在警察领域高级人脸识别技术的一致性

【导读】来自英国伯恩茅斯大学实验室的研究人员作出的贡献。近年来,人们对具有较高识别能力的人越来越感兴趣。然而,对这些人的识别主要依赖于一次单一的人脸记忆测试的标准性能。目前调查旨在审查30名警察的高级人脸识别技能的一致性,既包括进入同一过程的测试,也包括进入人脸处理不同组成部分的测试之间的一致性。各相关指标的总体绩效指标被发现,以孤立的测试分数确定不同的优秀表现。此外,不同表现的目标现值和目标缺席指数,表明信号检测措施是最有用的绩效指标。最后,观察到优越的记忆和匹配性能之间的分离。因此,超级识别器筛选程序应该包括总结相关测试多次尝试的总体指数,允许个人在不同(有时非常具体)的任务上进行高度排序。

目前的研究旨在检验高级人脸识别技能的一致性,无论是在同一过程的测试中,还是在评估不同过程的测试之间。
本次,评估了一组30名警察的表现,他们此前曾接受过超级识别筛选,在两项测试中至少一项超过了宽松的标准:CFMT测试和人脸匹配任务。这使我们能够评估那些明显精通记忆和匹配的人的人脸识别一致性,以及在这两个过程中只有一个过程具有便利作用的人的人脸识别一致性。

所有警官都完成了五项测试:一项新的人脸记忆测试,该测试采用了cfmt范式,包括目标缺席试验,这是人脸匹配任务的三个新版本,以及一种测试,要求参与者在同时呈现的显示人群的图像(“人群”任务)中决定是否存在一个复合目标脸(由整体合成系统生成)。
我们包括了人群测试,以检查是否熟练的人脸识别技能,如上述两种测试中的任何一种,延伸到一个新颖的,更真实的世界警务任务。所有测试都经过校准,以检测光谱顶端的性能(允许至少三个与控制均值的标准差),使用外观不同的自然人脸图像。从参与者超过标准绩效的次数和总体指数得分来考虑相关测试的一致性。
-
模型记忆测试
这一新的人脸记忆测试是对CFMT的一种适应,使用了在不同的日子和不同的环境中捕捉到的每一个人的自然彩色照片(如下图)。

图像被裁剪,以显示从颈部以上的脸(图像大小是8厘米高6厘米宽)。模型记忆测试(MMT)的完整描述可以在Bate等人提出的论文中找到。(Bate, S., Frowd, C., Bennetts, R., Hasshim, N., Murray, E., Bobak, A. K., Richards, S. (2018). Applied screening tests for the detection of superior face recognition. Cognitive Research: Principals and Implications. https://doi.org/10.1186/s41235‐018‐0116‐5, 3)
简单地说,测试从一个与CFMT相似的编码过程开始:对于六个目标面孔中的每一个,三个不同的人图像(在不同的日期和不同的设置下拍摄)连续显示3秒,然后立即进行三个测试试验。在每个测试试验中都会显示三个面孔:一个编码图像和两个错误的。在cfmt中,编码阶段以对六个目标面的20s回顾结束,同时呈现每个人的一个新的正面图像。90个测试试验(45个目标存在)随后以随机顺序呈现。
在测试的前半部分,三分之一包含的图像更接近于编码阶段使用的图像,而在屏幕中断后呈现的图像则在更具挑战性的条件下显示目标(例如,有更多的胡须,或者面部被附件或视点的大变化遮住)。图像保留在屏幕上,直到做出响应,并且没有时间限制。
参与者可以针对每一次试验做出目标在场或目标缺席的反应。使用指示目标在三位一体中目标位置的相应数字键(1-3)激发目标当前响应,而0键表示缺少目标的响应。在这个测试中,有五种类型的响应是可能的。对于目标目前的试验,参与者可以正确识别目标脸(点击),他们可能会错误地引发目标缺失的反应(失误),或者他们可以错误地识别一个错误者的脸(错误识别)。在没有目标的试验中,参与者可以引起正确的反应(正确的拒绝)或错误地识别错误者的脸(假阳性)。我们记录了每个参与者的每一次反应,并总结了点击次数和正确的拒绝次数,以计算出一个整体的准确性评分。
-
配对匹配实验
为这项调查开发了三个新的项目管理小组。当(A)人脸在两幅图像中发生严重变化(即45°以上)时,(B)演员只在一幅图像中戴眼镜时,这些参与者是否有能力同时匹配一对男性白种人脸,而且(C)演员在一张照片中有胡须,但在另一张照片中剃得很干净(见下图)。

