【知识图谱】如何构建知识图谱
作者丨徐阿衡
学校丨卡耐基梅隆大学硕士
研究方向丨QA系统
实践了下怎么建一个简单的知识图谱,两个版本,一个从 0 开始(start from scratch),一个在 CN-DBpedia 基础上补充,把 MySQL,PostgreSQL,Neo4j 数据库都尝试了下。自己跌跌撞撞摸索可能踩坑了都不知道,欢迎讨论。
1. CN-DBpedia 构建流程
知识库可以分为两种类型,一种是以 Freebase,Yago2 为代表的 Curated KBs,主要从维基百科和 WordNet 等知识库中抽取大量的实体及实体关系,像是一种结构化的维基百科。另一种是以 Stanford OpenIE,和我们学校 Never-Ending Language Learning (NELL) 为代表的 Extracted KBs,直接从上亿个非结构化网页中抽取实体关系三元组。
与 Freebase 相比,这样得到的知识更加多样性,但同时精确度要低于 Curated KBs,因为实体关系和实体更多的是自然语言的形式,如“奥巴马出生在火奴鲁鲁。” 可以被表示为(“Obama”, “was also born in”, “ Honolulu”)。
下面以 CN-DBpedia 为例看下知识图谱大致是怎么构建的。
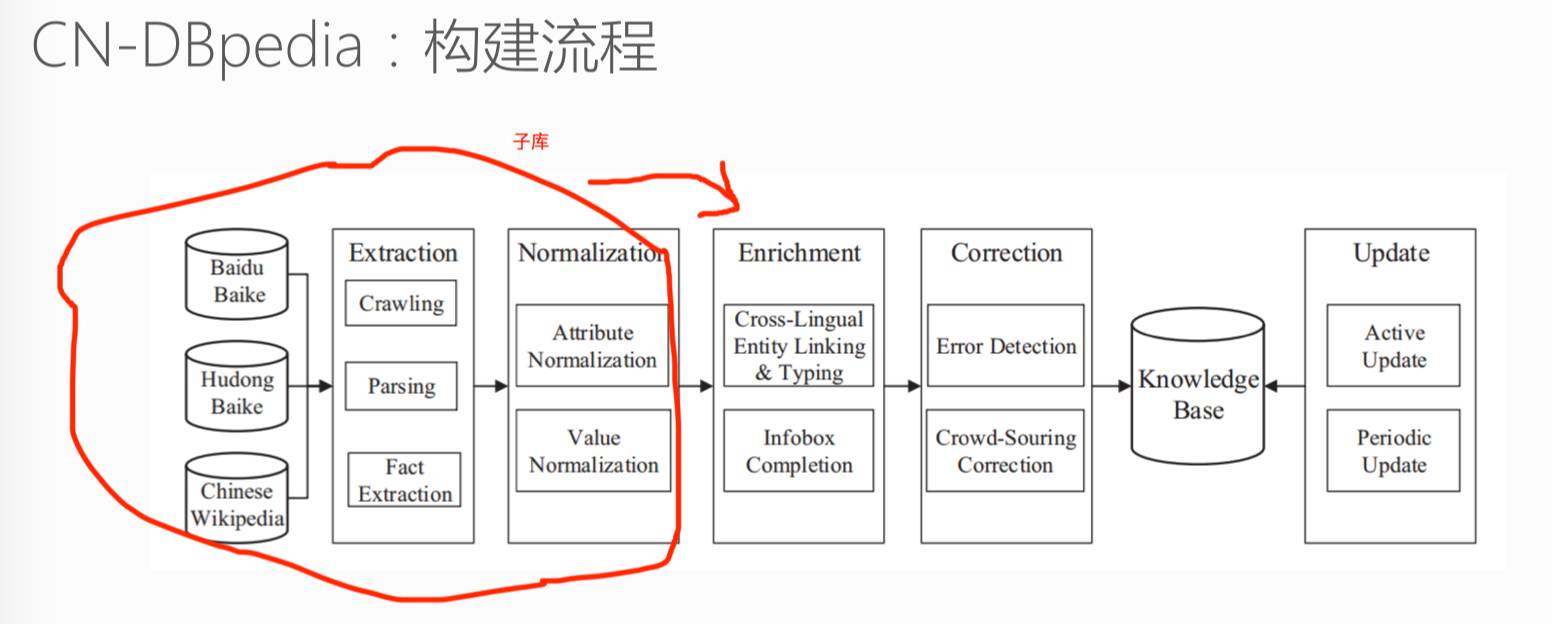
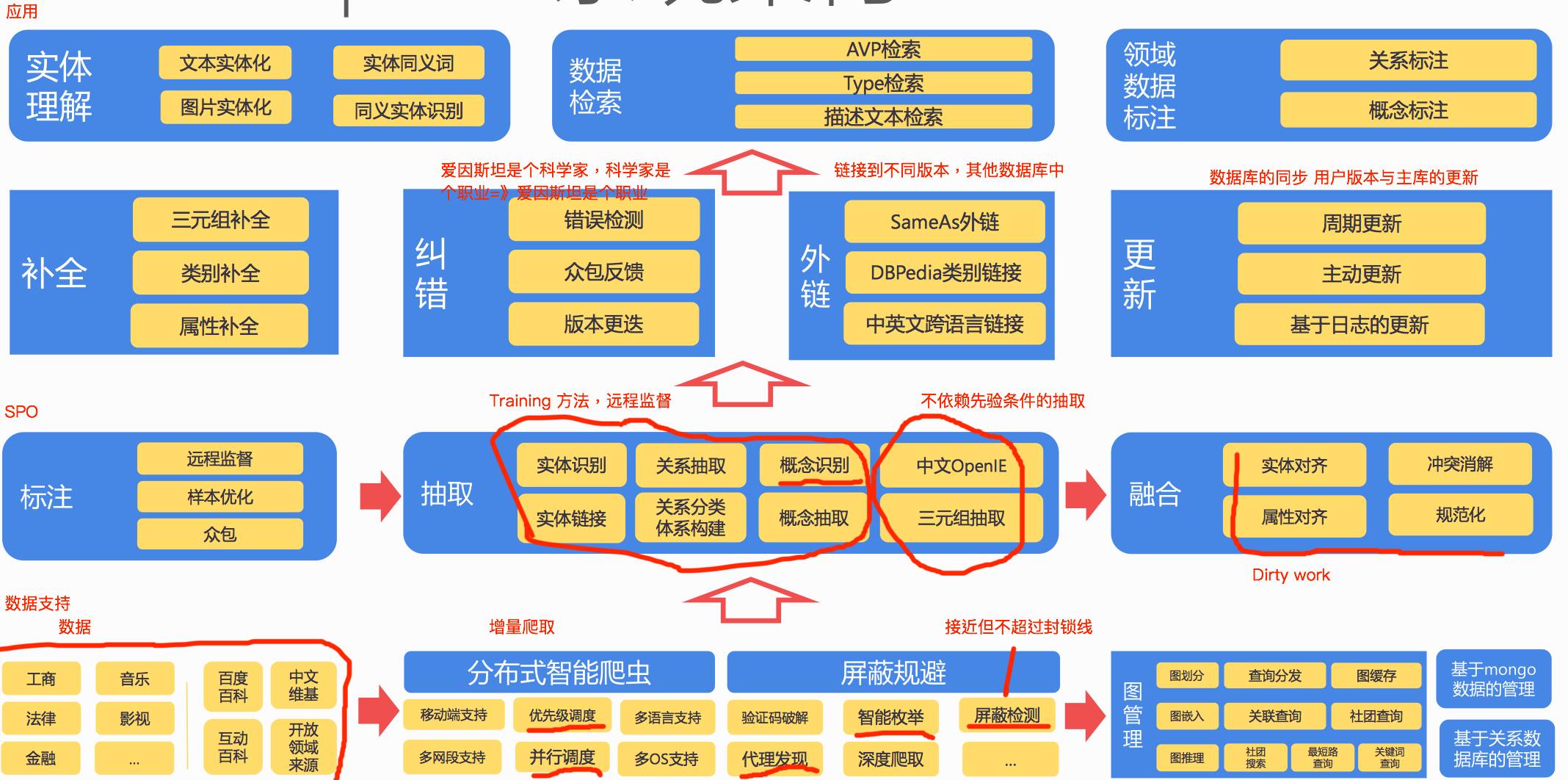
上图分别是 CN-DBpedia 的构建流程和系统架构。知识图谱的构建是一个浩大的工程,从大方面来讲,分为知识获取、知识融合、知识验证、知识计算和应用几个部分,也就是上面架构图从下往上走的一个流程,简单来走一下这个流程。
2. 数据支持层
最底下是知识获取及存储,或者说是数据支持层,首先从不同来源、不同结构的数据中获取知识,CN-DBpedia 的知识来源主要是通过爬取各种百科知识这类半结构化数据。
至于数据存储,要考虑的是选什么样的数据库以及怎么设计 schema。选关系数据库还是 NoSQL 数据库?要不要用内存数据库?要不要用图数据库?这些都需要根据数据场景慎重选择。
CN-DBpedia 实际上是基于 mongo 数据库,参与开发的谢晨昊提到,一般只有在基于特定领域才可能会用到图数据库,就知识图谱而言,基于 json (bson) 的 mongo 就足够了。用到图查询的领域如征信,一般是需要要找两个公司之间的关联交易,会用到最短路径/社区计算等。
schema 的重要性不用多说,高质量、标准化的 schema 能有效降低领域数据之间对接的成本。我们希望达到的效果是,对于任何数据,进入知识图谱后后续流程都是相同的。换言之,对于不同格式、不同来源、不同内容的数据,在接入知识图谱时都会按照预定义的 schema 对数据进行转换和清洗,无缝使用已有元数据和资源。
3. 知识融合层
我们知道,目前分布在互联网上的知识常常以分散、异构、自治的形式存在,另外还具有冗余、噪音、不确定、非完备的特点,清洗并不能解决这些问题,因此从这些知识出发,通常需要融合和验证的步骤,来将不同源不同结构的数据融合成统一的知识图谱,以保证知识的一致性。
所以数据支持层往上一层实际上是融合层,主要工作是对获取的数据进行标注、抽取,得到大量的三元组,并对这些三元组进行融合,去冗余、去冲突、规范化。
第一部分 SPO 三元组抽取,对不同种类的数据用不同的技术提取:
从结构化数据库中获取知识:D2R
