论文浅尝 - WWW2020 | 生成多跳推理问题以改善机器阅读理解能力
论文笔记整理:谭亦鸣,东南大学博士生。

来源:WWW 2020
链接:
https://dl.acm.org/doi/pdf/10.1145/3366423.3380114
概述
这篇论文关注的任务是:基于给定文本的“多跳问题生成”(多关系问题)。
作者提出的方法大致可以描述为:
1.基于实体的上下文关系,将分布于文本中的实体融合为一个实体图;
2.通过证据关系及类型,从实体图中抽取子图,构成推理链(同时也获得对应的局部文本信息);
3.基于推理链,构建了一个整合的“生成-评价”网络模型,实现多跳问题的生成。
其中,作者将生成过程(生成器)设计为一个强化了问题句法和语义合理性的seq2seq模型;
在评价方面,作者通过建立一个混合监督学习与强化学习的评价机制,同时用于生成模型的优化。
本工作使用的数据集为:HotpotQA
问题生成方法的主要作用是构建伪训练标注集用于弥补数据集不足的问题。
背景与动机
本工作主要关联的一个NLP是:多跳机器阅读理解:即使机器完全理解文本语义,并回答一般的问题(尤其是需要学习推理)。因此这里的问题生成主要基于包含多实体/关系的文本数据。
从现有的问题生成方法上看:
1. 基于模板的方法受限于手写模板对于问题类型的覆盖能力;
2. 目前的 seq2seq 问题生成方法无法捕获和合成多个句子之间的证据(evidence,本质上,连续的relation)。
(个人认为真实情况下,这里应该隐含一个问题:“多个文本句子之间的指代消解问题”,但是从后文的方法和实验来看,数据样本中并没有遇到这样的挑战)
