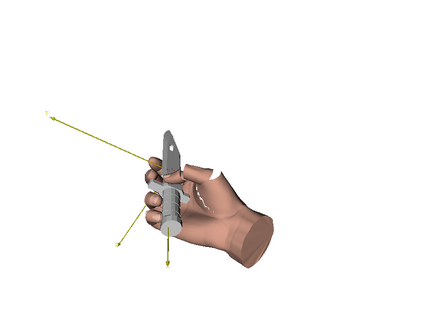
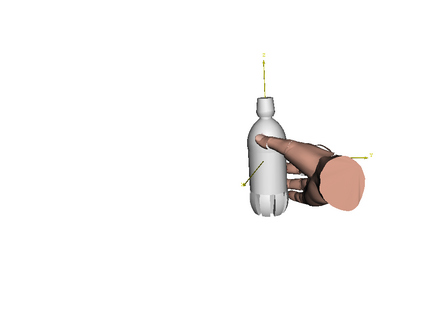
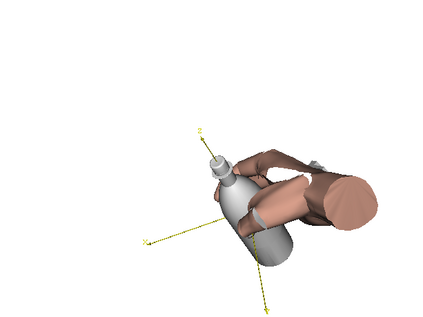
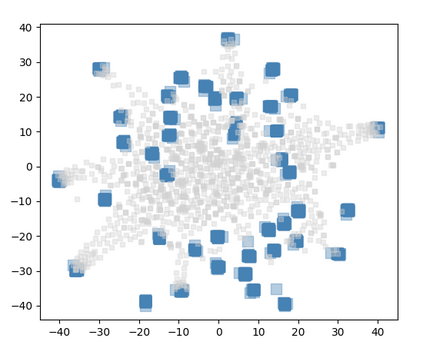
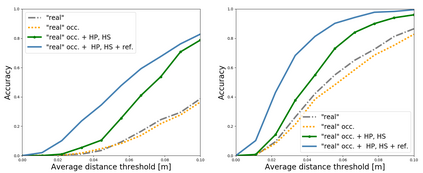
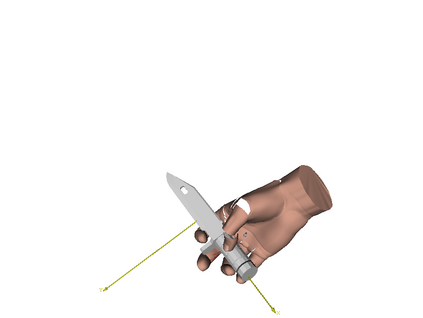
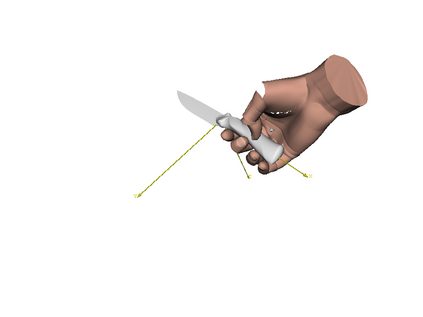
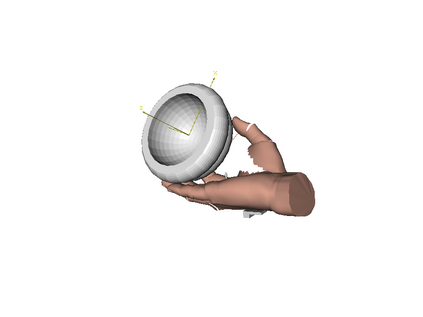
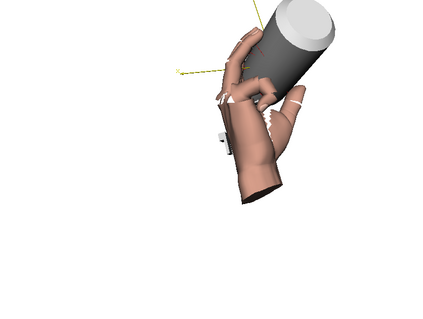
We develop a system for modeling hand-object interactions in 3D from RGB images that show a hand which is holding a novel object from a known category. We design a Convolutional Neural Network (CNN) for Hand-held Object Pose and Shape estimation called HOPS-Net and utilize prior work to estimate the hand pose and configuration. We leverage the insight that information about the hand facilitates object pose and shape estimation by incorporating the hand into both training and inference of the object pose and shape as well as the refinement of the estimated pose. The network is trained on a large synthetic dataset of objects in interaction with a human hand. To bridge the gap between real and synthetic images, we employ an image-to-image translation model (Augmented CycleGAN) that generates realistically textured objects given a synthetic rendering. This provides a scalable way of generating annotated data for training HOPS-Net. Our quantitative experiments show that even noisy hand parameters significantly help object pose and shape estimation. The qualitative experiments show results of pose and shape estimation of objects held by a hand "in the wild".
翻译:我们开发了一个从 RGB 图像中模拟3D 3D 手上物体相互作用的模型系统, 显示手持有一个已知类别的新物体。 我们设计了一个手持对象Pose 和 形状估计的进化神经网络(CNN), 名为 HOPS-Net, 并使用先前的工作来估计手部的外形和配置。 我们利用关于手部的信息促进物体的外形和形状估计的洞察力, 将手部的外形和形状纳入对物体的训练和推断, 并改进估计的外形。 网络在与人手相互作用的物体的大型合成数据集方面接受了培训。 为了缩小真实和合成图像之间的差距, 我们使用一个图像到图像转换模型( Augmented CycourGAN ), 产生真实的手部图像和图像转换模型( Augminucable GAN ), 提供一种可缩放的方法为HOPS- Net 培训生成附加数据的方法。 我们的定量实验显示, 即使手势参数也极大地帮助对象的外形和形状估计。 定性实验显示, 显示手部的物体的外形和形状估计的结果。