1000层 Transformer 也能稳定训练?详解微软亚研院提出新工作DeepNet

极市导读
但是虽然 Transformer 模型的参数从数百万增加至数十亿甚至数万亿,大规模模型也在一系列任务上都取得了 SOTA 的性能,但是视觉 Transformer 模型的深度却受到了训练不稳定的限制,使得 Transformer 模型不容易像CNN 那样做Deep。本文所提出的 DeepNet 模型成功地将 Transformer 的深度扩展到了1000层解决了该问题。>>加入极市CV技术交流群,走在计算机视觉的最前沿
本文目录
43 解决 Transformer 训练难题,1000层 Transformer 也能稳定训练
(来自微软亚洲研究院)
43.1 DEEPNET 原理分析
Transformer 是 Google 的团队在 2017 年提出的一种 NLP 经典模型,现在比较火热的 Bert 也是基于 Transformer。Transformer 模型使用了 Self-Attention 机制,不采用 RNN 的顺序结构,使得模型可以并行化训练,而且能够拥有全局信息。
视觉 Transformer 模型在计算机视觉领域取得了巨大的成功,甚至大有取代 CNN 之势。但是虽然 Transformer 模型的参数从数百万增加至数十亿甚至数万亿,大规模模型也在一系列任务上都取得了 SOTA 的性能,并在小样本和零样本学习设置下展现出了令人瞩目的能力,但是视觉 Transformer 模型的深度 (depth) 却受到了训练不稳定的限制,使得 Transformer 模型不容易像 CNN 那样做 Deep。
本文就是为了解决这个问题,所提出的 DeepNet 模型成功地将 Transformer 的深度扩展到了1000层。
43 解决 Transformer 训练难题,1000层 Transformer 也能稳定训练
论文名称:DeepNet: Scaling Transformers to 1,000 Layers
论文地址:
https://arxiv.org/pdf/2203.00555.pdf
43.1 DeepNet 原理分析:
在 Toan Q. Nguyen and Julian Salazar 的这篇文章里面:
Transformers without tears: Improving the normalization of self-attention
Toan Q. Nguyen and Julian Salazar 发现把每个 Block 里面的 Layer Normalization 层从 Self-Attention 层的后面 (Post-LN) 换到 Self-Attention 层之前 (Pre-LN),能够提升 Transformer 训练的稳定性。但是后人的研究又发现 Pre-LN 层的梯度存在这样的现象,即:浅层的梯度高于深层,这个现象会使 Pre-LN 的性能不如 Post-LN。之后,又有几个工作试图将 Transformer 模型做得更深,如下:
从初始化角度:Improving deep transformer with depth-scaled initialization and merged attention (EMNLP-IJCNLP 2019)
