WebAssembly在QQ邮箱中的一次实践
本文由 IMWeb 社区 imweb.io 授权转载自腾讯内部 KM 论坛,原作者:pepegao。点击阅读原文查看 IMWeb 社区更多精彩文章。
浏览器端执行的二进制
WebAssembly是一种预期可以与Javascript协同工作的二进制文件格式(.wasm),通过C/C++(或其他语言)的源代码可以编译出这种格式,在现代浏览器端直接运行。
在web端提起二进制,相信第一反应就是:执行速度快了。Javascript经过现代浏览器复杂的JIT优化,执行速度有了很大改善,但是还是无法与native的速度相比较。而且很多时候JIT能否生效取决于开发者的代码是如何写的,这里就有一些V8拒绝执行JIT的例子(https://github.com/petkaantonov/bluebird/wiki/Optimization-killers)。
实践场景
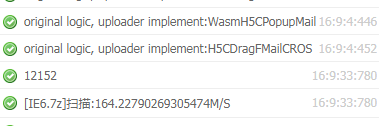
在QQ企业邮箱中,有这样一个功能:上传附件。为了判断附件是不是已经上传过,上传前要对文件执行一次扫描。企业邮箱中扫描和上传附件,使用的是H5 FTN上传组件。后者由纯JS实现,扫描文件的速度可以达到40+M/s,相比上一个版本的Flash+H5的组件,速度已经提高了一倍以上。以下图为例,生产中测试,一个1.9G的附件,大约需要20-40秒(视机器情况)。对于一个命中秒传逻辑的附件(只需要一次轻量ajax请求就可以完成上传),扫描的时间就有些长了。所以想在这里看看WebAssembly有没有更好的表现。
Emscripten下的工作机制
查阅了相关的资料,决定按照官方推荐用emscripten来编译wasm。在这以前,对llvm-emscripten的机制也做了一些了解和尝试,整理了从源码到wasm应用在浏览器端的流程,如下图。
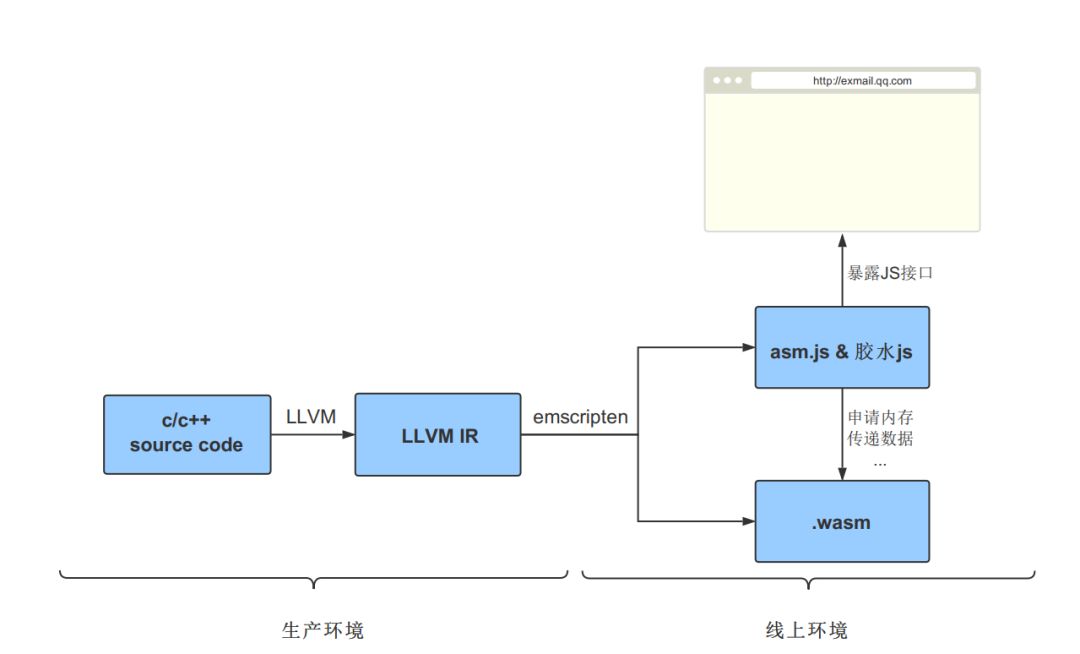
核心内容有三部分:LLVM,emscripten,js/wasm/浏览器通信。
LLVM
LLVM本质上是一系列帮助开发编译器、解释器的SDK集合,按照传统编译器三段式的结构来说,更接近于优化层(Optimizer)和编译后端(Backend),而不是一个完整的编译器。

LLVM在优化层,对中间代码IR来执行代码的优化,它独特的地方在于IR的可读性很高。体验了一下,比如这样一个C文件test.c:
int main()
{
int first = 3;
int sum = first + 4;
return 0;