难点:复杂表数据的处理
从链接数据中获取知识:图映射
难点:数据对齐
从半结构化(网站)数据中获取知识:使用包装器
难点:方便的包装器定义方法,包装器自动生成、更新与维护
从文本中获取知识:信息抽取
难点:结果的准确率与覆盖率
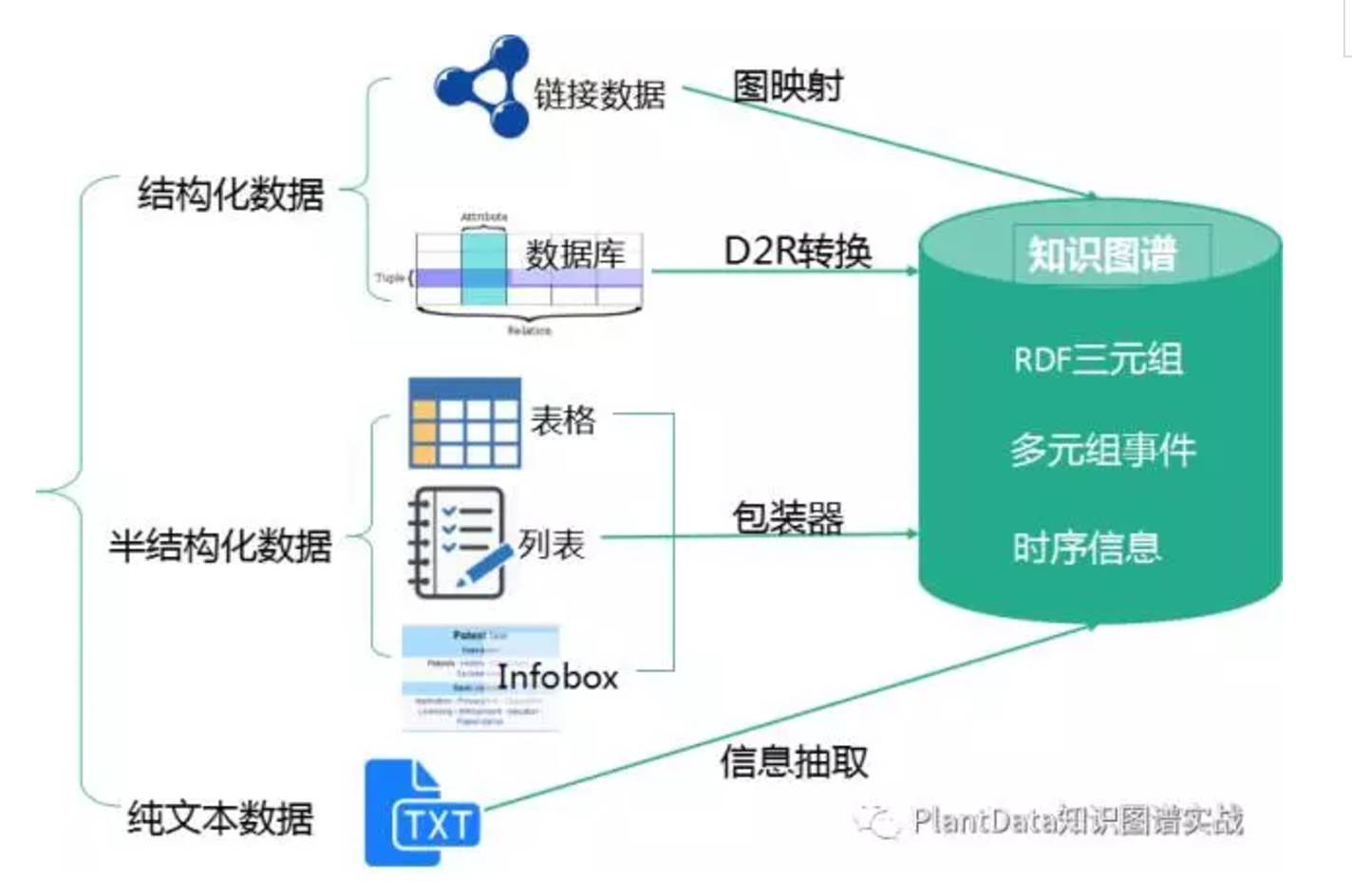
尤其是纯文本数据会涉及到的实体识别、实体链接、实体关系识别、概念抽取 等,需要用到许多自然语言处理的技术,包括但不仅限于分词、词性标注、分布式语义表达、篇章潜在主题分析、同义词构建、语义解析、依存句法、语义角色标注、语义相似度计算等等。
第二部分才到融合,目的是将不同数据源获取的知识进行融合构建数据之间的关联。包括实体对齐、属性对齐、冲突消解、规范化等,这一部分很多都是 dirty work,更多的是做一个数据的映射、实体的匹配,可能还会涉及的是本体的构建和融合。最后融合而成的知识库存入上一部分提到的数据库中。如有必要,也需要如 Spark 等大数据平台提供高性能计算能力,支持快速运算。
知识融合的四个难点:
实现不同来源、不同形态数据的融合
海量数据的高效融合
新增知识的实时融合
多语言的融合
4. 知识验证
再往上一层主要是验证,分为补全、纠错、外链、更新各部分,确保知识图谱的一致性和准确性。
一个典型问题是,知识图谱的构建不是一个静态的过程,当引入新知识时,需要判断新知识是否正确,与已有知识是否一致,如果新知识与旧知识间有冲突,那么要判断是原有的知识错了,还是新的知识不靠谱?这里可以用到的证据可以是权威度、冗余度、多样性、一致性等。如果新知识是正确的,那么要进行相关实体和关系的更新。
5. 知识计算和应用
这一部分主要是基于知识图谱计算功能以及知识图谱的应用。知识计算主要是根据图谱提供的信息得到更多隐含的知识,像是通过本体或者规则推理技术可以获取数据中存在的隐含知识;通过链接预测预测实体间隐含的关系;通过社区计算在知识网络上计算获取知识图谱上存在的社区,提供知识间关联的路径……通过知识计算知识图谱可以产生大量的智能应用如专家系统、推荐系统、语义搜索、问答等。
知识图谱涉及到的技术非常多,每一项技术都需要专门去研究,而且已经有很多的研究成果。Anyway 这章不是来论述知识图谱的具体技术,而是讲怎么做一个 hello world 式的行业知识图谱。
这里讲两个小 demo,一个是爬虫+mysql+d3 的小型知识图谱,另一个是基于 CN-DBpedia+爬虫+PostgreSQL+d3 的”增量型”知识图谱,要实现的是某行业上市公司与其高管之间的关系图谱。
6. 数据获取
第一个重要问题是,我们需要什么样的知识?需要爬什么样的数据?
一般在数据获取之前会先做个知识建模,建立知识图谱的数据模式,可以采用两种方法:一种是自顶向下的方法,专家手工编辑形成数据模式;另一种是自底向上的方法,基于行业现有的标准进行转换或者从现有的高质量行业数据源中进行映射。数据建模都过程很重要,因为标准化的 schema 能有效降低领域数据之间对接的成本。
作为一个简单的 demo,我们只做上市公司和高管之间的关系图谱,企业信息就用公司注册的基本信息,高管信息就用基本的姓名、出生年、性别、学历这些。
然后开始写爬虫,爬虫看着简单,实际有很多的技巧,怎么做优先级调度,怎么并行,怎么屏蔽规避,怎么在遵守互联网协议的基础上最大化爬取的效率,有很多小的 trick,之前博客里也说了很多,就不展开了,要注意的一点是,高质量的数据来源是成功的一半!
