草图秒变风景照,英伟达神笔马良GaoGAN终于开源了

新智元报道
新智元报道
来源:nvlabs.github.io
编辑:肖琴
【新智元导读】英伟达最近发布的图像合成 “黑魔法”GauGAN 效果令人惊叹,现在,相关代码和预训练模型终于公开了。
还记得英伟达在 GTC 2019 披露的令人惊叹的图像生成器 GauGAN 吗?仅凭几根线条,草图秒变风景照,自动生成照片级逼真图像的技术堪比神笔马良。


图中,左边是人类操作员画的,右边是 AI 直接 “简单加上几笔细节” 后生成的。在普通人看来,右边的图像几乎毫无破绽,看不出这并非一张风光照片,而是 AI 生成的虚拟海滩。
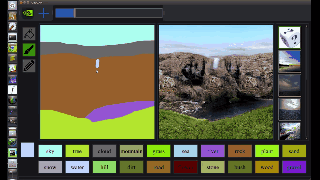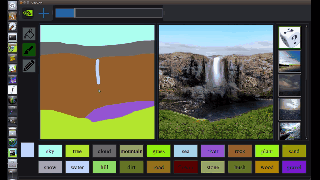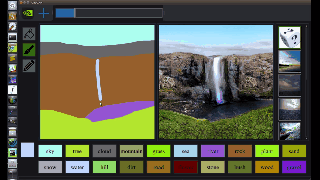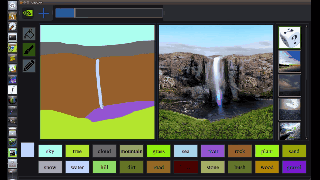
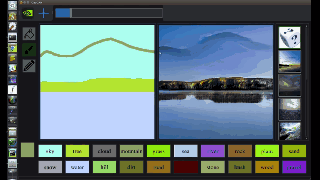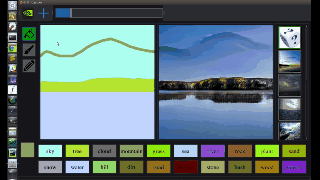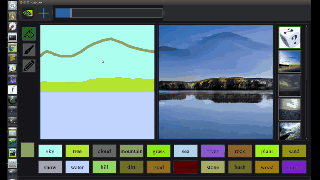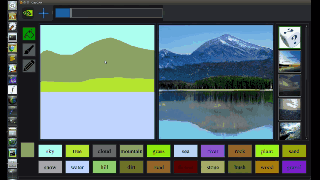
从图中我们可以看出,GauGAN 并不是像 Photoshop 里贴一个图层那样,简单的把图形贴上去,而是根据相邻两个图层之间的对应关系对边缘进行调整。比如石头在水里的倒影应该是什么样的、被瀑布冲刷的山石应该是怎样的状态、近处的山和远处的山之间的层次应该如何表现…
请看下面的demo:
相关阅读:英伟达再出黑魔法GauGAN:凭借几根线条,草图秒变风景照
GauGAN 背后的技术来自来自英伟达和 MIT 的研究团队。这个团队,包括来自英伟达的 Ting-Chun Wang、刘明宇(Ming-Yu Liu),Taesung Park (当时在英伟达实习),以及来自 MIT 的朱俊彦(Jun-Yan Zhu)。

论文地址:https://arxiv.org/pdf/1903.07291.pdf
他们提出一种名为 “空间自适应归一化”(SPADE) 的语义图像合成技术,论文已经被 CVPR 2019 接收,并入选 oral paper。
近日,SPADE 的代码终于发布,包括预训练模型等,有兴趣的同学赶紧来试试复现吧。
GauGAN 是基于名为 “空间自适应归一化”(spatially-adaptive normalization, SPADE) 技术实现的。该方法通过一个简单但有效的层,在给定输入语义布局的情况下合成照片级真实的图像。
以前的方法直接将语义布局作为输入提供给网络,然后通过卷积、归一化和非线性层进行处理。我们证明了以前的方法不是最优的,因为归一化层往往会消除语义信息。
为了解决这个问题,我们建议使用输入布局,通过空间自适应的、学习的变换来调整归一化层中的激活。
在几个具有挑战性的数据集上的实验表明,与现有方法相比,SPADE 在视觉保真度和与输入布局的对齐方面具有优势。最后,我们的模型允许用户轻松地控制合成结果的样式和内容,以及创建多模态的结果。
方法简述
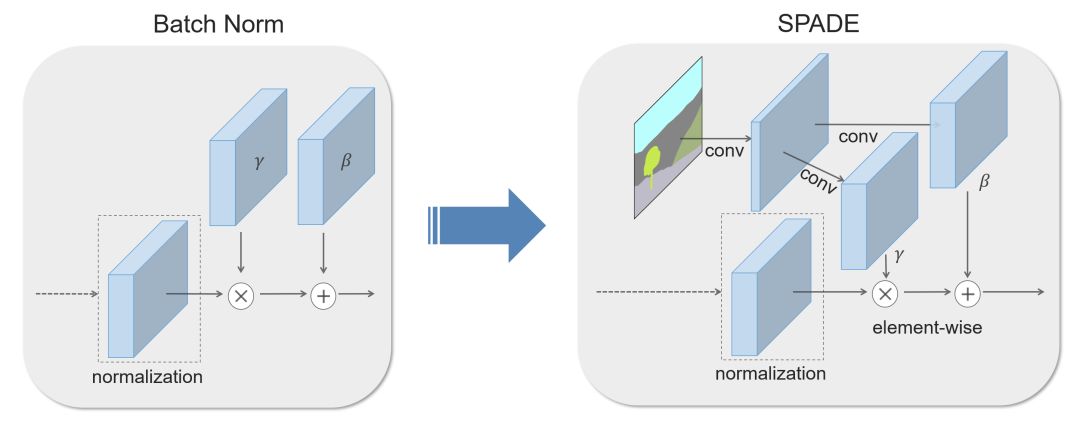
在许多常见的归一化技术中,如 Batch Normalization (Ioffe et al., 2015),在实际归一化步骤之后会应用到学习的 affine layers (如在 PyTorch 和 TensorFlow) 中。
在 SPADE 中,affine layers 是从语义分割映射中学习的。这类似于条件归一化 (De Vries et al., 2017 和 Dumoulin et al., 2016),除了学习的 affine parameters,还需要空间自适应,这意味着我们将对每个语义标签使用不同的缩放和偏差。
使用这种简单的方法,语义信号可以作用于所有层的输出,而不受可能丢失这些信息的归一化过程的影响。此外,由于语义信息是通过 SPADE 层提供的,所以可以使用随机的潜在向量作为网络的输入,从而实现操纵所生成的图像的样式。
与现有方法的比较