}
用Clang生成IR 文件test.ll
clang -S -emit-llvm test.c
然后打开生成的test.ll,找到了main函数倒数第三行,看起来有点像机器码。这里已经比较易懂了:将%4寄存器的值和立即数4相加,写入%5寄存器。
define i32 @main() #0 {
%1 = alloca i32, align 4
%2 = alloca i32, align 4
%3 = alloca i32, align 4
store i32 0, i32* %1, align 4
store i32 3, i32* %2, align 4
%4 = load i32, i32* %2, align 4
%5 = add nsw i32 %4, 4
store i32 %5, i32* %3, align 4
ret i32 0
}
除了代码性能优化,作为SDK集合的LLVM还提供了一些工具,用来支持代码复用、多语言、JIT,文档也比较友善,相比GCC感觉这里是加分项。
然后是编译前端,在现在版本的LLVM中,使用Clang(LLVM Native)来完成编译工作。如果想要用Clang不支持的语言来作为源码,比如Java,猜测也是可以的,因为我在LLVM的下载页看到3.0之前的版本可以用GCC编译,不过这一点这次还没有去验证。
emscripten
生成LLVM IR后,LLVM的任务就完成了。emscripten的编译平台fastcomp负责将LLVM IR转化为特定的机器码或者其他目标语言(包括wasm)。在这里,emscripten其实扮演了编译器后端的角色(LLVM Backend)。
在安装emscripten的时候,有一步是安装它的编译工具链binaryen,有趣的是,它也是基于LLVM的,比如它的一种编译wasm的方式:
C/C++ Source -> WebAssembly LLVM backend -> s2wasm -> WebAssembly
刚刚说到,LLVM IR本身可读性较高,文档支持友善,代码复用容易,这都有助于开发者将LLVM IR中间代码封装为自己平台的中间代码,继而解释为汇编或者其他语言。其他编译工具(比如fastcomp,binaryen)广泛适用。(感觉又要加分了)
js/wasm/浏览器的通信
emscripten可以用emcc编出wasm文件、和wasm通信用的胶水js以及asm.js
(asm.js是js的子集,可以理解为wasm的前身也可以当作wasm的退化方案,数据都是强类型,用于优化js速度的,这次用不到,编译时可以用--separate-asm剥离开)。