从初始化角度:Improving transformer optimization through better initialization (ICML 2020)
从结构的角度:Learning deep transformer models for machine translation (ACL 2019)
从结构的角度:Understanding the difficulty of training transformers (EMNLP 2020)
从结构的角度:Rezero is all you need: Fast convergence at large depth
从结构的角度:Normformer: Improved transformer pretraining with extra normalization
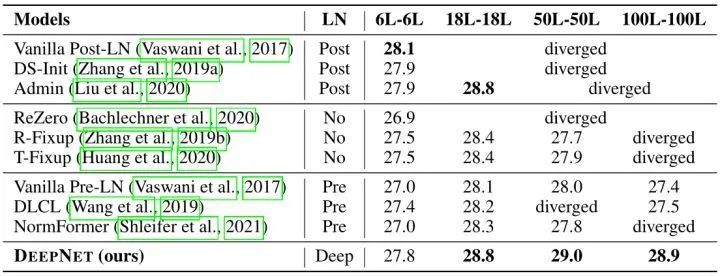
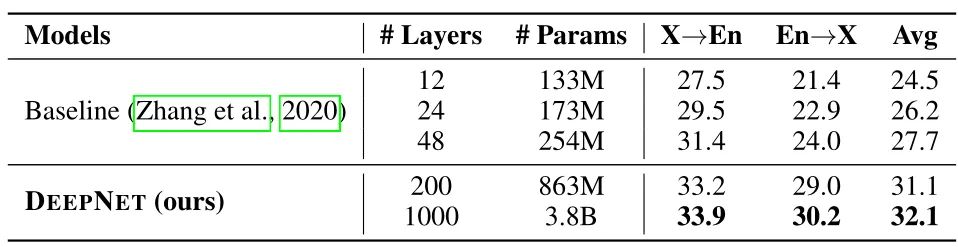
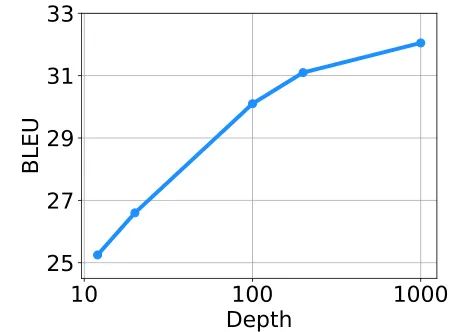
这些工作能够把 Transformer 训练到数百层的深度,但是训练到1000层,是前所未有的。
本文作者的目标是提升 Transformer 模型的训练稳定性,并将模型深度进行数量级的扩展。
43.1.1 Motivation
论文里面并没有很清楚地说明把 Transformer 做深的动机是什么,一开始读这篇论文时我首先想到的是为什么一定要把 Transformer 模型做得这么深 (除去发论文的目的)。
后来结合 MSRA 的一系列工作 (Swin, Swin V2),和这个知乎的回答:如何评价微软亚洲研究院的Swin Transformer V2:在4个数据集上达到SOTA?:https://www.zhihu.com/question/500004483/answer/2236028403。个人觉得目前大模型是诸如 MSRA 这类大厂的研究趋势,从 Swin V2 强行扩展就能够看得出,SwinV2 这个工作本身,不是开创性的,也未必会对整个领域产生深远的影响,但这个工作本身对 Swin 是重要的,因为在大规模无监督数据加大模型的故事里,一个新结构,必须要证明自己能有效的训练大模型。
那么在这个无监督+大模型的故事背景下,简单地通过增加 Block 的 channel 来把 Swin Transformer 从 Base 扩展到 G 是可以的,但如果想再大,就要从 Depth 的角度来扩展了。
Swin V2 搞懂 Vision Transformer 原理和代码,看这篇技术综述就够了(二十) 已经研究了几种解决训练中的不稳定性问题的方法,如:
-
Post Normalization 技术。 -
Scaled Cosine Attention 技术。 -
和对数连续位置编码技术等等。
但是还是那句话,这些方法只是辅助 Transformer 在 channel 维度增加的训练方法,对于 Depth 维度的增加,需要探索新的稳定训练的方式,这也是本文的价值所在。