因此基于上述现有挑战,作者提出了本文问题生成方法。
方法
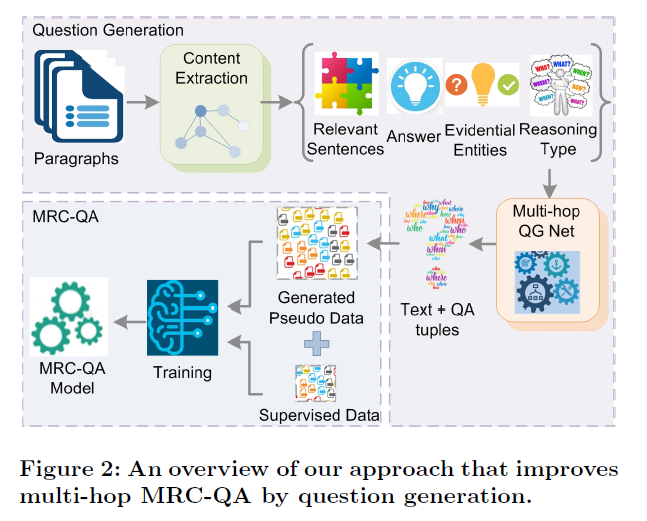
图2是本文问题生成方法的一个过程示意图,其中主要的部分是:
1.实体图:
用于捕获实体以及它们的上下文关系(从给定的文本中)。接着从实体图中找到一些证据性关系,构成推理链(这步着实关键),启发式的从文本中抽取与回答问题相关的部分(包括:1.答案,推理类型,证据实体和实体的句子)
2.整合的生成评价网络:
生成器:首先抓取推理链上的证据关系(使用GCN),使用一个seq2seq网络生成问题(基于抽取的上下文)。同时伴随一些类后处理机制(重复词生成;错误的答案相关词;无关词的复制;与答案类型无关的疑问词)
评价器:首先基于监督损失进行预训练,而后通过混合的监督与强化学习损失做fine-tune
问题生成的过程可以看作:
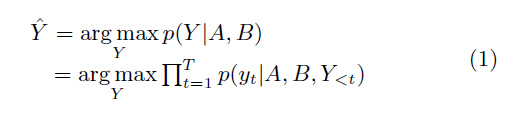
其中,Y是生成的问题,A是答案,B是给定文本。Y={y1,y2,…,yt} 生成的问题长度为t,因此也可以表示为对每个生成词的条件概率最大化。
实体图的具体构建过程是:
首先使用Stranford CoreNLP toolkit 确定句子中的实体(及类型:人,地点,代词),以及它们的上下文;(句子中的相同实体:包括指代,重复出现,部分出现(复述,使用序列相似度确定))
得到实体图之后,作者设计了三种类型的子图(抽取规则)
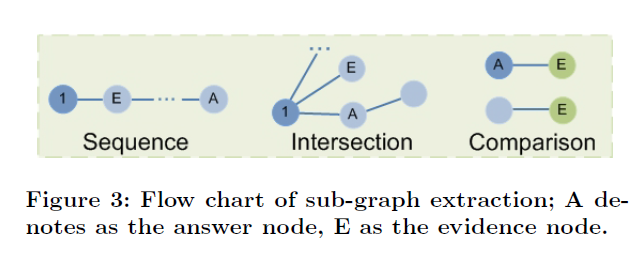
Sequence:需要使用证据实体充当序列链(从问题到答案)的桥梁