js/wasm/浏览器的调用关系,可以用这张图来表示:
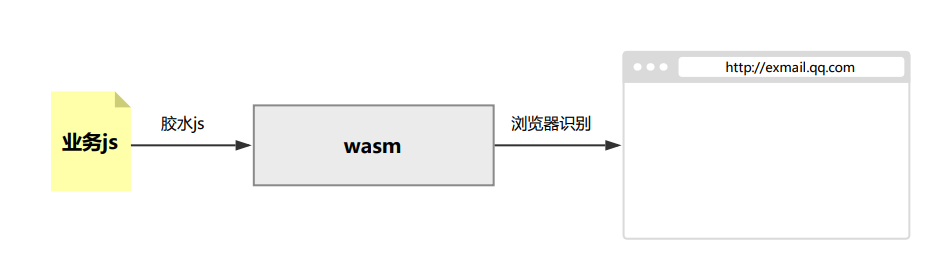
浏览器要能支持wasm格式。浏览器能识别wasm时,wasm会比js以更高效的速度执行,因为它比js更直接的映射为机器码,这是由它所处在IR和机器码之间决定的。关于wasm格式的支持,已经形成了标准 ,并且Chrome,Safari,Firefox,Edge四家的新版本都积极跟进,是个好消息。

2. 胶水js一方面向业务暴露接口,另一方面要向wasm(二进制)传递数据;
首先它需要发起一个请求,向服务器下载wasm文件,由文件内容生成一个wasm实例(wasm-instantiate),因为这个实例是连接js和wasm的一个基本要求(即依赖,当然我们也可以额外添加其他依赖)。当所有的依赖都准备完毕时,emscripten会执行run函数,寻找并执行我们在源代码中的main函数。
//简化了部分内容
function run(args) {
if (runDependencies > 0) return;
function doRun() {
if (Module['_main'] && shouldRunNow) Module['callMain'](args);
}
doRun();
}
main函数执行后,源码中声明的函数就进入了Runtime(浏览器端可调用的native code),并在浏览器端声明一个叫做Module的对象,通过它完成通信:
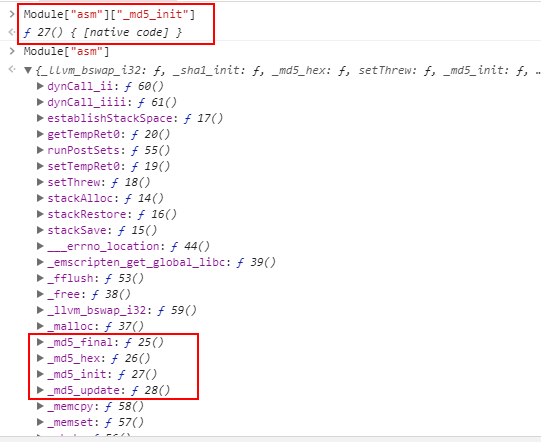
胶水js已经暴露出了wasm的接口,然后来看下调用方如何将数据传输给wasm
emscripten在胶水函数内部模拟了内存结构,最大16MB,单次操作的内存修改默认不能超过5MB,类型是js中的typedarray。typedarray对同一个arraybuffer的不同表现实现了不同结构,这里也一样。具体使用哪种要看实际需要,如果源码内的变量都是定长,比如4字节,那可以用HEAP32,会更接近native的表现。因为这里我们要操作文件内容,不定长,就选HEAP8了(8bit)。
function updateGlobalBufferViews() {
Module['HEAP8'] = HEAP8 = new Int8Array(buffer);
Module['HEAP16'] = HEAP16 = new Int16Array(buffer);