来扯一扯爬取建议:
从数据质量来看,优先考虑权威的、稳定的、数据格式规整且前后一致、数据完整的网页
从爬取成本来看,优先考虑免登录、免验证码、无访问限制的页面
爬下来的数据务必保存好爬取时间、爬取来源(source)或网页地址(url)
source 可以是新浪财经这类的简单标识,url 则是网页地址,这些在后续数据清洗以及之后的纠错(权威度计算)、外链和更新中非常重要
企业信息可以在天眼查、启信宝、企查查各种网站查到,信息还蛮全的,不过有访问限制,需要注册登录,还有验证码的环节,当然可以过五关斩六将爬到我们要的数据,然而没这个必要,换别个网站就好。
推荐两个数据来源: 中财网数据引擎和巨潮资讯,其中巨潮资讯还可以同时爬取高管以及公告信息。
看一下数据:

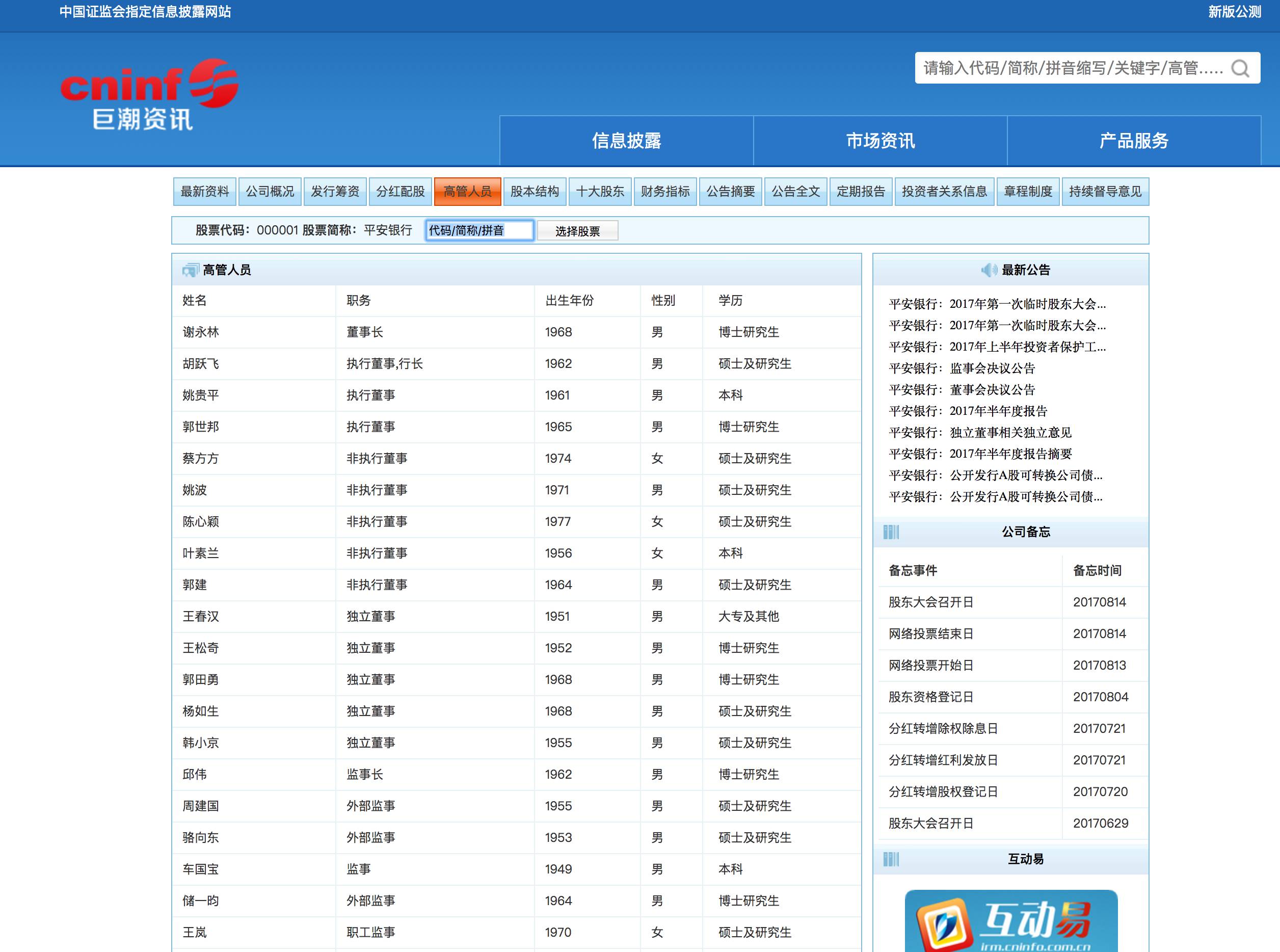
换句话说,我们直接能得到规范的实体(公司、人),以及规范的关系(高管),当然也可以把高管展开,用下一层关系,董事长、监事之类,这就需要做进一步的清洗,也可能需要做关系的对齐。
这里爬虫框架我用的是 scrapy+redis 分布式,每天可以定时爬取,爬下来的数据写好自动化清洗脚本,定时入库。
7. 数据存储
数据存储是非常重要的一环,第一个问题是选什么数据库,这里作为 starter,用的是关系型数据库 MySQL。设计了四张表,两张实体表分别存公司(company)和人物(person)的信息,一张关系表存公司和高管的对应关系(management),最后一张 SPO 表存三元组。
为什么爬下来两张表,存储却要用 4 张表?
一个考虑是知识图谱里典型的一词多义问题,相同实体名但有可能指向不同的意义,比如说 Paris 既可以表示巴黎,也可以表示人名,怎么办?让作为地名的 “Paris” 和作为人的 “Paris” 有各自独一无二的ID。“Paris1”(巴黎)通过一种内在关系与埃菲尔铁塔相联,而 “Paris2”(人)通过取消关系与各种真人秀相联。
这里也是一样的场景,同名同姓不同人,需要用 id 做唯一性标识,也就是说我们需要对原来的数据格式做一个转换,不同的张三要标识成张三1,张三2… 那么,用什么来区别人呢?
拍脑袋想用姓名、生日、性别来定义一个人,也就是说我们需要一张人物表,需要(name, birth, sex)来作 composite unique key 表示每个人。公司也是相同的道理,不过这里只有上市公司,股票代码就可以作为唯一性标识。
Person 表和 company 表是多对多的关系,这里需要做 normalization,用 management 这张表来把多对多转化为两个一对多的关系,(person_id, company_id)就表示了这种映射。
management 和 spo 表都表示了这种映射,为什么用两张表呢?是出于实体对齐的考虑。management 保存了原始的关系,”董事”、监事”等,而 spo 把这些关系都映射成”高管”,也就是说 management 可能需要通过映射才能得到 SPO 表,SPO 才是最终成型的表。
我们知道知识库里的关系其实有两种,一种是属性(property),一种是关系(relation)。那么还有一个问题是 SPO 需不需要存储属性?