这三个区块中的每一个都包含48项试验,其中24项在身份上匹配,其余的则显示了两个不同的个体。所有图片都是从谷歌图像搜索中下载的,并被裁剪成从颈部向上显示整张脸。根据彼此感知到的相似性对不匹配的人脸进行配对,并将所有图像调整为10cm宽和14cm高。
参与者以一个平衡的顺序完成了这三个块,每个块内的试验被随机化。为了确保有效性,在作出反应之前,会显示刺激,并且没有规定时限。参与者按下键来引出“相同”或“不同”的反应。以点击率(正确的“相同”回答的次数)和正确的拒绝次数(正确的“不同的”回答的次数)来计算分数,并将其加在一起以保证整体的准确性。
人群匹配试验
最后一次测试旨在复制一个非常具体的警务场景,即警官有一个综合目标脸(使用EvoFIT:一个综合系统生成),他们必须在人群中找到这个人。
简而言之,最初的一组参与者按照预先存在的程序生成了目标复合刺激。这一过程开始时,参与者尽可能详细地描述指定的目标脸(一半来自最后测试中使用的人群图像,另一半来自最终测试中没有使用的人群图像),而不进行猜测。
实验者使用特征描述标签将这一信息记录在人脸描述表上。然后向参与者展示一个与年龄和性别相适应的数据库,显示一系列面部的内部区域。参与者选择的面孔与目标的整体外观最匹配;这些面孔被组合在一起,选择过程重复进行。
然后,他们选择了最佳匹配项目,并使用“整体”(针对脸部的年龄、体重和总体外观)和“形状”(处理面部特征的大小和位置)工具对其进行了改进。最后,选择了最匹配的外部特征集(头发、耳朵和颈部),参与者最后有机会使用相同的整体和形状工具来改善面部。
最后实验选择了32种复合材料,包括32项试验,参与者同时在屏幕顶部观看目标合成脸,并在下面的图片中显示25-40人在自然背景下(例如,音乐会或体育活动的观众;见下图)。