Module['HEAP32'] = HEAP32 = new Int32Array(buffer);
Module['HEAPU8'] = HEAPU8 = new Uint8Array(buffer);
Module['HEAPU16'] = HEAPU16 = new Uint16Array(buffer);
Module['HEAPU32'] = HEAPU32 = new Uint32Array(buffer);
Module['HEAPF32'] = HEAPF32 = new Float32Array(buffer);
Module['HEAPF64'] = HEAPF64 = new Float64Array(buffer);
}
业务js可以调用cwrap(ccall等等)将数据以typedarray传递给emscripten,收到数据后,后者向Runtime申请指定大小的内存,返回内存的起始地址(ret),从这个地址开始,向Runtime写入数据。这个地址最终会作为参数传递给源码中的函数。
'arrayToC' : function(arr) {
var ret = Runtime.stackAlloc(arr.length);
writeArrayToMemory(arr, ret);
return ret;
}
WebAssembly性能验证
wasm编译出来速度如何?准备了个demo做下简单验证。
准备好要编译的C代码,提供几个我们需要的基本函数,声明如下(具体实现是计算buffer的哈希,这里就未列出了):
void sha1_init();
void sha1_update(const char *data, int len);
char* sha1_final();
void md5_init();
void md5_update(const char *data, int len);
char* md5_final();
在两个update函数中,参数data的指针就是上面说到的,指向了Runtime.stackAlloc分配的内存起始地址,len是该段内存的长度,该段内存的内容就是我们输入的文件/文件分片的buffer。
用emcc编出需要的wasm,从胶水js暴露的接口拿到wasm版本的哈希函数,同业内速度最快的JS哈希库Rusha.js和Yamd5.js比较下速度,比较方式大致如下,读取一个530k的文件:
const md5_init = Module.cwrap('md5_init');
const md5_update = Module.cwrap('md5_update', null, ['array', 'number']);