最初的想法是实体归实体,属性归属性,SPO 只存实体间的关系,属性由实体表检索得到,然而这样的话需要多表 JOIN,属性增加时扩展性也很差。因此把属性也存到 SPO 表中。在 SPO 表中多加一列 type,来区分这关系是实体间关系还是实体与属性的关系,便于之后的可视化。
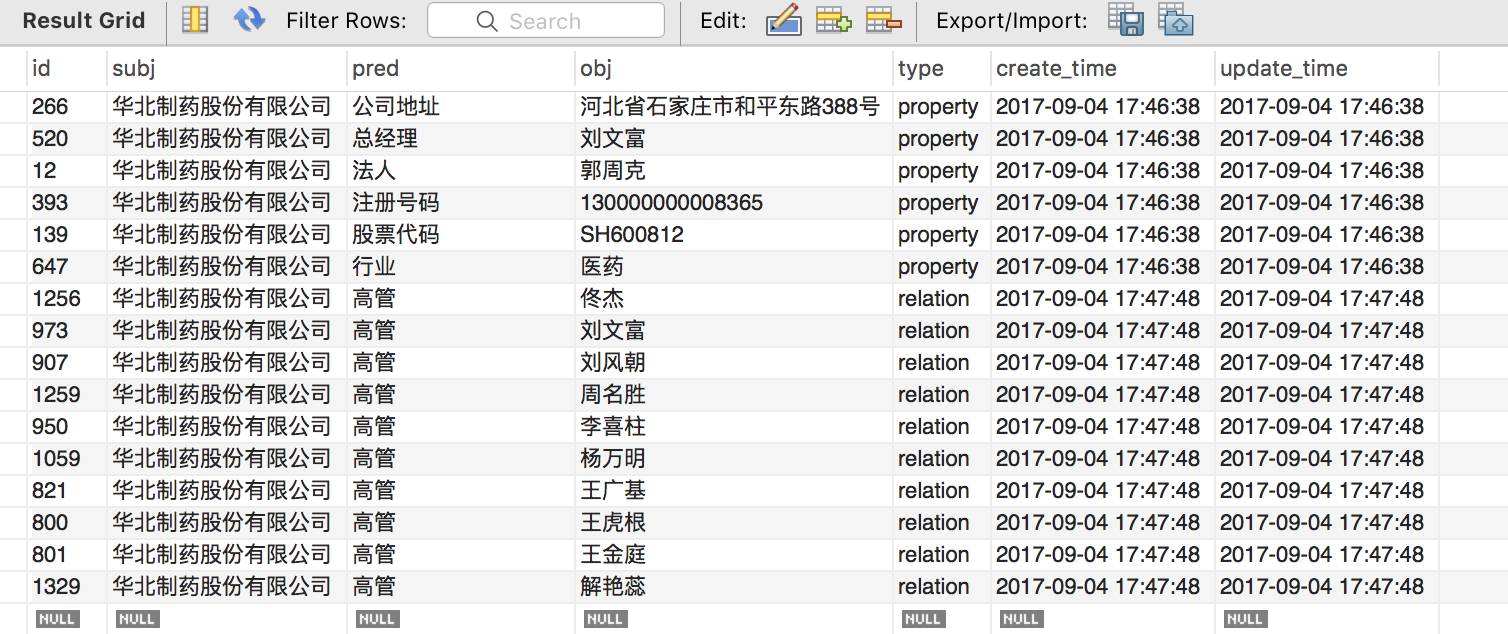
最后要注意的一点是,每条记录要保存创建时间以及最后更新时间,做一个简单的版本控制。
8. 数据可视化
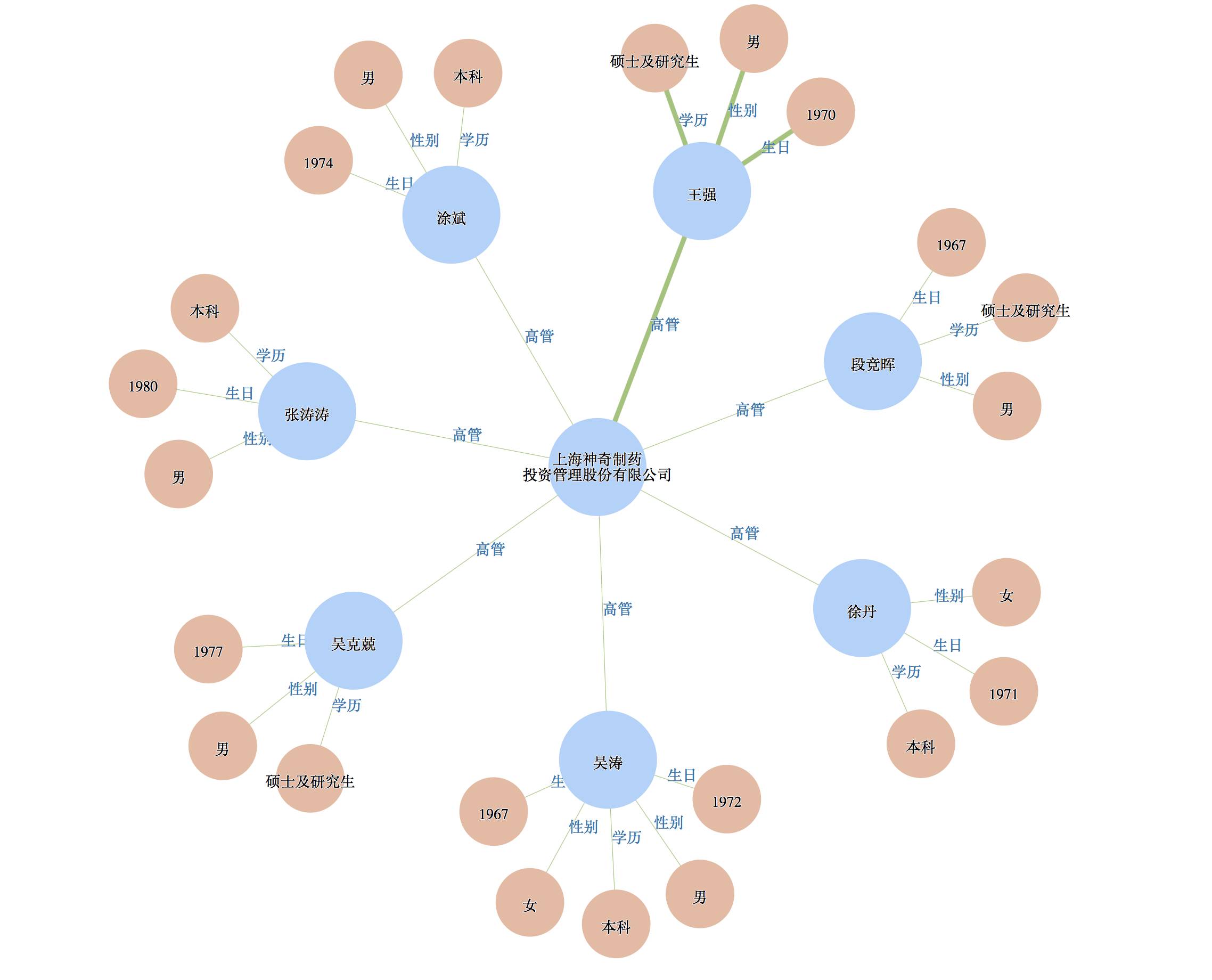
Flask 做 server,d3 做可视化,可以检索公司名/人名获取相应的图谱,如下图。之后会试着更新有向图版本。
9. Start from CN-DBpedia
把 CN-DBpedia 的三元组数据,大概 6500 万条,导入数据库,这里尝试了 PostgreSQL。然后检索了 112 家上市公司的注册公司名称,只有 69 家公司返回了结果,属性、关系都不是很完善,说明了通用知识图谱有其不完整性。
也有可能需要先做一次 mention2entity,可能它的标准实体并不是注册信息的公司名称,不过 API 小范围试了下很多是 Unknown Mention。
做法也很简单,把前面 Start from scratch 中得到的 SPO 表插入到这里的 SPO 表就好了。这么简单?因为这个场景下不用做实体对齐和关系对齐。
10. 拓展
这只是个 hello world 项目,在此基础上可以进行很多有趣的拓展,最相近的比如说加入企业和股东的关系,可以进行企业最终控制人查询(e.g.,基于股权投资关系寻找持股比例最大的股东,最终追溯至自然人或国有资产管理部门)。再往后可以做企业社交图谱查询、企业与企业的路径发现、企业风险评估、反欺诈等等等等。
具体来说:
重新设计数据模型 引入”概念”,形成可动态变化的“概念—实体—属性—关系”数据模型,实现各类数据的统一建模;
扩展多源、异构数据,结合实体抽取、关系抽取等技术,填充数据模型;
展开知识融合(实体链接、关系链接、冲突消解等)、验证工作(纠错、更新等)。
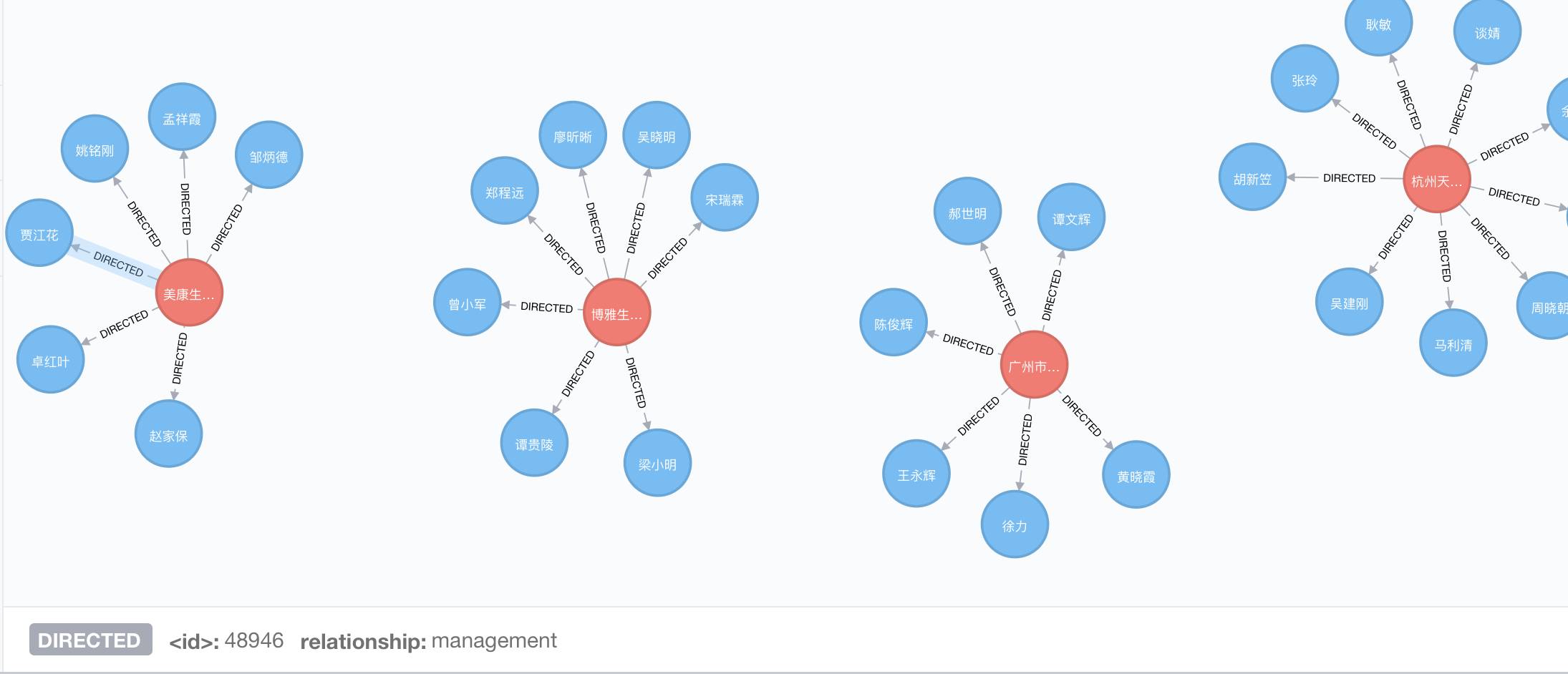
最后补充一下用 Neo4j 方式产生的可视化图,有两种方法。
一是把上面说到的 MySQL/PostgreSQL 里的 company 表和 person 表存成 node,node 之间的关系由 spo 表中 type == relation 的 record 中产生;
二是更直接的,从 spo 表中,遇到 type == property 就给 node(subject) 增加属性 ({predicate:object}),遇到 type == relation 就给 node 增加关系 ((Nsubject) - [r:predicate]-> node(Nobject)),得到下面的图,移动鼠标到相应位置就可以在下方查看到关系和节点的属性。
延展阅读:东南大学漆桂林:知识图谱的应用
作者丨漆桂林
学校丨东南大学教授,博士生导师
研究方向丨语义Web,知识图谱
1. 语义搜索
知识图谱这个概念是谷歌提出的,谷歌做知识图谱自然是跟搜索引擎相关,即提供语义搜索。这里语义搜索跟传统搜索引擎的区别在于搜索的结果不是展示网页,而是展示结构化知识,如下图(图 1)所示:
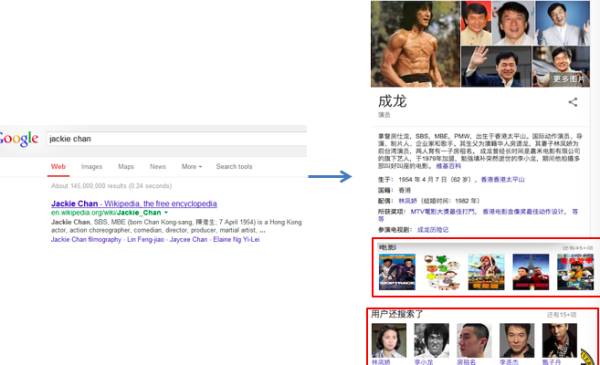
▲ 图1:语义搜索示例
在图 1 中,当用户输入“jackie chan”,搜索引擎可以识别出 jackie chan 其实就是成龙,而且,会给出成龙的各种属性信息,比如说出生日期、国籍、配偶等。这些都是以前基于关键词的检索做不到的,有了知识图谱以后,就可以即问即答了。点击成龙的配偶“林凤娇”,可以直接进入她的知识卡片,见图 2:
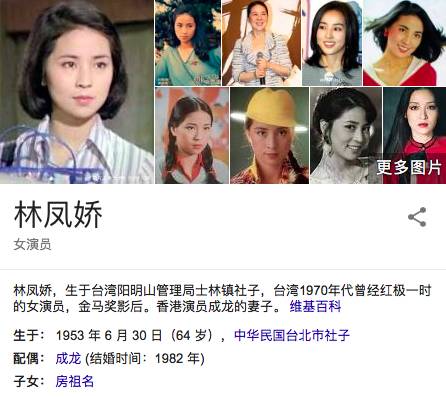
▲ 图2:语义导航示例
