结果不正确,尝试过很多办法都无效……最后采取的办法是将语料库和特征词先按特定编码存储到本地,然后再读到R中。
B. 关于DocumentTermMatrix函数
(1)特别注意wordLengths参数的设置,该参数设置显示词的最小及最大长度,默认最小为3!!,也就意味着词长度小于3的词都不会被提取出来。
(2)注意tolower参数的设置,我的语料库中所有的大写英文单词都不能提取出来,只有转换为小写才能提取。

公众号后台回复关键字即可学习
回复 R R语言快速入门及数据挖掘
回复 Kaggle案例 Kaggle十大案例精讲(连载中)
回复 文本挖掘 手把手教你做文本挖掘
回复 可视化 R语言可视化在商务场景中的应用
回复 大数据 大数据系列免费视频教程
回复 量化投资 张丹教你如何用R语言量化投资
回复 用户画像 京东大数据,揭秘用户画像
回复 数据挖掘 常用数据挖掘算法原理解释与应用
回复 机器学习 人工智能系列之机器学习与实践
回复 爬虫 R语言爬虫实战案例分享