CVPR 高引论文往往无缘 Best paper,「最佳」一定「高引」吗?
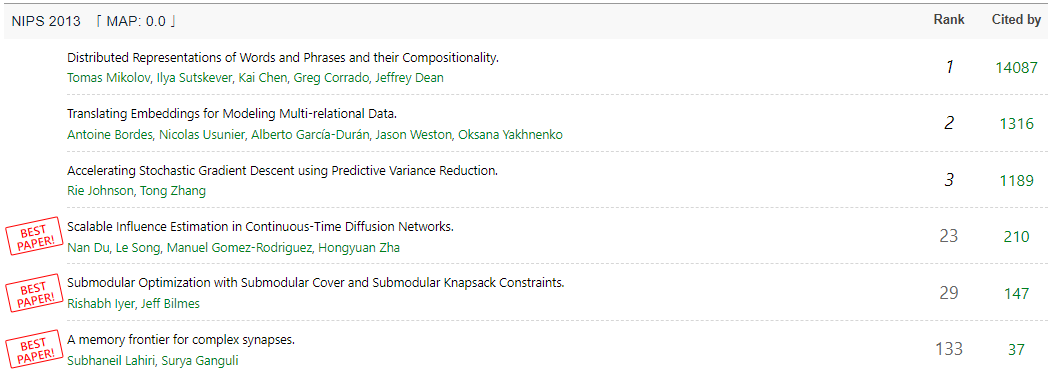
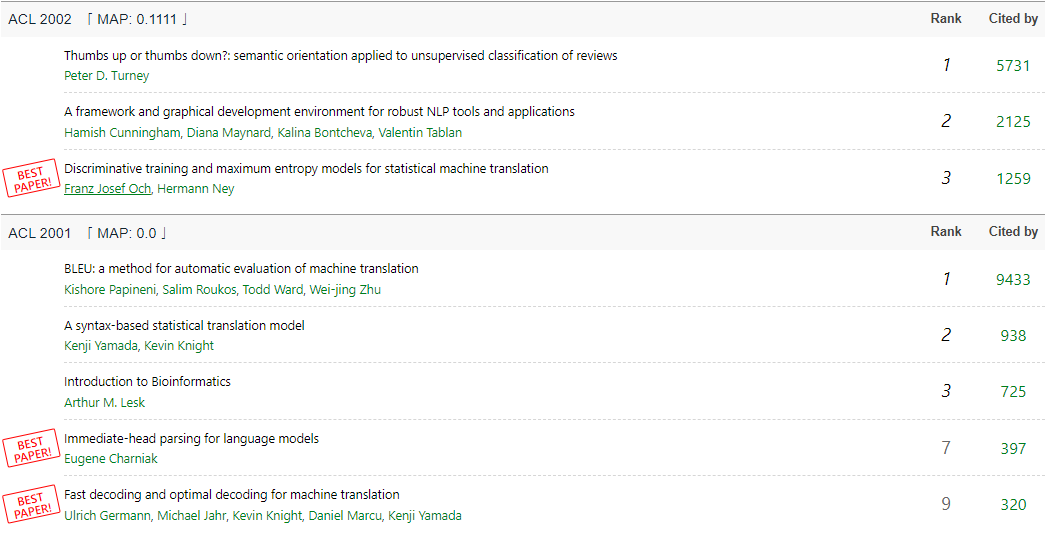
我们对60多个顶级国际会议的最佳论文和高引论文进行了分析,惊讶的发现只有10%的最佳论文最后成了真正的高引论文。是评奖委员会选错了吗?不同研究领域的最佳论文和高引论文又有什么特点呢?数据表明SIGGRAPH、SIGSPATIAL以及硬件等会议更“靠谱”(MAP值普遍大于0.5);也有很多会,比如人工智能会议NIPS、CHI、CVPR、KDD、AAAI、ACL、IJCAI等会议的高引论文往往无缘最佳论文。来查查你的会议表现吧:https://aminer.cn/bestpaper
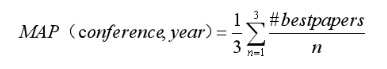



1. Facebook 自然语言处理新突破:新模型能力赶超人类 & 超难 NLP 新基准
2. 巴赫涂鸦创作者 Anna Huang 现身上海,倾情讲解「音乐生成」两大算法
3. 一份完全解读:是什么使神经网络变成图神经网络?

登录查看更多
相关内容

Arxiv
5+阅读 · 2019年2月25日
Arxiv
6+阅读 · 2018年4月13日
Arxiv
8+阅读 · 2018年2月7日




相关VIP内容
相关资讯
相关论文
Arxiv
5+阅读 · 2019年2月25日
Arxiv
6+阅读 · 2018年4月13日
Arxiv
8+阅读 · 2018年2月7日