然后还可以继续点击房祖名看他的信息。这里我们可以把成龙、林凤娇、房祖名看出图的节点,成龙跟林凤娇之间有一个关系,即夫妻关系,林凤娇跟房祖名之间有一个关系,即母子关系,这就是成龙家庭的一个小的关系图谱。
2. 股票投研情报分析
通过知识图谱相关技术从招股书、年报、公司公告、券商研究报告、新闻等半结构化表格和非结构化文本数据中批量自动抽取公司的股东、子公司、供应商、客户、合作伙伴、竞争对手等信息,构建出公司的知识图谱。
在某个宏观经济事件或者企业相关事件发生的时候,券商分析师、交易员、基金公司基金经理等投资研究人员可以通过此图谱做更深层次的分析和更好的投资决策,比如在美国限制向中兴通讯出口的消息发布之后,如果我们有中兴通讯的客户供应商、合作伙伴以及竞争对手的关系图谱,就能在中兴通讯停牌的情况下快速地筛选出受影响的国际国内上市公司从而挖掘投资机会或者进行投资组合风险控制(图 3)。
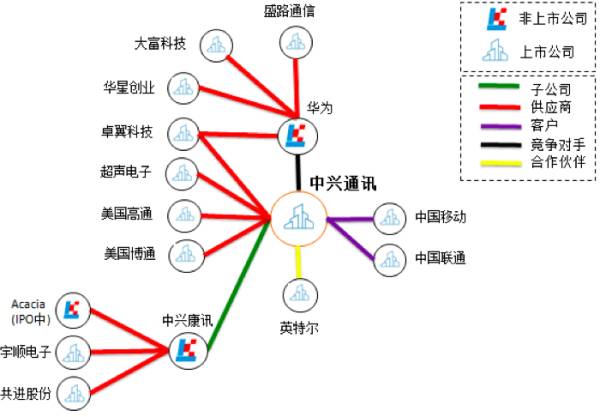
▲ 图3:股票投研情报分析
3. 公安情报分析
通过融合企业和个人银行资金交易明细、通话、出行、住宿、工商、税务等信息构建初步的“资金账户-人-公司”关联知识图谱。同时从案件描述、笔录等非结构化文本中抽取人(受害人、嫌疑人、报案人)、事、物、组织、卡号、时间、地点等信息,链接并补充到原有的知识图谱中形成一个完整的证据链。
辅助公安刑侦、经侦、银行进行案件线索侦查和挖掘同伙。比如银行和公安经侦监控资金账户,当有一段时间内有大量资金流动并集中到某个账户的时候很可能是非法集资,系统触发预警(图 4)。
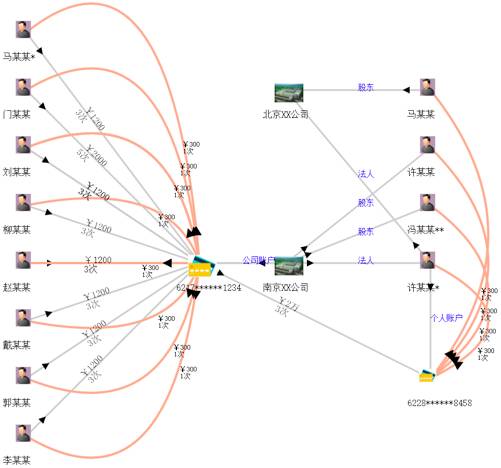
▲ 图4:公安情报分析
4. 反欺诈情报分析
通过融合来自不同数据源的信息构成知识图谱,同时引入领域专家建立业务专家规则。我们通过数据不一致性检测,利用绘制出的知识图谱可以识别潜在的欺诈风险。比如借款人张 xx 和借款人吴 x 填写信息为同事,但是两个人填写的公司名却不一样, 以及同一个电话号码属于两个借款人,这些不一致性很可能有欺诈行为 (图 5)。
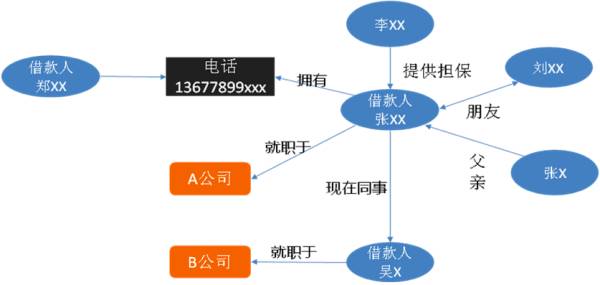
▲ 图5:反欺诈情报分析
5. 面向多源异构关系数据的自然语言问答
现在很多企业都有自己的数据库,而且这些数据库因为不是同一批人构建的,所以维护数据库的成本很高,访问数据库也很不方便,而且数据库之间的关联也很难发现。
通过构建一个本体(该本体可以是从数据库的 schema 抽取后,然后通过人工来修改得到),然后构建本体和数据库的 schema 的映射以及数据之间的匹配,就可以方便的实现数据的集成和数据的语义关联,并且可以利用构建的本体和通过本体集成得到的知识图谱来对自然语言做解析,从而将自然语言查询直接转化为 SQL 去查数据库,并且给出答案,答案可以是用图表的方式来给出。下面给出一个例子(图 6):
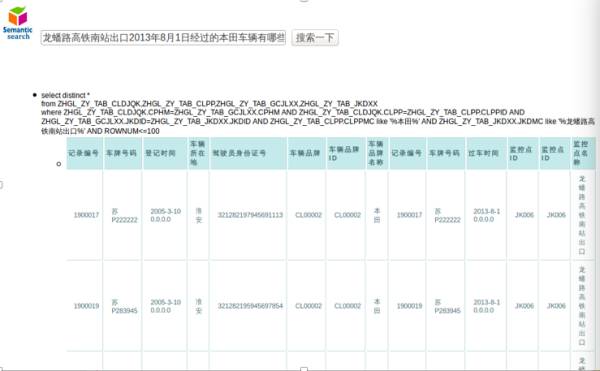
▲ 图6:数据库集成和问答系统示例
如用户提问“龙蟠路高铁南站出口 2013 年 8 月 1 日经过的本田车辆有哪些”,系统直接给出结果。
6. 面向知识图谱的智能问答
最近几年,问答(Question answering)重新受到广泛的关注,主要原因还是因为有 IBM Watson 的出现(见The AI Behind Watson - The Technical Article [1])。Watson虽然号称可以做很多领域,比如说法律有ROSS(ROSS and Watson tackle the law - Watson [2]),但是事实上,Watson 最早提出的时候只是为智力竞赛节目 Jeopardy(Jeopardy! Official Site | Jeopardy.com [3],类似开心辞典和一站到底)定制的,类似下面这种:
Category: General Science
Clue: When hit by electrons, a phosphor gives off electromagnetic energy in this form.
