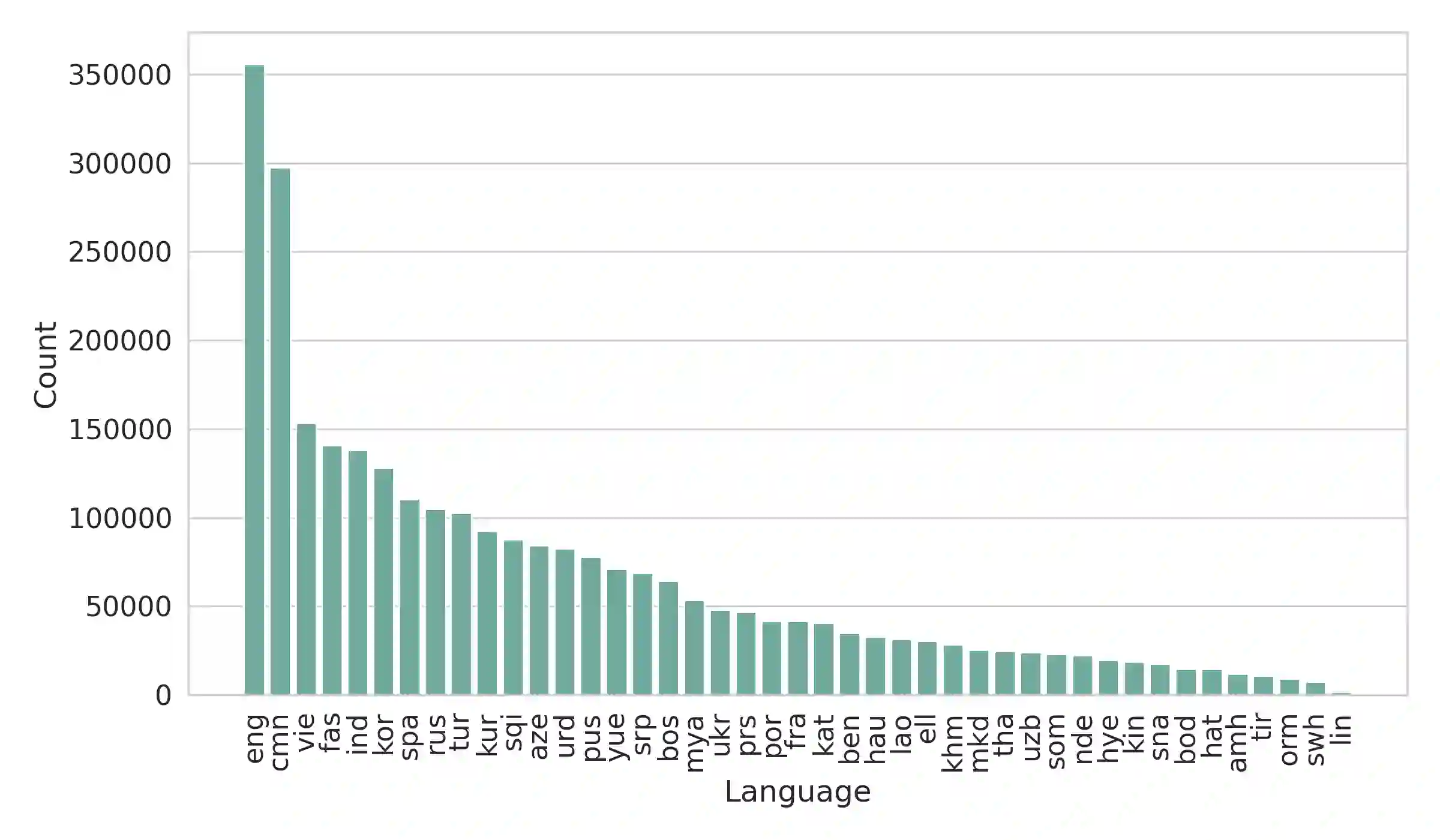
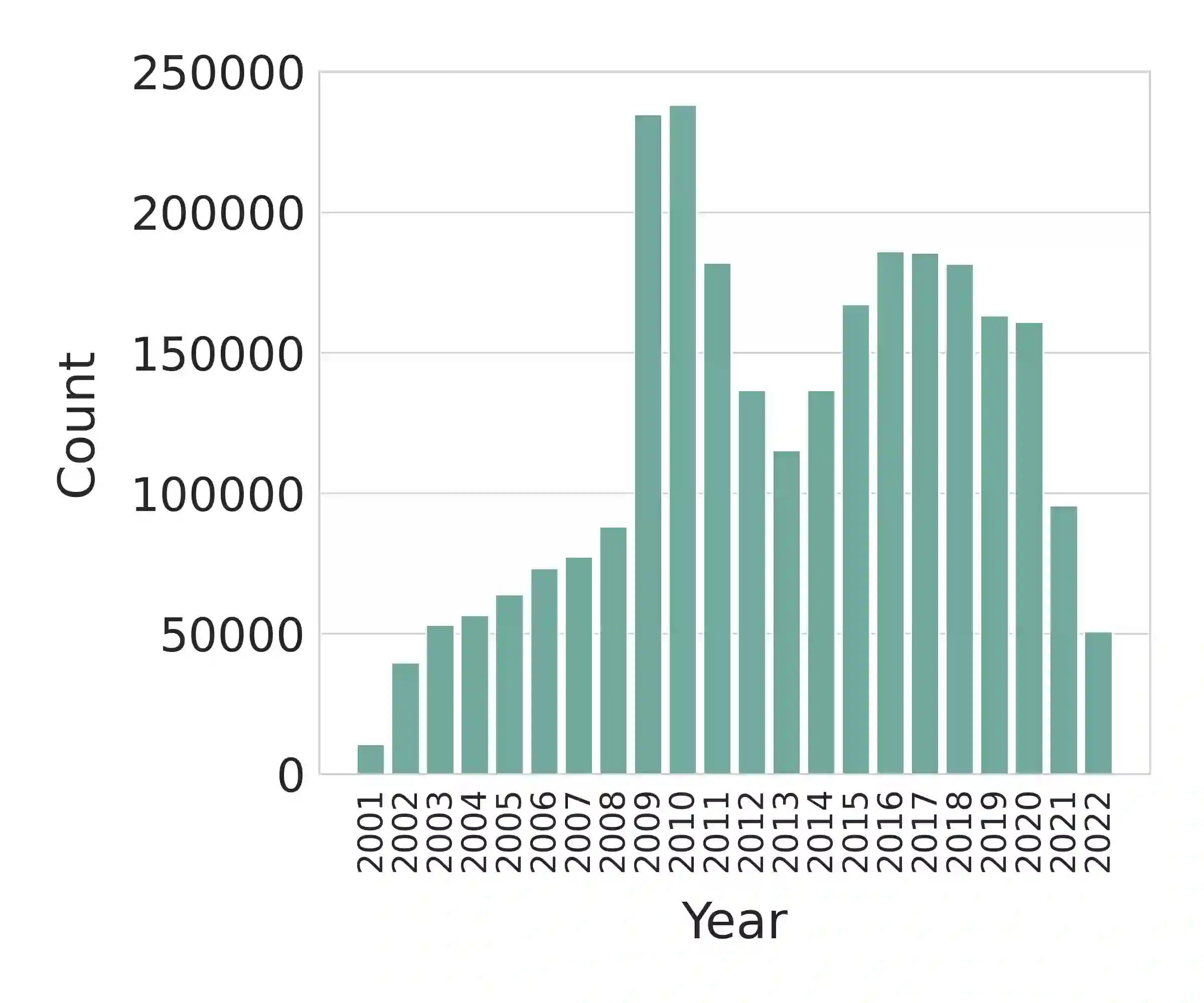
We present Multilingual Open Text (MOT), a new multilingual corpus containing text in 44 languages, many of which have limited existing text resources for natural language processing. The first release of the corpus contains over 2.8 million news articles and an additional 1 million short snippets (photo captions, video descriptions, etc.) published between 2001--2022 and collected from Voice of America's news websites. We describe our process for collecting, filtering, and processing the data. The source material is in the public domain, our collection is licensed using a creative commons license (CC BY 4.0), and all software used to create the corpus is released under the MIT License. The corpus will be regularly updated as additional documents are published.
翻译:我们推出了新的多语言开放文本(MOT),这是一个包含44种语言文本的新的多语言文件,其中许多语言现有文本资源有限,可用于自然语言处理,第一版包含280多万篇新闻文章和另外100万个短片(照片字幕、视频描述等),这些短片在2001至2022年期间出版,从美国之音新闻网站上收集。我们描述了我们收集、过滤和处理数据的过程。原始材料在公共领域,我们收藏的许可证是使用创造性的共同许可证(CC by 4.0),而用于创建该材料的所有软件都根据麻省理工学院许可证发布。随着其他文件的出版,该材料将定期更新。