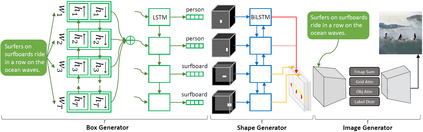
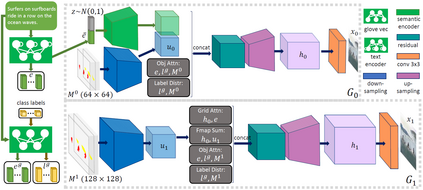
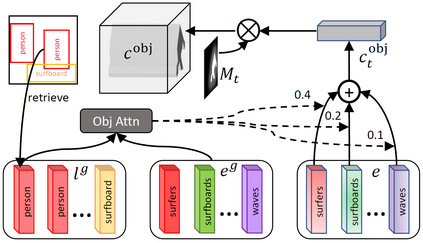
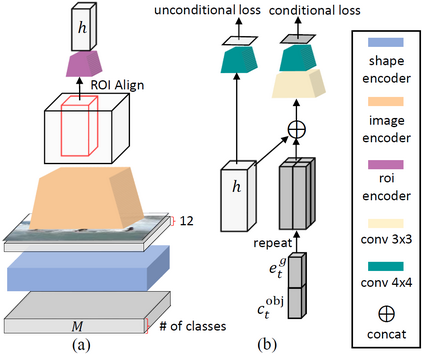
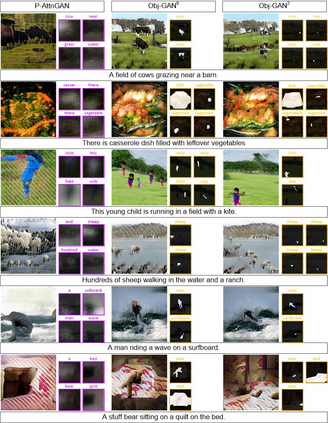
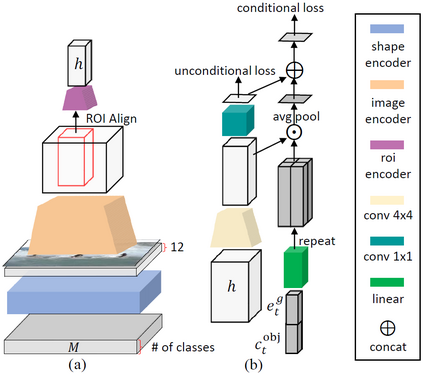
In this paper, we propose Object-driven Attentive Generative Adversarial Newtorks (Obj-GANs) that allow object-centered text-to-image synthesis for complex scenes. Following the two-step (layout-image) generation process, a novel object-driven attentive image generator is proposed to synthesize salient objects by paying attention to the most relevant words in the text description and the pre-generated semantic layout. In addition, a new Fast R-CNN based object-wise discriminator is proposed to provide rich object-wise discrimination signals on whether the synthesized object matches the text description and the pre-generated layout. The proposed Obj-GAN significantly outperforms the previous state of the art in various metrics on the large-scale COCO benchmark, increasing the Inception score by 27% and decreasing the FID score by 11%. A thorough comparison between the traditional grid attention and the new object-driven attention is provided through analyzing their mechanisms and visualizing their attention layers, showing insights of how the proposed model generates complex scenes in high quality.
翻译:在本文中,我们提议由物体驱动的加速生成自动生成式Newtork (Obj-GANs), 允许对复杂场景进行以物体为中心的文本到图像合成。 在两步(外观-图像)生成过程之后, 一个由物体驱动的新的关注图像生成器建议通过注意文字描述和预先生成的语义布局中最相关的词来合成突出的物体。 此外, 提议一个新的快速 R-CNN 的基于对象的区分器(Obj-GANs), 以提供关于合成对象是否与文本描述和预生成的布局相匹配的丰富的对象- 歧视信号。 拟议的 Obj- GAN 明显地超越了大型COCO基准中各种指标中以往的艺术状态, 将感知值提高27%, 并将FID 评分降低11% 。 通过分析传统电网的注意与新对象驱动的注意度进行彻底的比较, 分析其机制并直观它们的注意层, 显示对拟议模型如何产生高质量复杂场景象的洞察力。