138页“策略优化”PPT--Pieter Abbeel
来源于:Pieter Abbeel教授(slide)
编辑:DeepRL
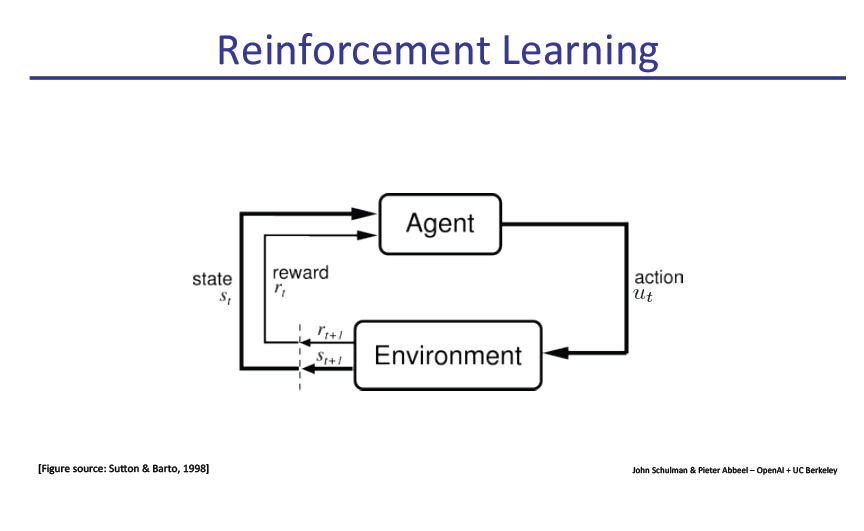
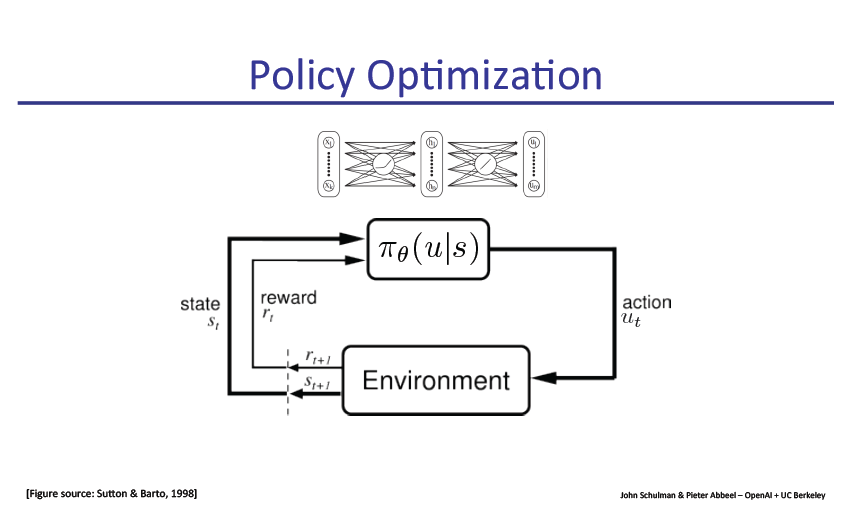
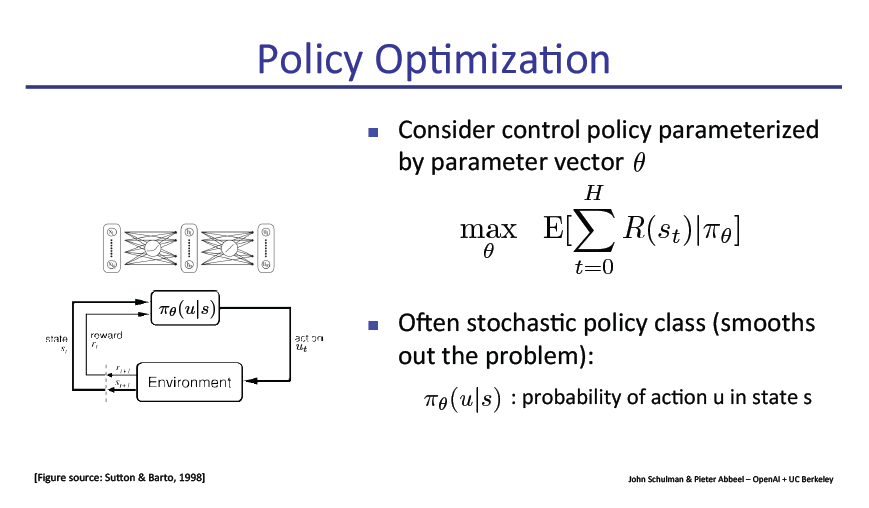
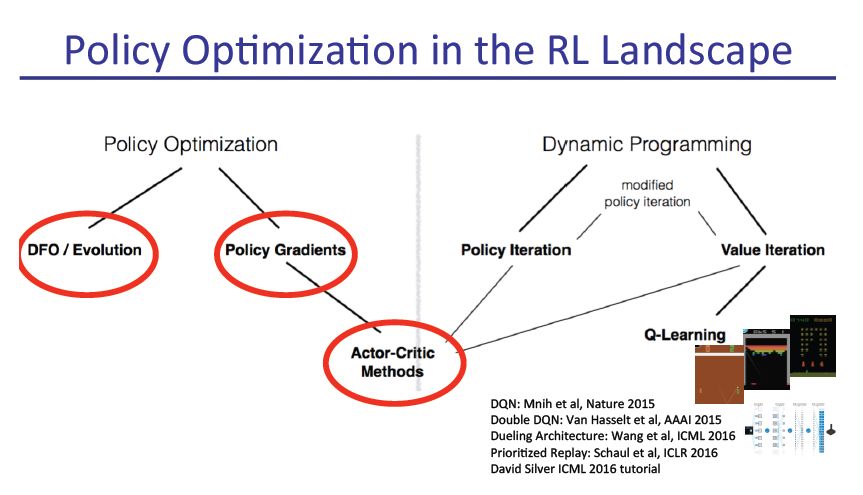
策略梯度法(Policy gradient methods)是近来使用深度神经网络进行控制的突破基础,不论是视频游戏还是 3D 移动或者围棋控制等,它们都基于策略梯度法。但是通过策略梯度法获得优秀的结果是十分困难的,因为它对步长大小的选择非常敏感。如果迭代步长太小,那么训练进展会非常慢,但如果迭代步长太大,那么信号将受到噪声的强烈干扰,因此我们会看到性能会急剧降低。同时这种策略梯度法有非常低的样本效率,它需要数百万(或数十亿)的时间步骤来学习一个简单的任务。因此,策略优化成为一个非常重要的研究问题,本文选取了大牛Pieter Abbeel的演讲slide。