const md5_final = Module.cwrap('md5_final','string');
const sha1_init = Module.cwrap('sha1_init');
const sha1_update = Module.cwrap('sha1_update', null, ['array', 'number']);
const sha1_final = Module.cwrap('sha1_final','string');
const yamd5 = new YaMD5;
const rusha = new Rusha;
md5_init();
sha1_init();
yamd5.start();
rusha.reset();
$("#filetest").on('change', e => {
let fr = new FileReader();
fr.readAsArrayBuffer(e.target.files[0]);
fr.onload = (event) => {
let ia8 = new Int8Array(event.target.result);
let uia8 = new Uint8Array(event.target.result)
md5_update(ia8);
md5_final();
sha1_update(ia8);
sha1_final();
yamd5.appendByteArray(uia8);
yamd5.end();
rusha.append(uia8);
rusha.end();
}
})
四个计算操作结束时分别计算打点,比较下耗时:

可以看到相比纯JS的方案,wasm二进制方案还是有5-8倍的提升空间,根据这个预期就开始着手修改线上代码了(这里并没有用worker,并且是在特定机器上测试的,耗时仅供做横向参考,具体表现要看代码结构、机器的性能等等)。
线上代码的改造
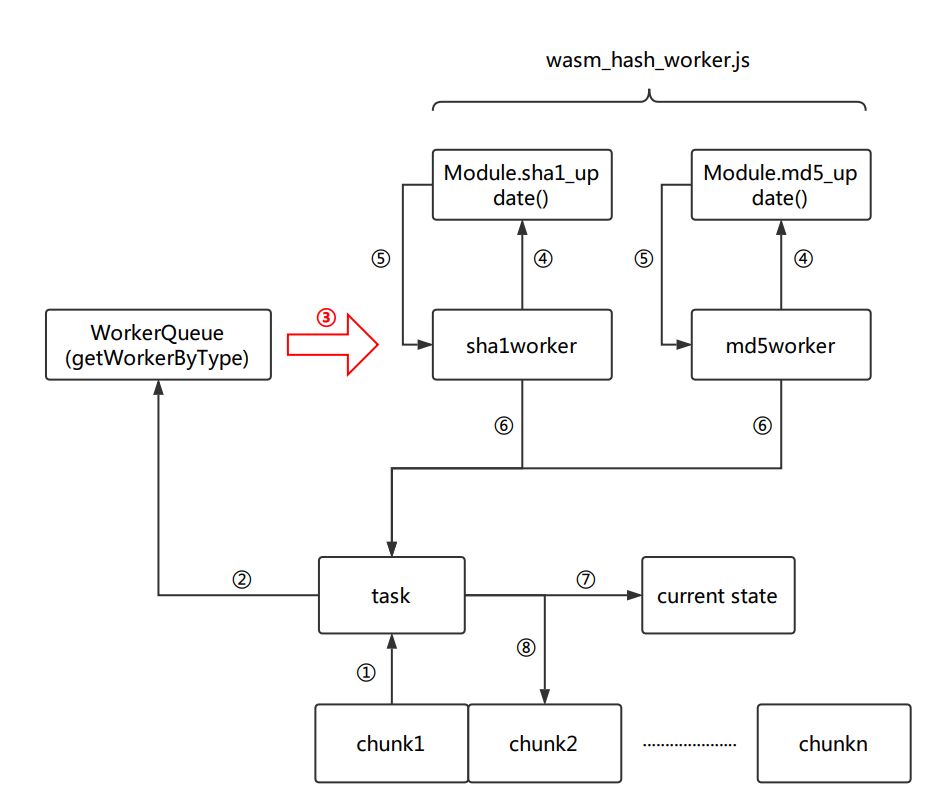
因为已经达到了毫秒级的计算,为了不卡死主线程的浏览器UI,H5 FTN上传组件 用worker新开了线程来执行计算操作。这里要开在计算前预先申请n个(这里以2个为例)worker,并放入一个WorkerQueue的队列。主线程和worker线程通过postMessage通信。