Answer: Light (or Photons)
也就是说,问题会有一些分类,然后出题的人会给出一些暗示(Clue),做题的人或者机器根据这些暗示给出答案。
Watson 的问答系统采用了 wikipedia 和 DBpedia、Yago 等半结构化数据以及图谱数据,但是更多的还是从文本中提取各种证据(evidence)来回答。IBM Watson 系统架构见下图(图 7)。
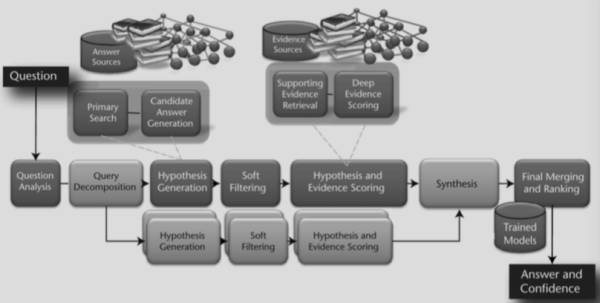
▲ 图7:IBM Watson 系统架构
IBM Watson 系统被神化成可以在任何领域适用,导致只要做问答相关项目,都容易被挑战跟 Watson 有什么差异。事实上,Watson 系统和很多人工智能系统一样,是高度定制化的,当然,相关技术确实是可以用到多个领域,但是需要有一定的变化。
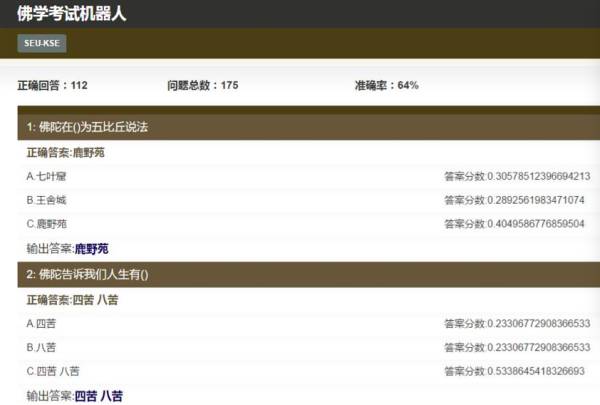
东南大学认知智能研究所借鉴了 Watson 技术,启动了一个佛学考试机器人项目,旨在回答佛学相关问题。为了做这个系统,需要先构建一个佛学知识图谱,通过图谱和佛学相关的网页,利用问答技术解题。考试题目例子如下:
1.僧伽是①涅槃义②和合众③杀贼义。
2.「诸行无常、诸法无我、涅盘寂静」称为①三种无常②三法印③三乘道。
3.人生最大的错误是①杀生②妄语③邪见。
下面是系统的截屏:
7. 辅助判案
知识图谱技术可以帮助我们快速构建一个法律知识图谱,目前还缺乏法律知识图谱的理论工作。跟其他领域的知识图谱相比,法律知识图谱需要考虑法律的逻辑,下面就是一个法律知识图谱的片段:
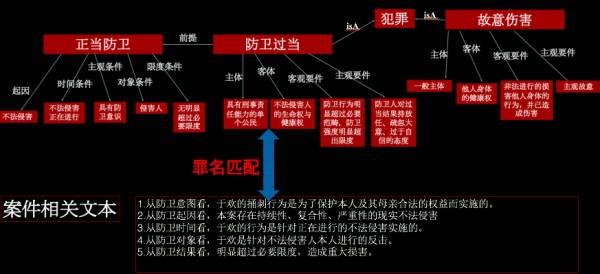
从上面这个例子可以看出,每一个犯罪行为都有主体、客体、主观要件和客观要件,我们就需要从文本中去抽取这些信息,从而形成一个关于犯罪行为的图谱,而通过对海量判决书的挖掘,可以建立犯罪行为之间的关联,比如说,防卫过当和故意伤害之间有一个关联,即误判为的关系。通过这个图谱,给定一个判决书,可以辅助法官判的一个案件是否有误判,是否需要补充信息。
[1] The AI Behind Watson - The Technical Article:
http://www.aaai.org/Magazine/Watson/watson.php
[2] ROSS and Watson tackle the law - Watson:
https://www.ibm.com/blogs/watson/2016/01/ross-and-watson-tackle-the-law/
[3] Jeopardy! Official Site:
https://www.jeopardy.com/
* 本文经授权转自漆桂林老师的知乎专栏
延展阅读:揭开知识库问答KB-QA的面纱2·语义解析篇
作者丨刘大一恒
学校丨四川大学博士生

本期我们从传统方法之一的语义解析(有时也被称为语义分析)开始,以一个经典的语义解析 baseline 方法为例,介绍语义解析如何进行 KB-QA。该方法来自斯坦福 Berant J, Chou A, Frostig R, et al. 的Semantic Parsing on Freebase from Question-Answer Pairs,文章发表于 2013 年的 EMNLP 会议。
1. 什么是语义解析
在揭开知识库问答KB-QA的面纱1·简介篇中我们谈到,知识库 Freebase 由大量的三元组组成,并且这些三元组的实体和实体关系都是形式化的语言,比如 (BarackObama, PlaceOfBirth, Honolulu)。
给定一个自然语言的问题:“Where was Obama born?”我们面临的第一个挑战,就是如何建立问题到知识库的映射?
语义解析 KB-QA 的思路是通过对自然语言进行语义上的分析,转化成为一种能够让知识库“看懂”的语义表示,进而通过知识库中的知识,进行推理(Inference)查询(Query),得出最终的答案。
简而言之,语义解析要做的事情,就是将自然语言的问题,转化为一种能够让知识库“看懂”的语义表示,这种语义表示即逻辑形式(Logic Form)。
2. 什么是逻辑形式
为了能够对知识库进行查询,我们需要一种能够“访问”知识库的逻辑语言,Lambda Dependency-Based Compositional Semantics (Lambda-DCS) 是一种经典的逻辑语言,它用于处理逻辑形式(在实际操作中,逻辑形式会转化 SPARQL query,可以在 Virtuoso engine 上对 Freebase 进行查询)。如果我们把知识库看作是一个数据库,那么逻辑形式(Logic Form)则可以看作是查询语句的表示。
我们用表示一个逻辑形式,用表示知识库,表示实体,表示实体关系(有的也称谓语或属性)。简单而言,逻辑形式分为一元形式(unary)和二元形式(binary)。对于一个一元实体,我们可以查询出对应知识库中的实体,给定一个二元实体关系,可以查到它在知识库中所有与该实体关系相关的三元组中的实体对。并且,我们可以像数据库语言一样,进行连接 Join,求交集 Intersection 和聚合 Aggregate(如计数,求最大值等等)操作。具体来说,逻辑形式有以下形式和操作:

有了上面的定义,我们就可以把一个自然语言问题表示为一个可以在知识库中进行查询的逻辑形式,比如对于问句“Number of dramas starring Tom Cruise?”它对应的逻辑形式是:
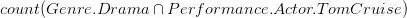
当自然语言问题转化为逻辑形式之后,通过相应的逻辑语言(转化为 SPARQL query)查询知识库就可以得到答案。那么,语义解析要如何把自然语言问题正确地转化为相应的逻辑形式呢?