SPADE 在 COCO-Stuff 数据集上的性能优于现有方法。因为具有更多的场景和标签,COCO-Stuff 数据集比 Cityscapes 数据集更具挑战性。上面的图片比较了 GRN、pix2pixhd 以及 SPADE 的效果。
应用到 Flickr 图片

由于 SPADE 适用于不同的标签,因此可以使用现有的语义分割网络对其进行训练,学习从语义映射到照片的反向映射。上面这些图片是由 SPADE 对从 Flickr 上抓取的 40k 张图片进行训练生成的。
安装
克隆这个 repo
git clone https://github.com/NVlabs/SPADE.gitcd SPADE/
这段代码需要 PyTorch 1.0 和 python 3+。请通过以下方式安装依赖项
pip install -r requirements.txt
代码还需要同步的 Synchronized-BatchNorm-PyTorch rep.
cd models/networks/git clone https://github.com/vacancy/Synchronized-BatchNorm-PyTorchcp Synchronized-BatchNorm-PyTorch/sync_batchnorm . -rfcd ../../
为了重现论文中报告的结果,你需要一台有8个 V100 GPU 的 NVIDIA DGX1 机器。
数据集准备
对于 COCO-Stuff、Cityscapes 或 ADE20K,必须预先下载数据集。请在相关网页下载。
准备 COCO-Stuff 数据集。图像、标签和实例映射应该与数据集 /coco_stuff/ 中的目录结构相同。特别地,我们使用了一个实例映射,它结合了 “things instance map” 和 “stuff label map” 的边界。我们使用了一个简单的脚本数据集 /coco_generate_instance_map.py。请使用 pip install pycocotools 安装 pycocotools,并参考脚本生成实例映射。
准备 ADE20K 数据集。解压数据集后,将 jpg 图像文件 ADEChallengeData2016/images/ 和 png 标签文件 ADEChallengeData2016/annotatoins/ 放在同一个目录中。
使用预训练模型生成图像
数据集准备好后,就可以使用预训练模型生成图像。
1、从 Google Drive Folder 下载预训练模型的 tar,保存在 'checkpoint /‘中,然后运行
cd checkpointstar xvf checkpoints.tar.gzcd ../
2、使用预训练模型生成图像
python test.py --name [type]_pretrained --dataset_mode [dataset] --dataroot [path_to_dataset]3、输出图像默认存储在./results/[type]_pretrained/。
训练新模型
可以使用以下命令训练新模型。
1、准备数据集
要在论文中的数据集上训练,可以下载数据集并使用 --dataset_mode 选项,该选项将选择加载 BaseDataset 上的哪个子类。对于自定义数据集,最简单的方法是使用./data/custom_dataset。通过指定选项 --dataset_mode custom,以及 --label_dir [path_to_labels] --image_dir [path_to_images]。你还需要指定更多选项,例如 --label_nc (数据集中标签类的数目),--contain_dontcare_label (指定是否有一个未知的标签),或者 --no_instance (表示地图数据集没有实例)。
2、训练
# To train on the Facades or COCO dataset, for example.python train.py --name [experiment_name] --dataset_mode facades --dataroot [path_to_facades_dataset]python train.py --name [experiment_name] --dataset_mode coco --dataroot [path_to_coco_dataset]# To train on your own custom datasetpython train.py --name [experiment_name] --dataset_mode custom --label_dir [path_to_labels] -- image_dir [path_to_images] --label_nc [num_labels]
你还可以指定许多选项,请使用 python train.py --help.
测试
测试与测试预训练模型相似
python test.py --name [name_of_experiment] --dataset_mode [dataset_mode] --dataroot [path_to_dataset]GitHub地址:
https://github.com/NVlabs/SPADE
新智元春季招聘开启,一起弄潮AI之巅!
岗位详情请戳:
.png")
【加入社群】
新智元AI技术+产业社群招募中,欢迎对AI技术+产业落地感兴趣的同学,加小助手微信号:aiera2015_2 入群;通过审核后我们将邀请进群,加入社群后务必修改群备注(姓名 - 公司 - 职位;专业群审核较严,敬请谅解)。