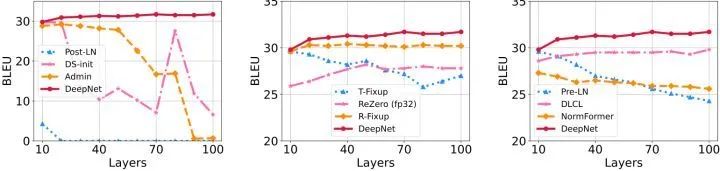
为此,作者们研究了不稳定优化的原因,并且发现爆炸式模型更新 (exploding model update) 是造成不稳定的罪魁祸首。基于这些观察,研究者在残差连接处引入了一个新的归一化函数 —— DEEPNORM,它从理论上保证了把模型更新过程限制为常数。这一方法简单但高效,只需要改变几行代码即可。最终,该方法提升了 Transformer 模型的稳定性,并实现了将模型深度扩展到了1000多层。
结果显示,本文的方法能够将 Post-LN 性能的优势和 Pre-LN 训练稳定的优势结合起来,且对于目前多个大型 Transformer 模型也是适用的。
43.1.2 太长不看版
如果没时间仔细阅读,只需要看本小节这一点点就行。
DeepNorm 伪代码:
def deepnorm(x):
return LayerNorm(x∗α + f(x))
def deepnorm_init(w):
if w is ['ffn', 'v_proj', 'out_proj']:
nn.init.xavier_normal_(w, gain=β)
elif w is ['q_proj', 'k_proj']:
nn.init.xavier_normal_(w, gain=1)
1 使用 DeepNorm 时,拿它来替换 Post-LN。
2 DeepNorm 其实就是 LN,只是在执行层归一化之前 up-scale 了残差连接。x∗α + f(x) 里面的 f(x) 代表 Self-Attention 等等的 Token-mixer,x 代表 Token-mixer 的输出,α 是常数。
3 torch.nn.init.xavier_normal_(tensor, gain=1) 是 xavier 高斯初始化,参数由0均值,标准差为 gain × sqrt(2 / (fan_in + fan_out)) 的正态分布产生,其中 fan_in 和 fan_out 是分别权值张量的输入和输出元素数目。这种初始化同样是为了保证输入输出的方差不变。
4 DeepNorm 还在初始化期间 down-scale 了参数。值得注意的是,对于 ffn,v_proj,out_proj 和 q_proj,k_proj 的初始化,是不一样的。5 不同架构的 α 和 β 值不一样,如下图所示。

43.1.3 深度 Transformer 模型训练的不稳定问题
根据前人的研究,更好的初始化方法可以让 Transformer 的训练更稳定。因此,研究者分析了有无适当初始化的 Post-LN 的训练过程。通过更好的初始化,在执行 Xavier 初始化后对第 层的权重进行 downscale,下降的比例是: 。比如,第 层的 FFN 的权重初始化为:
式中, 是输入和输出维度的均值。
研究者将此模型命名为 Post-LN-init。注意到 这个值是随着层数的增加而越来越小的,也就意味着对于浅层而言,权重进行 downscale 的比例较大,对于深层而言,权重进行 downscale 的比例较小。此外,Post-LN-init 与 Post-LN 具有相同的架构,从而消除了架构的影响。