3. 语义解析 KB-QA 的方法框架
语法分析的过程可以看作是自底向上构造语法树的过程,树的根节点,就是该自然语言问题最终的逻辑形式表达。整个流程可以分为两个步骤:
1. 词汇映射:即构造底层的语法树节点。将单个自然语言短语或单词映射到知识库实体或知识库实体关系所对应的逻辑形式。我们可以通过构造一个词汇表(Lexicon)来完成这样的映射。
2. 构建(Composition):即自底向上对树的节点进行两两合并,最后生成根节点,完成语法树的构建。这一步有很多种方法,诸如构造大量手工规则,组合范畴语法(Combinatory Categorical Grammars,CCG)等等,而我们今天要讲的这篇论文,采用了最暴力的方法,即对于两个节点都可以执行上面所谈到的连接 Join,求交 Intersection,聚合 Aggregate 三种操作,以及这篇文章独创的桥接 Bridging 操作(桥接操作的具体方式稍后会提到)进行结点合并。显然,这种合并方式复杂度是指数级的,最终会生成很多棵语法树,我们需要通过对训练数据进行训练,训练一个分类器,对语法树进行筛选。
自然语言转化为逻辑形式的流程如下图所示:
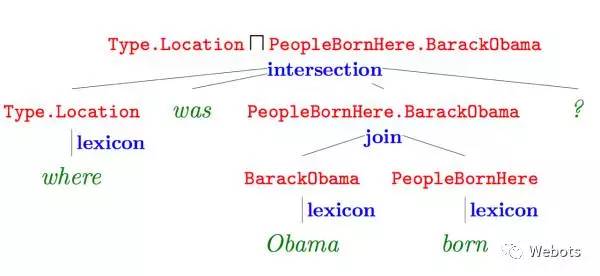
上图红色部分即逻辑形式,绿色部分 where was Obama born 为自然语言问题,蓝色部分为词汇映射(Lexicon)和构建(Composition)使用的操作,最终形成的语义解析树的根节点即语义解析结果。
接下来,我们还剩最后三个待解决的问题,如何训练分类器?如何构建词汇表?什么是桥接操作?
训练分类器
分类器的任务是计算每一种语法分析结果 d(Derivation)的概率,作者通过 discriminative log-linear model 进行 modeling,使用 Softmax 进行概率归一化,公式如下:
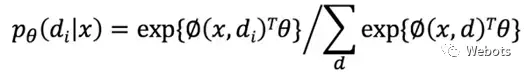
其中 x 代表自然语言问题,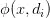
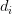
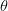
对于训练数据问题-答案对 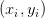
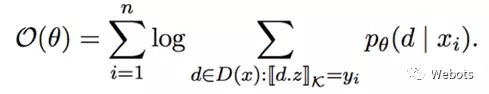
可以看出特征向量的训练实际上是一种弱监督训练(准确的说是一种远程监督,DistantSupervison)。
构建词汇表
词汇表即自然语言与知识库实体或知识库实体关系的单点映射,这一操作也被称为对齐(Alignment)。我们知道自然语言实体到知识库实体映射相对比较简单,比如将“Obama was also born in Honolulu.”中的实体 Obama 映射为知识库中的实体 BarackObama,可以使用一些简单的字符串匹配方式进行映射。
但是要将自然语言短语如“was also born in”映射到相应的知识库实体关系,如 PlaceOfBirth, 则较难通过字符串匹配的方式建立映射。怎么办呢?没错,我们可以进行统计。直觉上来说,在文档中,如果有较多的实体对(entity1,entity2)作为主语和宾语出现在 was also born in 的两侧,并且,在知识库中,这些实体对也同时出现在包含 PlaceOfBirth 的三元组中,那么我们可以认为“was also born in”这个短语可以和 PlaceOfBirth 建立映射。
比如(“Barack Obama”,“Honolulu”),(“MichelleObama”,“Chicago”)等实体对在文档中经常作为“was also born in”这个短语的主语和宾语,并且它们也都和实体关系 PlaceOfBirth 组成三元组出现在知识库中。
有了这样的直觉,我们再来看看这篇文章是怎么构建词汇表的,利用 ReVerbopen IE system 在 ClueWeb09(注:该数据集由卡耐基梅隆学校在 09 年构建,还有一个 12 年的版本,ClueWeb12)上抽取 15 millions 个三元组构成一个数据集,如 (“Obama”, “was also born in”, “August 1961”),可以看出三元组的实体和关系都是自然语言的形式,取出其中的一个三元组子集,对里面的每一个三元组的主语实体和宾语实体通过字符匹配的方式替换为知识库的实体,并使用 SUTime 对数据进行归一化。
如(“Obama”, “was also born in”, “August 1961”) 经过预处理后转化为 (BarackObama, “was also born in”, 1961-08)。
接着我们对每一个三元组中的自然语言短语两边的实体对(entity1,entity2)进行统计,注意,由于自然语言短语 r1 知识库实体关系 r2 的对应关系是多对多的,比如“was also born in”可能对应 PlaceOfBirth,也可能对应 DateOfBrith,我们需要对每一个 r1 进行区分,我们可以通过知识库查询到每一个实体的类型(type),比如 1961-08 的类型是 date 而 honolulu 的类型是 place,我们对 r1 两边的实体类型进行查询可以得到主语实体的类型 t1 和宾语实体的类型 t2,因此 r1 可以进一步表示为 r[t1,t2],我们对其所在三元组两边的实体进行统计,得到实体对集合F(r[t1,t2])。
同样的,通过对知识库进行统计,对每一个知识库三元组中的实体关系 r2 也统计其两边的实体,可以得到实体对集合 F(r2),通过比较集合 F(r[t1,t2]) 和集合 F(r2) 类似 Jaccard 距离(集合交集元素数目比集合并集元素个数)这样的特征来确定是否建立词汇映射,如下图所示:
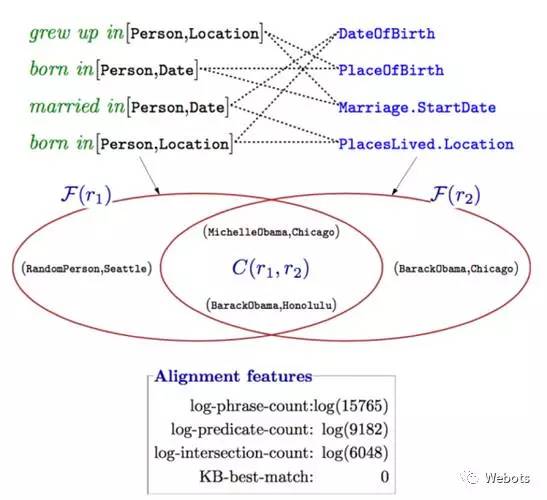
图中绿色字体为 r1,蓝色字体为 r2。作者定义了词汇映射操作的三种特征(用于训练分类器),对齐特征(Alignmentfeatures),文本相似度特征(Textsimilarity features),和词汇化特征(Lexicalizedfeatures),具体内容如下表所示:
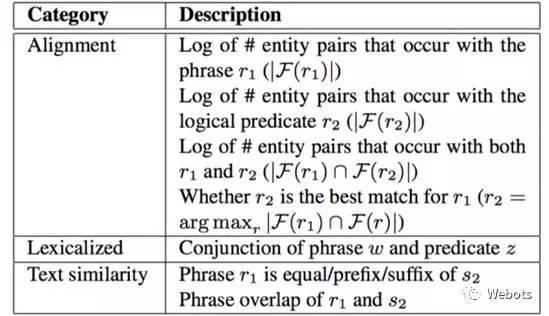
其中文本相似度特征中的 s2 指 r2 的 freebase name。
在实际使用中,我们可以通过词性标注(POS)和命名实体识别(NER)来确定哪些短语和单词需要被词汇映射(Lexicon),从而忽略对一些 skippedwords 进行词汇映射。并且,作者还建立了 18 种手工规则,对问题词(questionwords)进行逻辑形式的直接映射,如“where,how many”映射为 Type.Location 和 Count。
桥接操作
完成词汇表的构建后,仍然存在一些问题。比如,对于 go,have,do 这样的轻动词(light verb)难以直接映射到一个知识库实体关系上,其次,有些知识库实体关系极少出现,不容易通过统计的方式找到映射方式,还有一些词比如 actress 实际上是两个知识库实体关系进行组合操作后的结果 (actor ∩ gender.female)。
作者最后提到这个问题有希望通过在知识库上进行随机游走 Random walk 或者使用马尔科夫逻辑 Markov logic 解决,因此我们需要一个补丁,需要找到一个额外的二元关系来将当前的逻辑形式连接起来,那就是桥接。
这里举个具体的例子,比如“Which college did Obama go to?” 假设“Obama” 和 “college” 可被词汇映射映射为 BarackObama 和 Type.University,这里"go to" 却难以找到一个映射,事实上,这里我们需要去寻找一个中间二元关系(即Education)使得上面的句子可以被解析为 (Type.University ∩ Education.BarackObama),如下图所示:
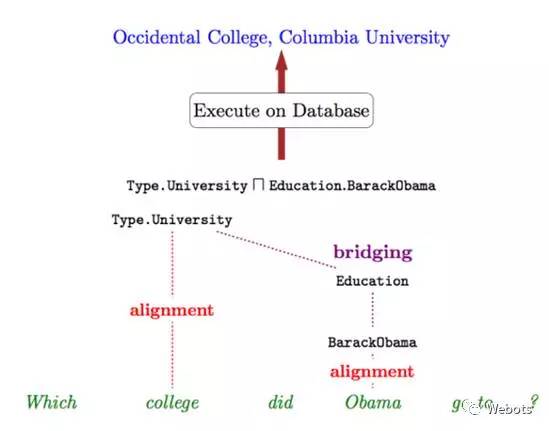
具体来说,给定两个类型(type)分别为 t1 和 t2 的一元逻辑形式 z1 和 z2,我们需要找到一个二元逻辑形式 b,在 b 对应的实体对类型满足 (t1,t2) 的条件下生成逻辑形式 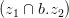
同样的,作者也为桥接操作定义了相应的特征(为了分类器的训练),定义如下表所示:

对于构建(composition)的其他三种操作,连接Join,求交集Intersection和聚合Aggregate,作者也定义了相应的特征(为了分类器的训练),如下表所示:

至此,语法树的构建,分类器的训练,和分类器的输入——特征向量的构造方式我们都已经介绍完毕。最后我们再简单的介绍一下实验和实验结果。
4. 实验结果
由于语义解析树的构建方式是指数级的,因此,在训练和测试的时候,作者执行了标准的自底向上的集束分析器(Beam-based bottom-up parser)。在这篇论文之前,KB-QA 流行的数据集是由 Cai and Yates (2013) 构建的 Free917,该数据集只包含了 917 组问题答案对,因此,作者构建了一个更大的 benchmark 数据集 WebQuestion,包含了 5810 组问题答案对,该数据集的构建方式我在揭开知识库问答 KB-QA 的面纱·简介篇中进行了简单介绍。
作者测试了仅使用Alignment和Bridging以及都使用下的正确率,如下表所示:
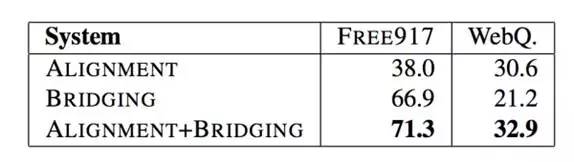
作者该论文的语义解析器 Sempre 进行了开源,感兴趣的朋友可以查阅该项目资料。
我们可以看出传统的语义解析方法还是存在大量的手工规则,也涉及到了一些 linguistic 的知识,对于没有传统 NLP 先验知识的朋友可能理解起来会稍微困难一些。
最后,让我们再思考一下该方法有些什么缺陷?