组合人脸高3cm,宽2cm,人群图像高9cm,宽13cm。参与者被要求决定目标面孔是否存在于每一人群中,按下键盘上的一个键来做出反应。试验按随机顺序显示,没有时间限制。命中和正确的拒绝被计算和总结整体准确性。
这项调查的主要目的是检查不同测试之间的性能一致性,这些测试涉及相同的过程,以及度量不同进程的测试之间。由于现有的工作表明了在超级识别中目标-现在和目标-缺席性能的差异,分别输入了每个测试的命中和正确拒绝的数据。主成分分析(PCA)的初始特征值表明,前三个因子解释了方差的33.57%、23.39%和10.71%,其余8个因子的特征值小于1。2、3、4、5和6个因子的解分别使用因子负荷矩阵的varimax和oblimin旋转进行了检验。5因素oblimin解决方案(解释83.21%的方差)是首选的,因为它提供了最好的定义因子结构(见下表)。
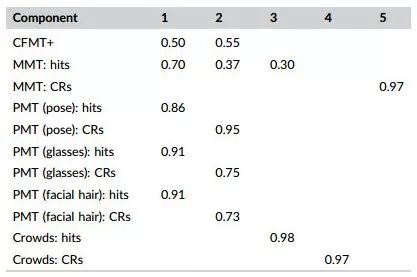
第一个因素来自于目标当前的措施:命中了PMT的三个块,命中了MMT,以及CFMT的总体性能。第二个因素来自三个匹配块的正确的拒绝分数,以及来自CFMT的总体分数。在人群测试中,第三和第四个因素分别代表了成功和正确的拒绝;第五个因素对MMT的正确拒绝有很高的负载。下表显示了一个完整的相关矩阵。
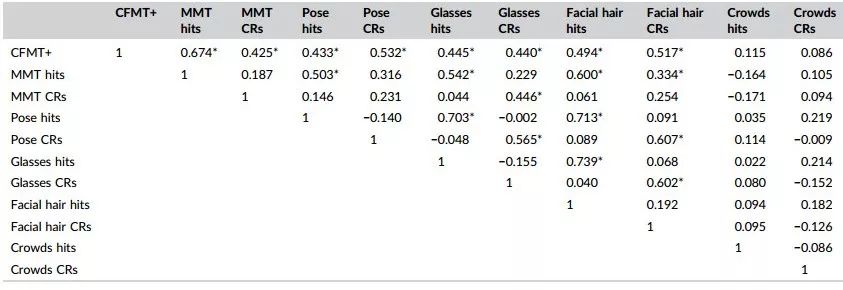
总之,这一分析表明:(A)两种目标-现在的记忆测量是相关的,但目标-缺失记忆性能应该独立考虑;(B)匹配测试的三个块是相关的,但目标-现在和目标-缺失的测试应该再次被独立地考虑;而且(C)在人群测试中,目标-现在和目标-缺失的表现都不同于所有其他的措施。这些调查结果被用来制定适当的指数,用以评估相关和无关措施之间业绩的一致性。
人脸记忆性能一致性
在MMT上的总正确百分比是通过总结命中和正确的拒绝来计算的。每项措施的标准从控制平均数确定为1.96 SDS(见下表)。警官得分在53.33%~95.56%之间,有14人超标。这些人员中有11人按照CFMT的自由纳入标准也优于对照组(其中9人也超过了对照平均数的1.96 SDS),而3人没有(得分明显在典型范围内:73.53%、80.39%和80.39%)。超过自由CFMT标准的12名官员(8名超过1.96 SDS)在MMT上没有这样做,得分从64.44%到80.00%不等(见下图)。

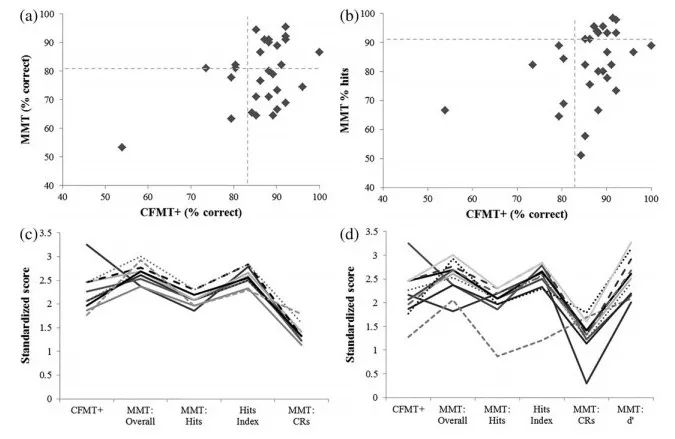
The relationship between officers' performance on the CFMT+ and (a) overall accuracy score on the MMT and (b) percentage hits on the MMT. Control cut‐offs (1.5 SDs from the mean on the CFMT+ and 1.96 SDs on the MMT) are indicated by grey dashed lines. Summary of performance for (c) the top 10 performers according to the Memory Hits Index and (d) the 12 officers that surpassed control performance by at least 1.96 SDs on the MMT d′ measure
人脸匹配性能一致性
我们的下一组分析检查了三个新的人脸匹配测试块(即姿态、眼镜和面部毛发)的性能一致性。每个块上所有参与者的命中、正确拒绝和总体准确性被总结,并使用控制数据计算每个度量的规范。
再次设定为1.96 SDS以上的控制均值(见下表)。我们最初检查了每个区块的总体准确率。首先,观察了那些在PMT筛选版中表现优于控制的官员。在这20名警官中,15名超过了三个区块中至少一个区的控制业绩:三个区块的控制成绩优于所有三个区块(见下图a),九个超过了任何两个区块的控制(见下图b),三个超过了任何一个区块的控制业绩(见下图c)。5在任何块上都没有超过控制(见下图d)。接下来,观察了未通过初步PMT筛选的10名军官的表现。值得注意的是,在任何一个板块,只有一名官员没有超过控制标准,只有两名官员超过了任何一个板块的控制标准(见下图e)。两名警官超过了所有三个板块的控制业绩,五个超过了任何两个板块(见下图f)。总体而言,30名警官中只有5人在所有三个板块都表现出一贯的高绩效,而24人在任何一次尝试中都超过了标准。