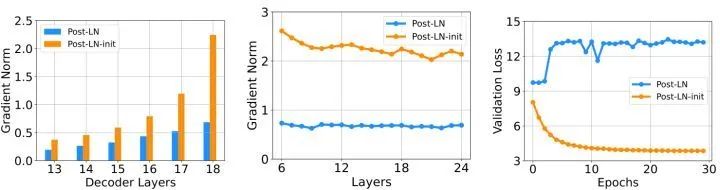
作者接下来在 IWSLT-14 De-En 机器翻译数据集上面训练了 18L-18L Post-LN 和 18L-18L Post-LN-init。如下图1所示是它们的梯度和 validation loss 的曲线。如图1(c) 所示,Post-LN-init 的 validation loss 是收敛的,但是 Post-LN 却没有。如图1(a) 所示,Post-LN-init 在最后几层中具有更大的梯度范数,尽管其权重已按比例 缩小。这说明梯度爆炸不是导致 Transformer 训练不稳定的原因。如图1(b) 所示,作者可视化最后一个解码器层的梯度范数,模型深度从 6L-6L 到 24L-24L,发现 Post-LN-init 的梯度范数大于 Post-LN 的梯度范数,但是初始化时 Post-LN-init 的范数是更小的。
接下来作者通过一系列实验,从实验的角度验证 Post-LN 的不稳定性来自一系列的问题。
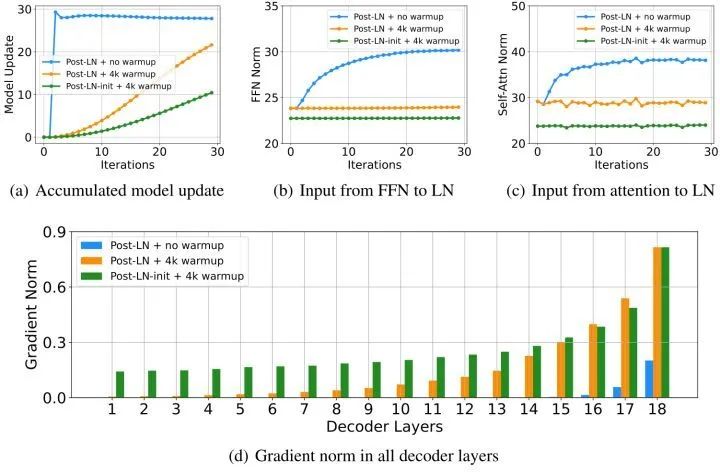
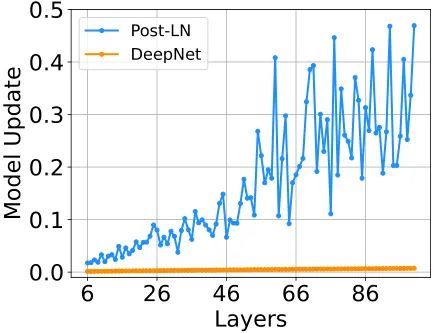
首先可视化在训练的早期阶段,模型更新的范数 ,如下图2(a)所示:
式中, 和 代表第 次更新的输入和模型参数。Post-LN 在训练一开始就有爆炸式的更新,然后很快就几乎没有更新了。这表明该模型已陷入虚假的局部最优。warm-up,或者更好的初始化都有助于缓解这个问题,使模型能够更加顺利地更新。图2(b)和(c)分别是从 FFN 层和 Attention 层到 LN 层的输入,作者发现当更新爆炸时,LN 的输入会变大。对于这种现象,之前已有理论分析:
On layer normalization in the transformer architecture (ICML 2020)
通过 LN 的梯度大小与其输入的大小成反比:
当不使用 warm-up 以及合适的初始化的情况下,图2(b)和(c) 表明 明显大于 ,这也就解释了 Post-LN 训练中出现的梯度消失问题,如图2(d)所示。
本节的结论是:
大的 Transformer 模型训练的不稳定的原因是训练的起始阶段模型参数更新非常快,它使模型陷入一个坏的局部最优,这反过来增加了每个 LN 的输入。随着训练的继续进行,通过 LN 的梯度变得越来越小,从而导致严重的梯度消失。消失的梯度使得难以脱离局部最优,并且进一步破坏了优化的稳定性。所以最关键的问题是不要让起始阶段模型参数更新得太快。相反,Post-LN-init 的更新相对较少,LN 的输入是稳定的。这减轻了梯度消失的问题,使优化更加稳定。
43.1.4 DeepNet 的架构
作者提出了一种非常深的 Transformer 模型,设计的初衷就是不要让起始阶段模型参数更新得太快。
作者首先估计了 DeepNet 模型更新的预期幅度,然后作者提供理论分析来证明它的更新可以被一个常数所限制。
DeepNet 的架构基于 Transformer,把 Post-LN 替换成 DeepNorm。DeepNorm 的表达式可以写成:
式中, 是常数, 是第 层 Transformer 的输出 (Attention 层或者 FFN)。DeepNet 还将残差内部的权重 扩展了 倍。
43.1.5 DeepNet 模型更新预期大小的估计
在下面这一小节里面,作者提供了对 DeepNet 模型更新预期大小 (Expected Magnitude) 的估计。不是一般性,研究一个 head 为1的 Attention 层。
Attention 模块的表达式可以写成:
式中, 依次代表了 query,key 和 value。 代表相应的映射矩阵。
接下来作者通过3个定理展示了 Attention 模块的一些性质:
[引理 4.1] 给定 ,其中 。对所有的 都有 ,则满足下式:
其中, 代表左右两侧的幅值是一样的 (Equal bound of magnitude)。
证明: 把 softmax 展开:
这样,上式就变成了:
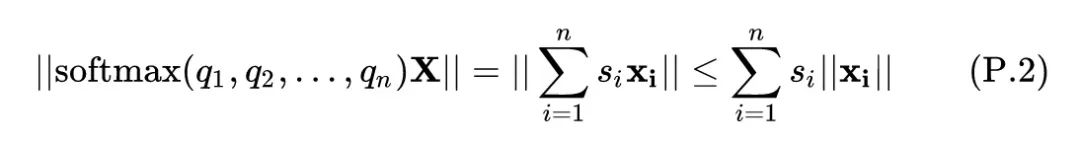
因为 ,所以有 。所以上式就变成了:
就等价于5式。得证。
引理 4.1说明,attention 层的输出幅度其实只取决于 Value 和输出的映射矩阵,即:
作者这里只考虑 hidden dimension 的情况,所以此时 就变成了标量 ,则意味着 。
同样的道理有: ,这里 分别代表 FFN 网络的参数。
定义模型某一层的输出的变化量为 ,基于以上分析,对于一个 层的 DeepNet 而言,对于 范围的估计有如下定理:
[定理 4.2] 给定一个 层的 DeepNet: ,其中 和 分别代表第 层的 Self-attention 和 FFN 的参数,且每层都使用 DeepNorm 去替换 LN,即: ,则 满足:
**证明:**作者的目的是研究模型更新的幅度,作出以下假设以简化推导:
-
Hidden dimension 。 -
。 -
相关权重 都是小于1的正数, 都是大于1的常数。
考虑到引理4.1,如果 是参数为 的 FFN 网络,则 。如果 是参数为 的 Self-attention 网络,则 。如果对各个投影矩阵使用 Xavier 初始化,则输出可以保持输入方差,这相当于 。根据假设2,有:
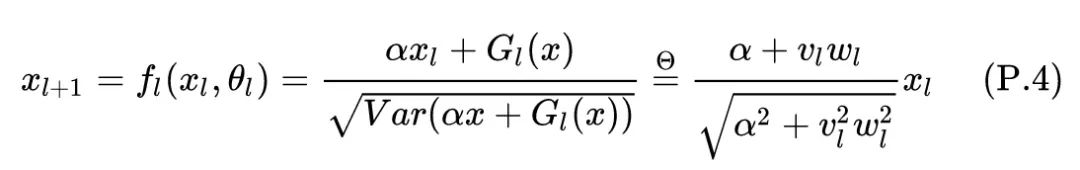
根据上式, 和 的范围界限是:
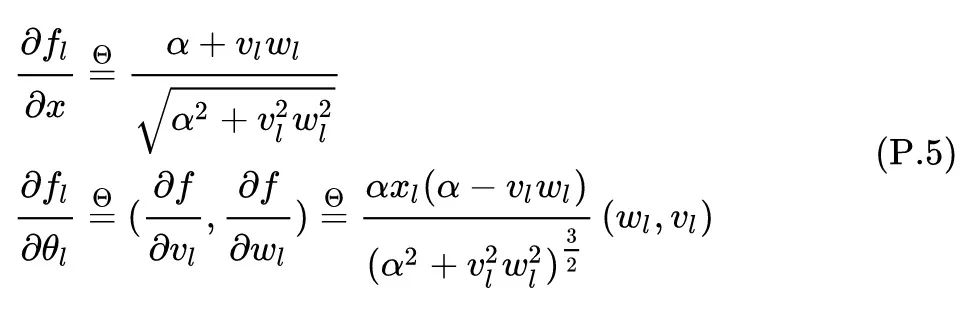
最后一层的输出的变化量 满足:
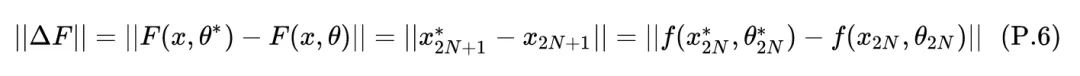
对上式使用泰勒展开,有:
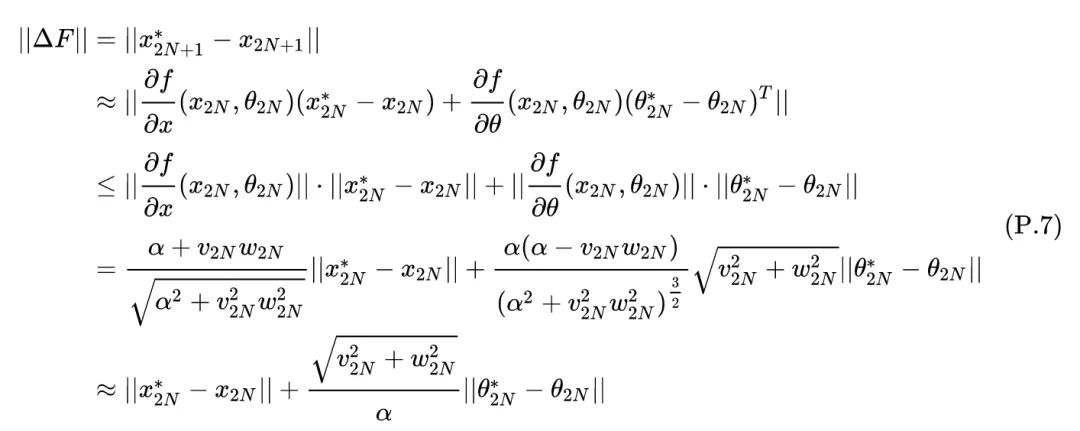
上式表明了 与 的关系,因此有:
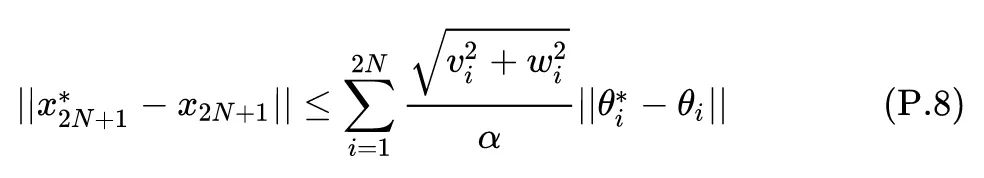


总结
公众号后台回复“数据集”获取30+深度学习数据集下载~

# 极市平台签约作者#

科技猛兽
知乎:科技猛兽
清华大学自动化系19级硕士
研究领域:AI边缘计算 (Efficient AI with Tiny Resource):专注模型压缩,搜索,量化,加速,加法网络,以及它们与其他任务的结合,更好地服务于端侧设备。
作品精选