首先,词汇映射是整个算法有效(work)的基点,然而这里采用的词汇映射(尤其是关系映射)是基于比较简单的统计方式,对数据有较大依赖性。最重要的是,这种方式无法完成自然语言短语到复杂知识库关系组合的映射(如 actress 映射为 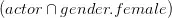
其次,在答案获取的过程中,通过远程监督学习训练分类器对语义树进行评分,注意,这里的语义树实际的组合方式是很多的,要训练这样一个强大的语义解析分类器,需要大量的训练数据。我们可以注意到,无论是 Free917 还是 WebQuestion,这两个数据集的问题-答案对都比较少。
* 本文经授权转载自微信公众号:智言科技AI(zhiyan_AI)

新一代技术+商业操作系统:
AI-CPS OS
在新一代技术+商业操作系统(AI-CPS OS:云计算+大数据+物联网+区块链+人工智能)分支用来的今天,企业领导者必须了解如何将“技术”全面渗入整个公司、产品等“商业”场景中,利用AI-CPS OS形成数字化+智能化力量,实现行业的重新布局、企业的重新构建和自我的焕然新生。
AI-CPS OS的真正价值并不来自构成技术或功能,而是要以一种传递独特竞争优势的方式将自动化+信息化、智造+产品+服务和数据+分析一体化,这种整合方式能够释放新的业务和运营模式。如果不能实现跨功能的更大规模融合,没有颠覆现状的意愿,这些将不可能实现。
领导者无法依靠某种单一战略方法来应对多维度的数字化变革。面对新一代技术+商业操作系统AI-CPS OS颠覆性的数字化+智能化力量,领导者必须在行业、企业与个人这三个层面都保持领先地位:
重新行业布局:你的世界观要怎样改变才算足够?你必须对行业典范进行怎样的反思?
重新构建企业:你的企业需要做出什么样的变化?你准备如何重新定义你的公司?
重新打造自己:你需要成为怎样的人?要重塑自己并在数字化+智能化时代保有领先地位,你必须如何去做?
AI-CPS OS是数字化智能化创新平台,设计思路是将大数据、物联网、区块链和人工智能等无缝整合在云端,可以帮助企业将创新成果融入自身业务体系,实现各个前沿技术在云端的优势协同。AI-CPS OS形成的数字化+智能化力量与行业、企业及个人三个层面的交叉,形成了领导力模式,使数字化融入到领导者所在企业与领导方式的核心位置:
精细:这种力量能够使人在更加真实、细致的层面观察与感知现实世界和数字化世界正在发生的一切,进而理解和更加精细地进行产品个性化控制、微观业务场景事件和结果控制。
智能:模型随着时间(数据)的变化而变化,整个系统就具备了智能(自学习)的能力。
高效:企业需要建立实时或者准实时的数据采集传输、模型预测和响应决策能力,这样智能就从批量性、阶段性的行为变成一个可以实时触达的行为。
不确定性:数字化变更颠覆和改变了领导者曾经仰仗的思维方式、结构和实践经验,其结果就是形成了复合不确定性这种颠覆性力量。主要的不确定性蕴含于三个领域:技术、文化、制度。
边界模糊:数字世界与现实世界的不断融合成CPS不仅让人们所知行业的核心产品、经济学定理和可能性都产生了变化,还模糊了不同行业间的界限。这种效应正在向生态系统、企业、客户、产品快速蔓延。
AI-CPS OS形成的数字化+智能化力量通过三个方式激发经济增长:
创造虚拟劳动力,承担需要适应性和敏捷性的复杂任务,即“智能自动化”,以区别于传统的自动化解决方案;
对现有劳动力和实物资产进行有利的补充和提升,提高资本效率;
人工智能的普及,将推动多行业的相关创新,开辟崭新的经济增长空间。
给决策制定者和商业领袖的建议:
超越自动化,开启新创新模式:利用具有自主学习和自我控制能力的动态机器智能,为企业创造新商机;
迎接新一代信息技术,迎接人工智能:无缝整合人类智慧与机器智能,重新
评估未来的知识和技能类型;
制定道德规范:切实为人工智能生态系统制定道德准则,并在智能机器的开
发过程中确定更加明晰的标准和最佳实践;
重视再分配效应:对人工智能可能带来的冲击做好准备,制定战略帮助面临
较高失业风险的人群;
开发数字化+智能化企业所需新能力:员工团队需要积极掌握判断、沟通及想象力和创造力等人类所特有的重要能力。对于中国企业来说,创造兼具包容性和多样性的文化也非常重要。
子曰:“君子和而不同,小人同而不和。” 《论语·子路》云计算、大数据、物联网、区块链和 人工智能,像君子一般融合,一起体现科技就是生产力。
如果说上一次哥伦布地理大发现,拓展的是人类的物理空间。那么这一次地理大发现,拓展的就是人们的数字空间。在数学空间,建立新的商业文明,从而发现新的创富模式,为人类社会带来新的财富空间。云计算,大数据、物联网和区块链,是进入这个数字空间的船,而人工智能就是那船上的帆,哥伦布之帆!
新一代技术+商业操作系统AI-CPS OS作为新一轮产业变革的核心驱动力,将进一步释放历次科技革命和产业变革积蓄的巨大能量,并创造新的强大引擎。重构生产、分配、交换、消费等经济活动各环节,形成从宏观到微观各领域的智能化新需求,催生新技术、新产品、新产业、新业态、新模式。引发经济结构重大变革,深刻改变人类生产生活方式和思维模式,实现社会生产力的整体跃升。
产业智能官 AI-CPS
用“新一代技术+商业操作系统”(AI-CPS OS:云计算+大数据+物联网+区块链+人工智能),在场景中构建状态感知-实时分析-自主决策-精准执行-学习提升的认知计算和机器智能;实现产业转型升级、DT驱动业务、价值创新创造的产业互联生态链。


长按上方二维码关注微信公众号: AI-CPS,更多信息回复:
新技术:“云计算”、“大数据”、“物联网”、“区块链”、“人工智能”;新产业:“智能制造”、“智能驾驶”、“智能金融”、“智能城市”、“智能零售”;新模式:“案例分析”、“研究报告”、“商业模式”、“供应链金融”、“财富空间”。
本文系“产业智能官”(公众号ID:AI-CPS)收集整理,转载请注明出处!
版权声明:由产业智能官(公众号ID:AI-CPS)推荐的文章,除非确实无法确认,我们都会注明作者和来源。部分文章推送时未能与原作者取得联系。若涉及版权问题,烦请原作者联系我们,与您共同协商解决。联系、投稿邮箱:erp_vip@hotmail.com