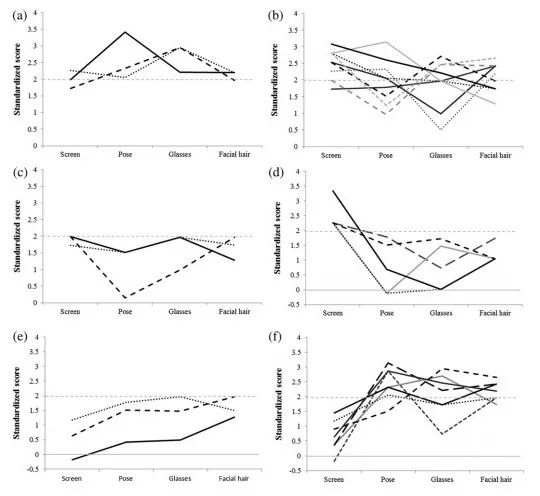
Consistency of officers' performance on the PMT at screening and in the three new blocks. Figures demonstrate those who outperformed controls at screening (according to the liberal 1.5 SD cut‐off); then by the more conservative 1.96 SD cut‐off on (a) all three blocks, (b) any two blocks, (c) any one block, and (d) no further block; and those who did not pass the initial screening criterion but outperformed controls on (e) only one or no block, or (f) on any two or three blocks
主要做这个的原因,就是想通过以上一系列实验,去挖掘经验丰富的警官对人脸识别的一个特性,从中发现平时我们科研没有发现的问题。比如,我一朋友做显著性检测,如果只在实验中通过搭建框架、训练测试,得出结果,那只是看到一个理论的表现,但是我朋友实验室有专门的显著性眼动仪,其可以通过现有模型的辅助,去人为进行实际实验,观察每一幅图像的显著性点及区域(说到这,我们平台准备下期为大家带来显著性检测),所以,本次分享的文献有些乏味,但希望做人脸领域的小伙伴,可以通过实际生活中的一些经验,通过数学的方式应用到模型当中,对实际场景的检测或识别有一定的提升。
如果想加入我们“计算机视觉战队”,请扫二维码加入学习群。计算机视觉战队主要涉及机器学习、深度学习等领域,由来自于各校的硕博研究生组成的团队,主要致力于人脸检测、人脸识别,多目标检测、目标跟踪、图像分割等研究方向。
我们开创一段时间的“计算机视觉协会”知识星球,也得到很多同学的认可,我们定时会推送实践型内容与大家分享,在星球里的同学可以随时提问,随时提需求,我们都会及时给予回复及给出对应的答复。

微信学习讨论群也可以加入,我们会第一时间在该些群里预告!


