
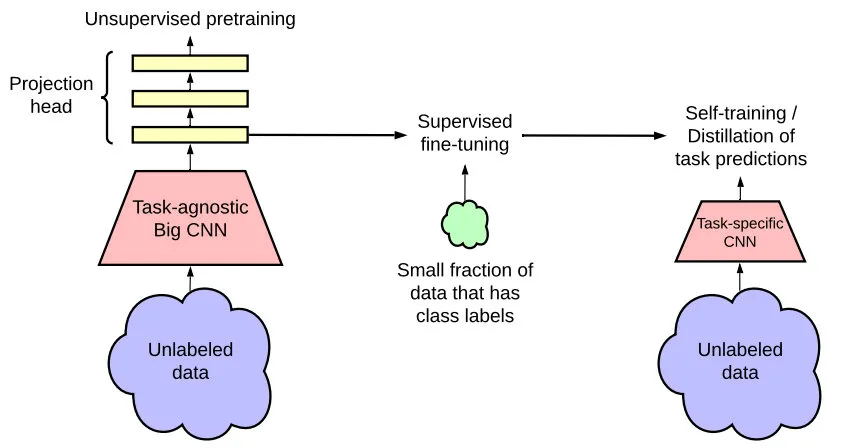
一种从少量带标签数据+大量无标签数据中进行学习的方案是:现在无标签数据集上采用无监督学习方案进行预训练,然后采用监督学习方式在少量带标签数据上进行微调。尽管方案中的无标签数据上的无监督学习是一种任务不可知方式(不同于其他CV中半监督学习),但是令人惊讶的是这种半监督学习的放在ImageNet上极为有效。
该方案的一个重要组成是预训练和微调阶段采用了“大模型”。作者发现:越少的标签数据,该方法越能从更大的模型中受益。经过微调后,大模型可以进一步得以改善并蒸馏更多信息到小模型中(注:蒸馏阶段会对无标签数据进行二次利用,此时该数据将以任务已知方式进行应用)。
总而言之,所提半监督方法可以总结为三步;(1)采用SimCLRv2方法在无标签数据上对一个Big ResNet模型进行预训练;(2)在有标签数据上通过有监督方式进行微调;(3)在无标签数据上采用蒸馏方式进行进行知识迁移。
所提方法在仅仅采用1%有标签数据时,ResNet50取得了73.9%的top-1精度;当采用10%有标签数据时,ResNet50的精度达到了77.5%的top-1精度。这个精度超越了采用全部有标签数据时有监督训练的精度。
成为VIP会员查看完整内容
相关内容

Arxiv
4+阅读 · 2018年4月3日
相关VIP内容
相关资讯
相关论文
Arxiv
4+阅读 · 2018年4月3日