要上传的文件经过择优后按照每分片512KB的大小切片,对于每一个分片(chunk),并行发起sha1和md5的任务,生成task后,task会被推送到worker队列,后者每接到一个任务,就取出空闲的worker,将其标记未不可用,通过postMessage向worker传递该切片的文件内容。worker自身接收到切片后,调用哈希函数进行update,并将更新后的状态再通过postMessage发送回给主线程,这时该worker会在WorkerQueue中重新标记为可用状态。当sha1的worker和md5的worker均完成后,这个分片的周期结束。执行下一个分片的计算,重复这个过程,直到所有分片都经过计算后,再发起一次获取哈希的周期,拿到md5和sha1的最终值,扫描结束。
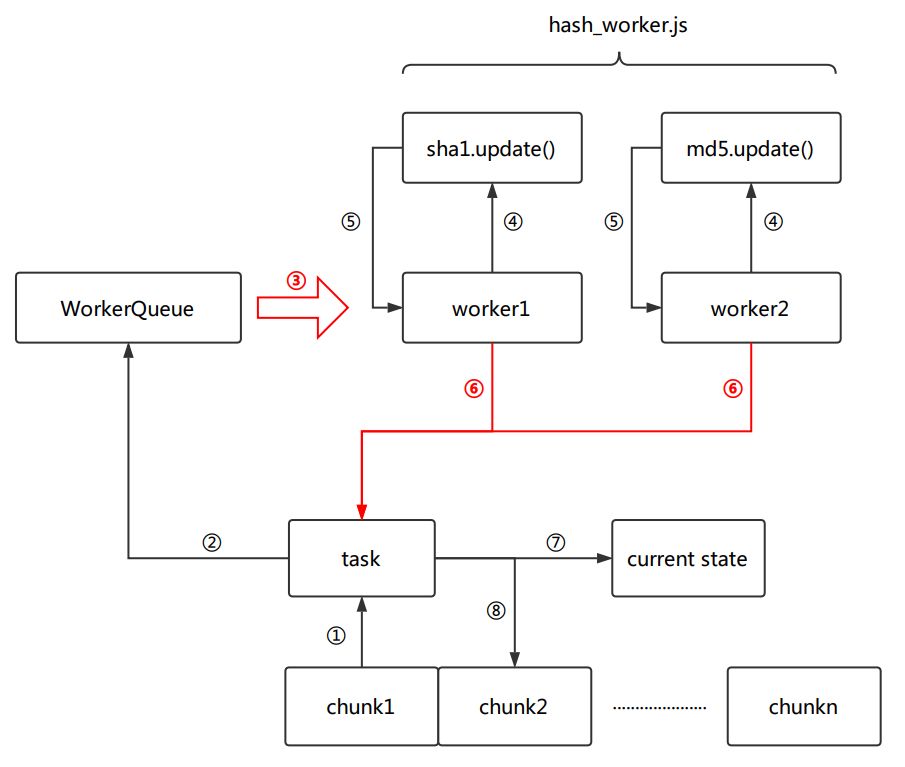
以上就是原有组件扫描附件时的逻辑。这次改动代码时,最初只是简单将worker中计算哈希的部分替换为wasm的实现,就迫不亟待的看结果了,看到结果后发现并没有达到demo中预期的效果,反而有时还会更慢些。在关键步骤打了下log看下耗时发现,时间主要消耗在主线程和worker线程通过postMessage传递文件内容的步骤(图中的红色的流程)。当这里的耗时高的话,会稀释掉扫描掉wasm本身的速度提升,特别是文件较小的时候。
比如这里打出了一次扫描耗时的时间点:
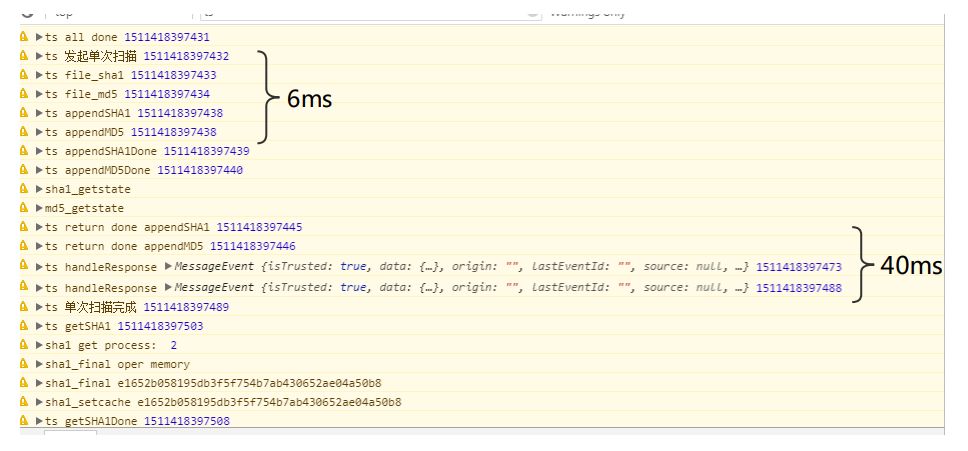
按上文说的,以40M/s的扫描速度、每分片512KB来计算,每个分片的扫描周期时间不能超过12ms,不然就无法达到优化的目的了。图里可以看到,6ms是buffer传递给worker的耗时,40ms是把代表系统update进度的buffer返回给主线程的耗时,虽然不每次都是这样的情况,但是已经超过了12ms的标准,当逻辑操作耗时像这样增大时,扫描操作本身的速度也就不那么重要了。
如果postMessage只是用来收发指令,不传递buffer,这个问题就不存在了。但是不传递buffer就有一个疑问,不同worker之前如何共享当前的扫描进度?因为WorkerQueue的worker是FIFO的,每次切片计算完,并不能保证回到栈顶的是执行md5的worker还是sha1的worker。如果上一次执行md5的worker这次分配到sha1任务,它自身的堆栈一定不持有当前系统的sha1的buffer(因为sha1刚刚被另一个worker操作过),让它来计算sha1,这个结果就不对了。
回过头来调研了下处理不同worker间或worker与主线程间通信可能的几种办法:
postMessage
sharedArrayBuffer (仍然要使用postMessage,并且大多数浏览器未实现)
