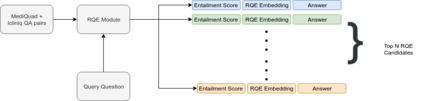
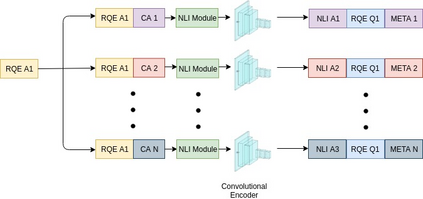
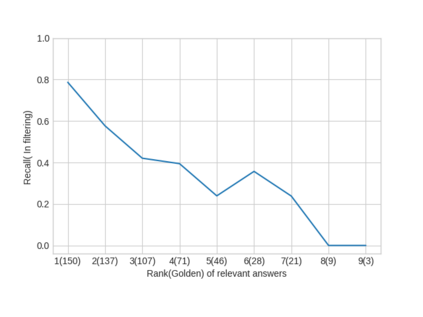
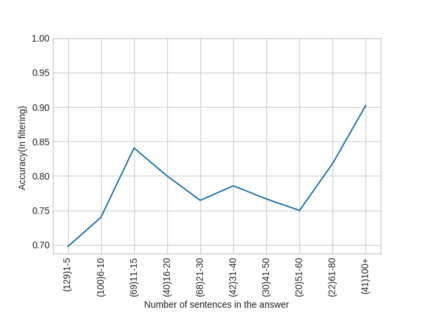
Parallel deep learning architectures like fine-tuned BERT and MT-DNN, have quickly become the state of the art, bypassing previous deep and shallow learning methods by a large margin. More recently, pre-trained models from large related datasets have been able to perform well on many downstream tasks by just fine-tuning on domain-specific datasets . However, using powerful models on non-trivial tasks, such as ranking and large document classification, still remains a challenge due to input size limitations of parallel architecture and extremely small datasets (insufficient for fine-tuning). In this work, we introduce an end-to-end system, trained in a multi-task setting, to filter and re-rank answers in the medical domain. We use task-specific pre-trained models as deep feature extractors. Our model achieves the highest Spearman's Rho and Mean Reciprocal Rank of 0.338 and 0.9622 respectively, on the ACL-BioNLP workshop MediQA Question Answering shared-task.
翻译:类似微调的BERT和MT-DNN等平行深层次学习结构很快成为最新水平,大大绕过了先前的深浅学习方法。最近,来自大型相关数据集的预培训模型通过对具体领域数据集进行微调,得以很好地完成许多下游任务。然而,由于在非三角任务上使用强大的模型,如排名和大文件分类,由于平行架构和极小数据集(不足以进行微调)的投入规模限制,仍是一个挑战。在这项工作中,我们引入了一个端对端系统,在多任务设置方面受过培训,用于筛选和重新排列医疗领域的答案。我们使用特定任务前培训模型作为深度地物提取器。我们的模型在ACL-BioNLP MediQA 问题回答共享任务上分别取得了最高Spearman Rho和中值的0.338 和0.9622 。