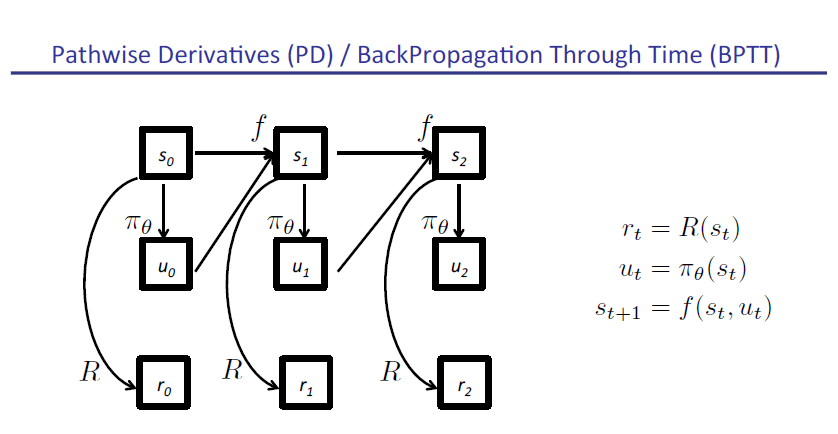




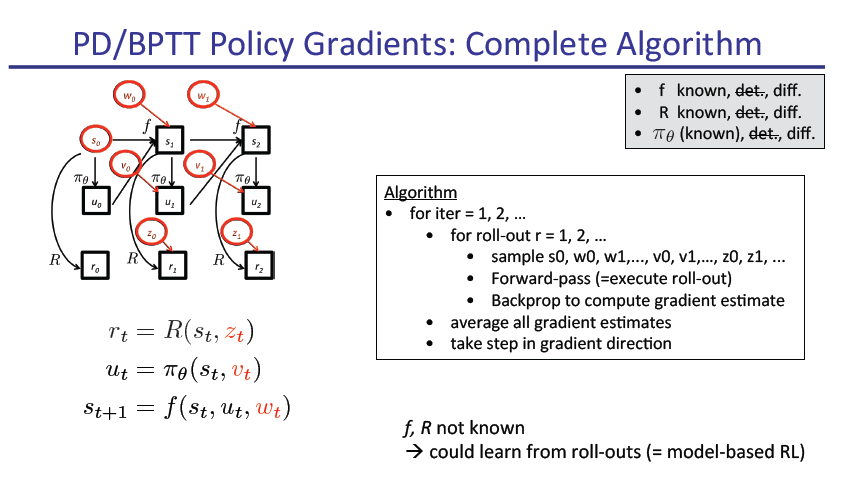
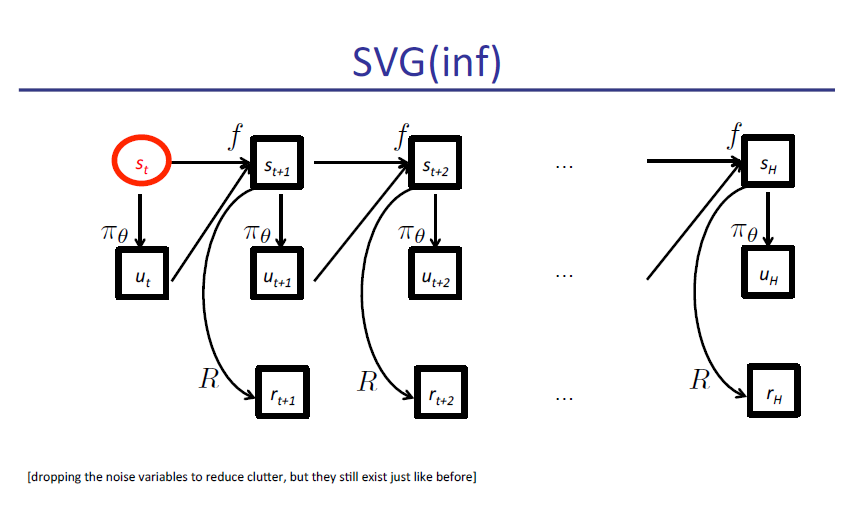
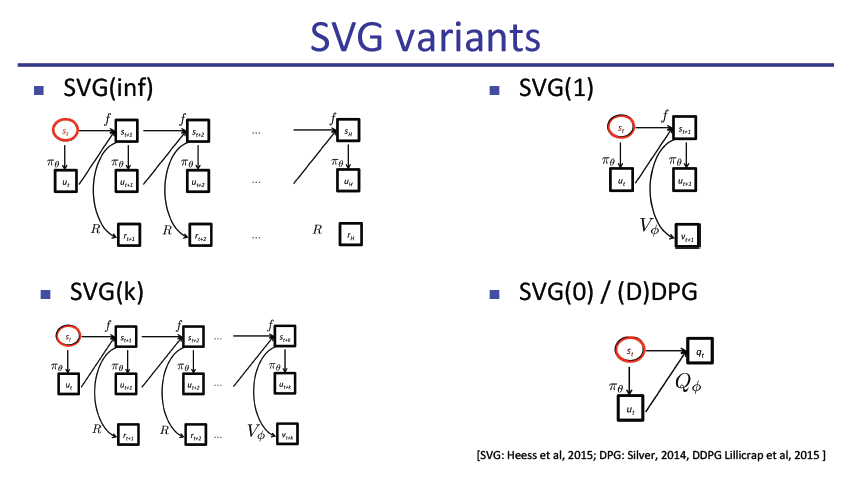