IndexedDB (大数据下的一次读写数据库要几十毫秒,速度在这个场景不适合)
看起来还是要用postMessage,既然耗时不能避免,那尽量减少传递buffer的次数也是好的。最后决定改下WorkerQueue:队列中的worker不再等价。系统申请worker时,worker将会被打上md5或者sha1的标记,前者只执行md5任务,后者只执行sha1任务 。WokerQueue在收到系统的任务申请的时候,根据任务类型分配类型相同的worker。
这样,在一个扫描周期中,只有主线程将新文件切片的buffer传递给worker的时候才需要传递一次buffer,任务执行完毕时就不再需要返回了。因为从开始到现在,update了多少buffer,每个worker自己都很清楚(buffer维持在自己作用域下Module对象里),并且也不需要了解另一个buffer状况如何。当然这要求系统内处理哈希的worker有且只能有两个,worker多于两个,还是有需要共享的问题。
限制为两个worker,会比4个,n个慢吗?按照目前的代码结构来看,不会。因为每一次扫描的请求中,执行任务快的worker一定要等待慢的worker执行完,系统才会去WorkerQueue申请新的worker,就是说同一时刻只能有两个worker在工作。
Promise.all([
_aoBlock._hashHandle("", "file_sha1", parseSha1Msg, "file_sha1", true),
_aoBlock._hashHandle("", "file_md5", parseHashMsg, "file_md5", true)
]).then(function(){
//do next iteration
});
更改后只有在发起任务的时候会传递一次文件内容,结构如下:
再跑一次看看效果:
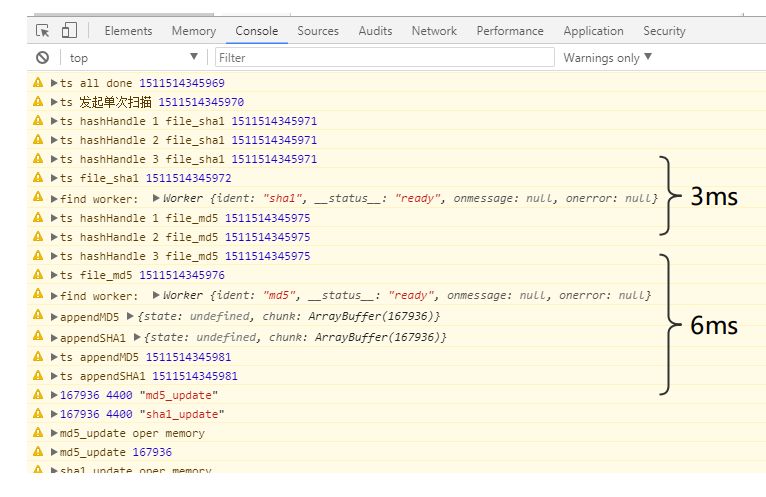
单次扫描中,两处消耗较大:
第一次传递buffer耗时6ms,预期之内。
promise.all发起并行任务时还有一次3ms偶然的耗时。不开worker的情况下代码都跑在主线程,所以web上的promise.all其实不是真正并行,只能算是异步,它的表现我们也比较难控制。
除此之外,基本主要流程的都可以在1ms以内完成了。
线上用户的表现
文件较大的时候,整个扫描过程耗时更贴近计算哈希的耗时,所以上线后统计用户的表现时,按照500MB区分了文件大小。500MB以上的附件扫描速度,如图:
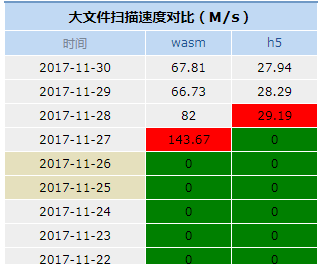
28号以后的为线上用户环境的数据,横向看wasm速度约是h5版本的2.3倍以上
这里恰好统计到了27号测试环境的速度,纵向对比可以看到,用户设备的性能也决定了最终的速度
1.9G文件的表现
最后还是用本文开始时的那个1.9G的附件看下现在的表现吧,上图:
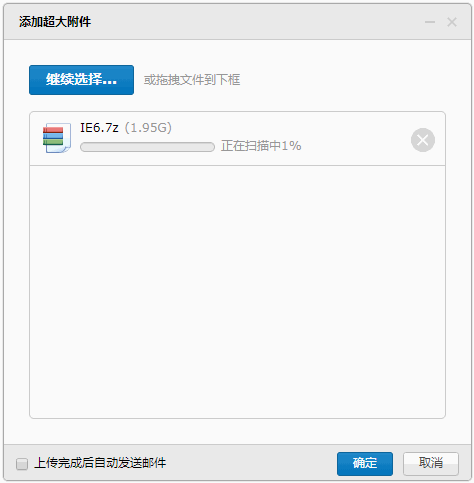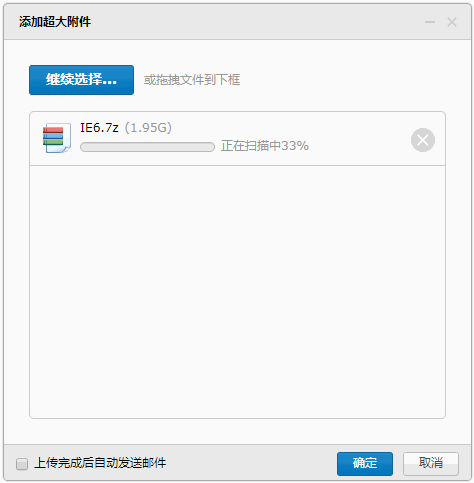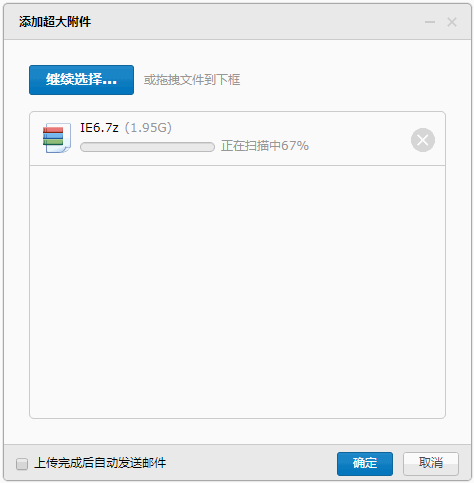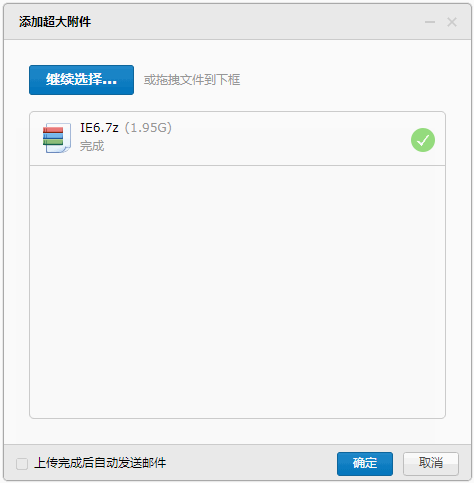
扫描1.9G文件耗时约12.1秒,扫描速度可以到160M/s。速度达到了原有速度(75M/s)的2.1倍左右,与现网用户的表现基本一致。
一些体会
一个放心敢用的Javascript API,一般要经过ECMA-262发布标准,浏览器厂商跟进。这个流程不能算快(1997年到现在ECMA-262一共也只发布了7个版本)。但是WebAssembly不一样,它已经是一个标准并被浏览器支持了,想新增特性,只要源码编的出来,js和wasm能在可忍受的耗时内完成通信,那就立刻可以得到。这点还是挺方便的。
WebAssembly更适合完成CPU密集的操作,不适合重逻辑的情况,因为这会增加额外的调用消耗。
在计算速度上,WebAssembly相比Javascript是有优势的。文中提到512KB大小的分片在H5方案下有最优表现,对于wasm来说其实计算512KB和计算4MB的文件速度是接近的,整个系统可以通过提高分片大小来压榨wasm的速度。然而在加载速度上,WebAssembly的额外一次请求其实相比现在Javascript成熟的加载方案并没有什么优势。所以是否用WebAssembly还是要看具体情况。
期待WebAssembly有更多的应用场景。
关注我们
IMWeb 团队隶属腾讯公司,是国内最专业的前端团队之一。
我们专注前端领域多年,负责过 QQ 资料、QQ 注册、QQ 群等亿级业务。目前聚焦于在线教育领域,精心打磨 腾讯课堂 及 企鹅辅导 两大产品。
社区官网:
http://imweb.io/
加入我们:
https://hr.tencent.com/position_detail.php?id=45616

扫码关注 IMWeb前端社区 公众号,获取最新前端好文
微博、掘金、Github、知乎可搜索 IMWeb 或 IMWeb团队 关注我们。
👇点击阅读原文获取更多参考资料




