【泡泡一分钟】基于密集RGB-D场景流的运动物体分割
每天一分钟,带你读遍机器人顶级会议文章
标题:Motion-based Object Segmentation based on Dense RGB-D Scene Flow
作者:Lin Shao , Parth Shah , Vikranth Dwaracherla , Jeannette Bohg
来源:IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS),2018
编译:王嫣然
审核:陈世浪,颜青松
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

对于两幅连续的RGB-D图像,我们提出了一种估计密集三维运动场的模型。利用在机器人操作场景中,场景通常由一组刚性移动的物体组成这一事实。我们的模型对(i)将场景分割成未知但有限数量的对象,(ii)这些对象的运动轨迹和(iii)对象场景流进行联合估计。我们采用沙漏式深层神经网络结构。编码阶段,RGB和深度图像进行空间压缩并关联。解码阶段,模型输出三幅图像,包含相应对象中心的每个像素估计以及对象的平移和旋转。这是推断目标分割和最终目标场景流的基础。
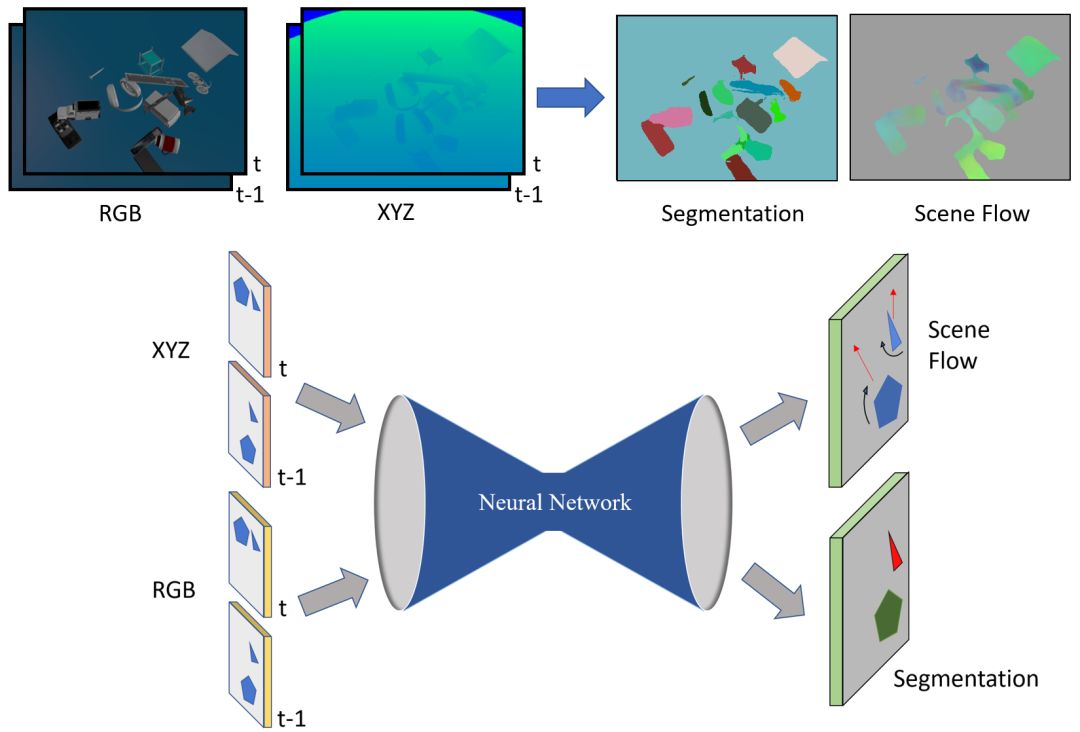
图1 文章采用的网络结构,该网络可对目标分割和场景流进行估计。
为对该模型进行评估,我们生成了一个新的,具有挑战性的大规模合成数据集。该数据集专门针对机器人操作,包含大量同时移动的3D对象场景,是用一个模拟的静态RGB-D相机记录得到。定量实验证明,我们的模型在该数据集上优于最先进的场景流和运动分割方法。定性实验也展示了现实场景中,我们的方法会产生比现有方法更好的在视觉效果。
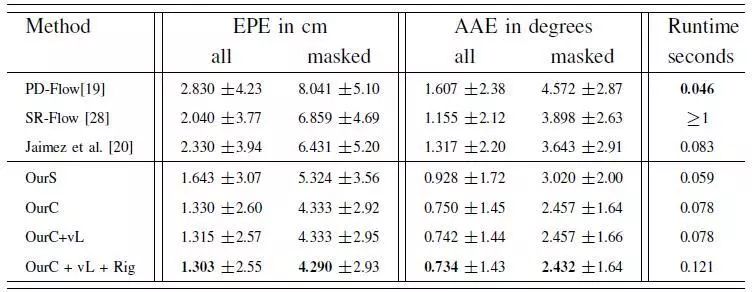
图2 场景流预测的性能由端点误差(EPE)和带有标准差的平均角度误差(AAE)测量,Masked仅包含两帧中均出现的对象数据

图3 综合数据集上算法性能对比

Abstract
Given two consecutive RGB-D images, we propose a model that estimates a dense 3D motion field, also known as scene flow. We take advantage of the fact that in robot manipulation scenarios, scenes often consist of a set of rigidly moving objects. Our model jointly estimates (i) the segmentation of the scene into an unknown but finite number of objects, (ii) the motion trajectories of these objects and (iii) the object scene flow. We employ an hourglass, deep neural network architecture. In the encoding stage, the RGB and depth images undergo spatial compression and correlation. In the decoding stage, the model outputs three images containing a per-pixel estimate of the corresponding object center as well as object translation and rotation. This forms the basis for inferring the object segmentation and final object scene flow. To evaluate our model, we generated a new and challenging, large-scale, synthetic dataset that is specifically targeted at robotic manipulation: It contains a large number of scenes with a very diverse set of simultaneously moving 3D objects and is recorded with a simulated, static RGB-D camera. In quantitative experiments, we show that we outperform state-of-the-art scene flow and motion-segmentation methods on this data set. In qualitative experiments, we show how our learned model transfers to challenging real-world scenes, visually generating better results than existing methods.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号(paopaorobot_slam)。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/bbs/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com