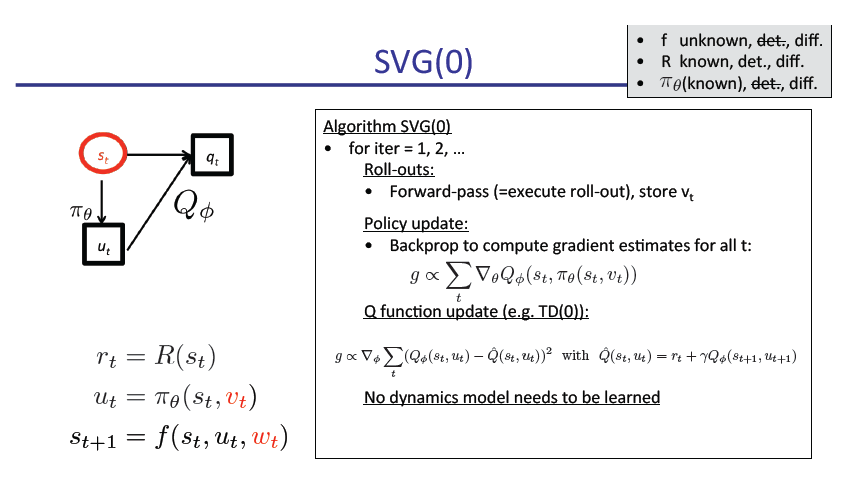






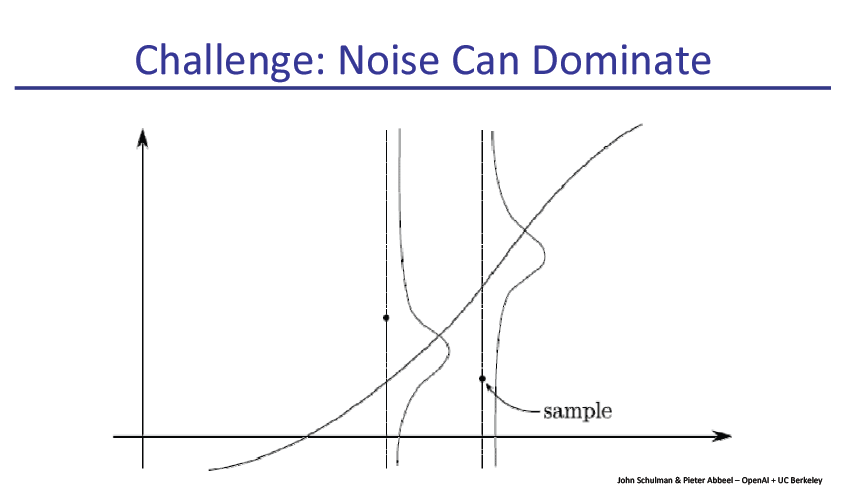











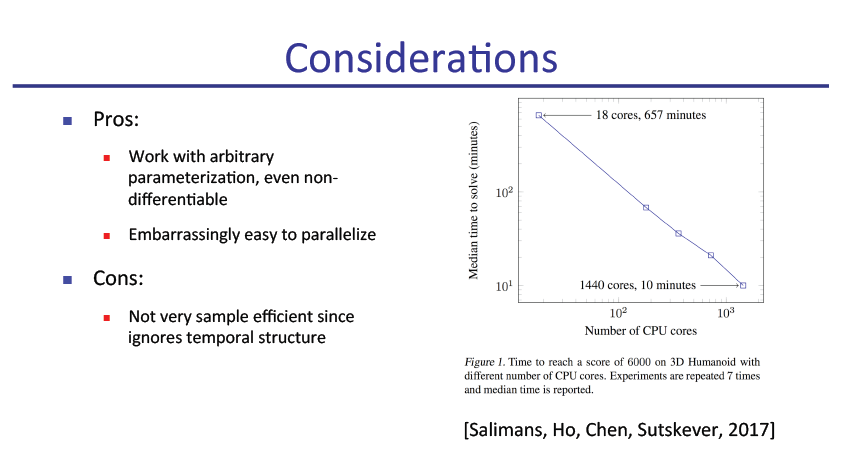























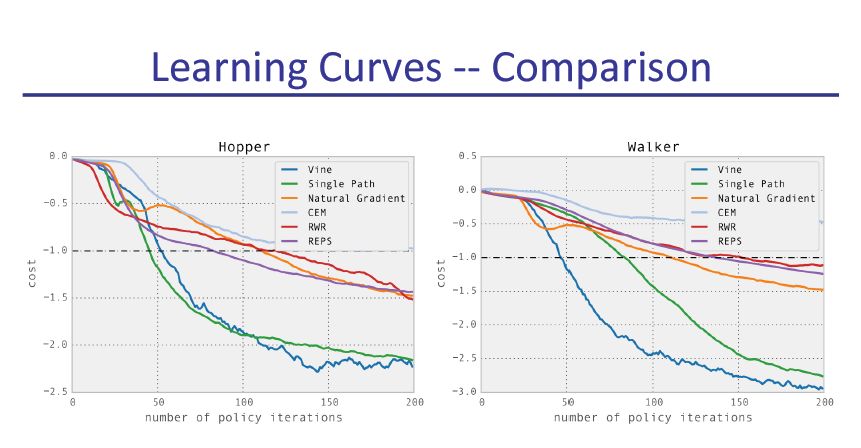










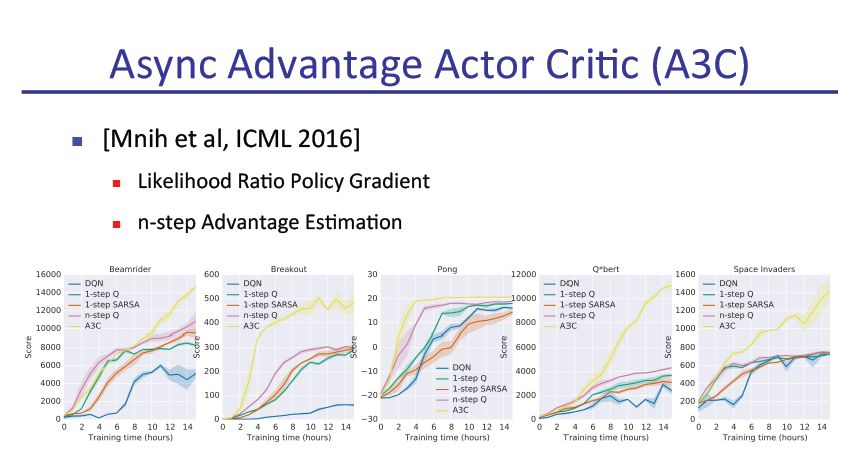
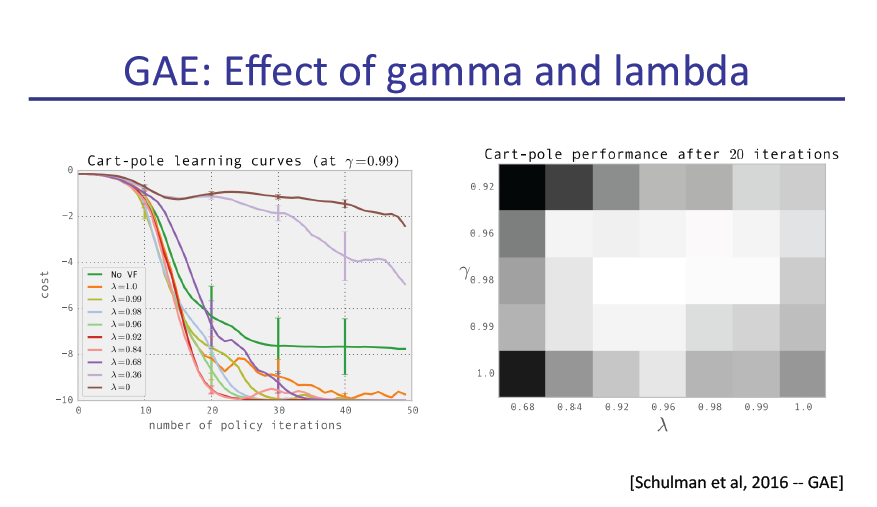









slide原文pdf地址:
1、公众后台回复:Policy
2、 https://github.com/NeuronDance/DeepRL

深度强化学习实验室
算法、框架、资料、前沿信息等
GitHub仓库
https://github.com/NeuronDance/DeepRL
欢迎Fork,Star,Pull Request
第27篇:迁移学习在强化学习中的应用及最新进展
第26篇:深入理解Hindsight Experience Replay
第25篇:10项【深度强化学习】赛事汇总
第24篇:DRL实验中到底需要多少个随机种子?
第23篇:142页"ICML会议"强化学习笔记
第22篇:通过深度强化学习实现通用量子控制
第21篇:《深度强化学习》面试题汇总
第20篇:《深度强化学习》招聘汇总(13家企业)
第19篇:解决反馈稀疏问题之HER原理与代码实现
第17篇:AI Paper | 几个实用工具推荐
第16篇:AI领域:如何做优秀研究并写高水平论文?
登录查看更多
相关内容

Pieter Abbeel是加州大学伯克利分校电子工程和计算机科学教授,伯克利机器人学习实验室主任和伯克利AI研究实验室联合主任。
Arxiv
5+阅读 · 2018年9月17日




相关VIP内容
相关资讯
相关论文
Arxiv
5+阅读 · 2018年9月17日