Intersection:交集(从sequence的中间截取answer)
Comparison:比较型问题
图4是整个模型的框架图,可以看到各个步骤中具体使用到的编码和解码网络类型以及评价使用的混合损失函数与reward(作者在原文中详细的描述了各个部分运算的过程,这里就不赘述了):
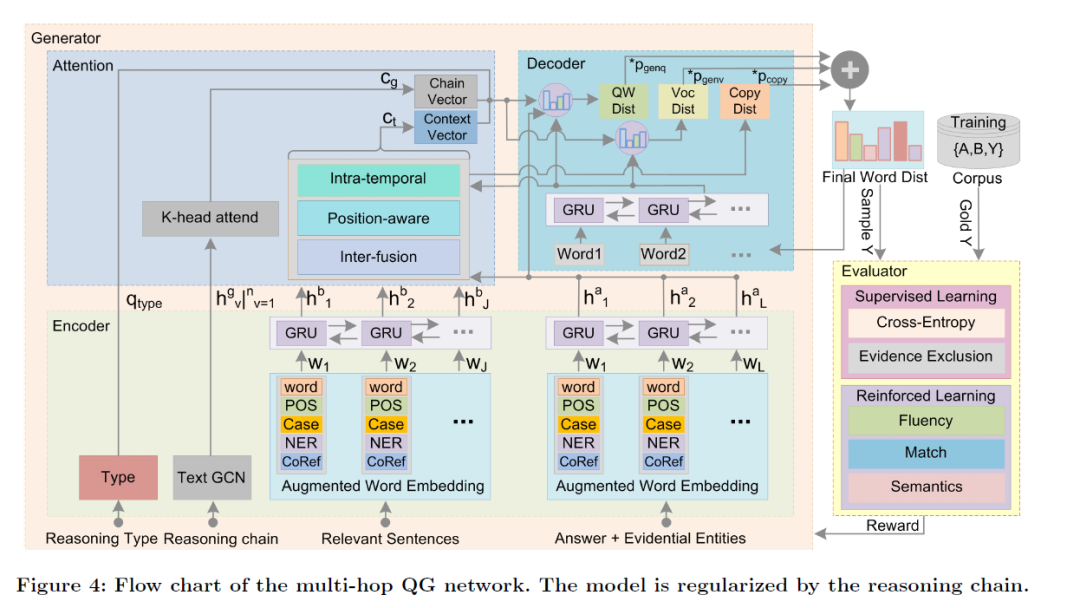
模型的主要输入是::1. 推理链;2.相关实体,上下文句子,答案
实验及结果
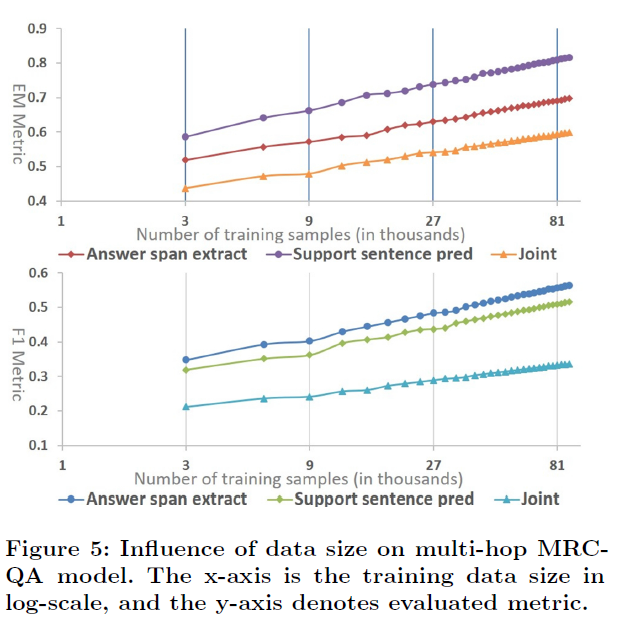
实验部分作者首先分析了数据集规模对MRC-QA(机器阅读理解问答)模型的影响,如图5所示,显然更大规模的(达到一定质量的)训练集往往带来更好的性能。
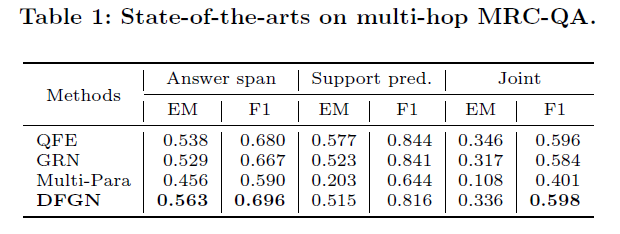
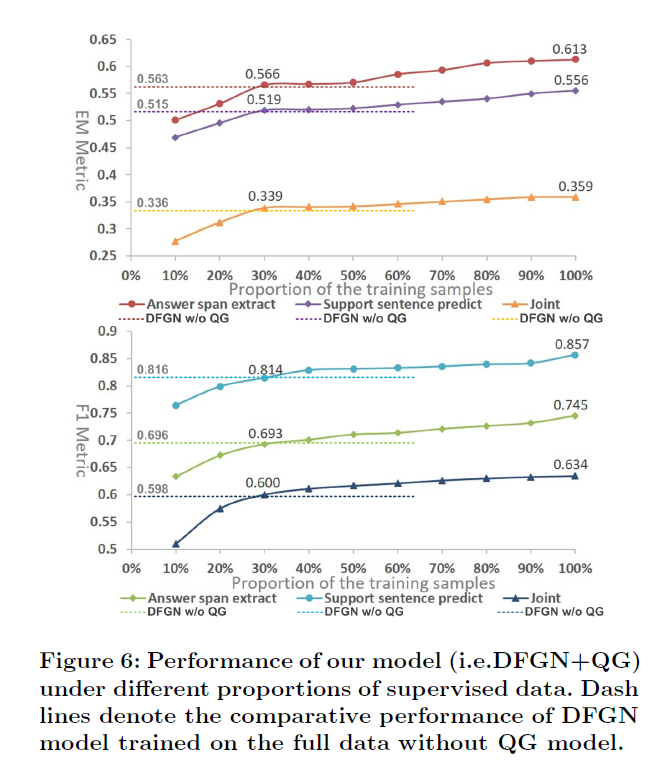
作者收集了现有的MRC-QA方法,并给出了它们的性能对比(表1),接着在DFGN(SOAT模型)上使用QG方法进行了改进(图6)。
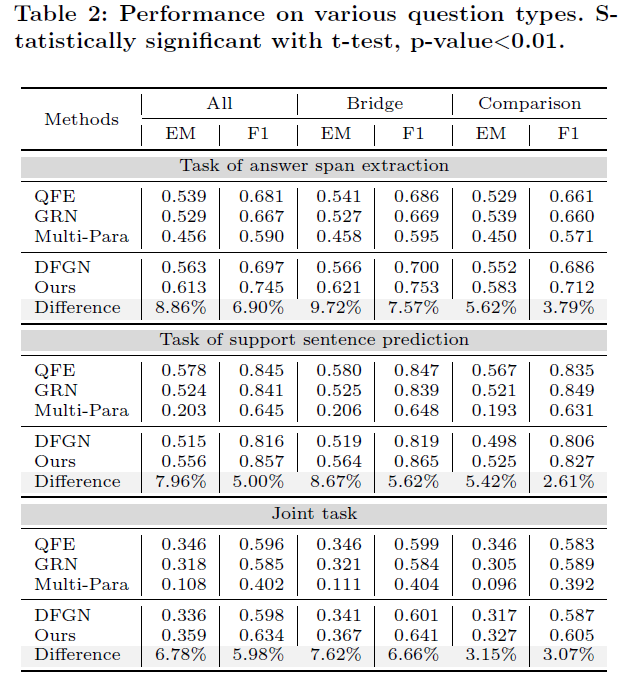
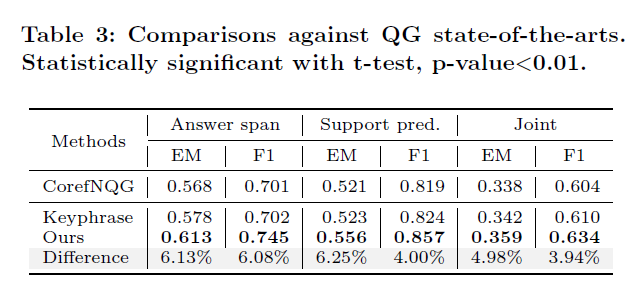
接着作者对比了不同问题类型上方法的效果(表2),以及本文QG方法与其他(SOAT)QG方法的统计对比(表3):
OpenKG
开放知识图谱(简称 OpenKG)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenKG 网站。



