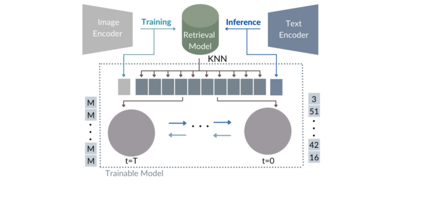
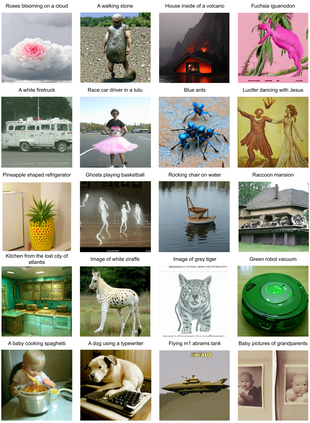
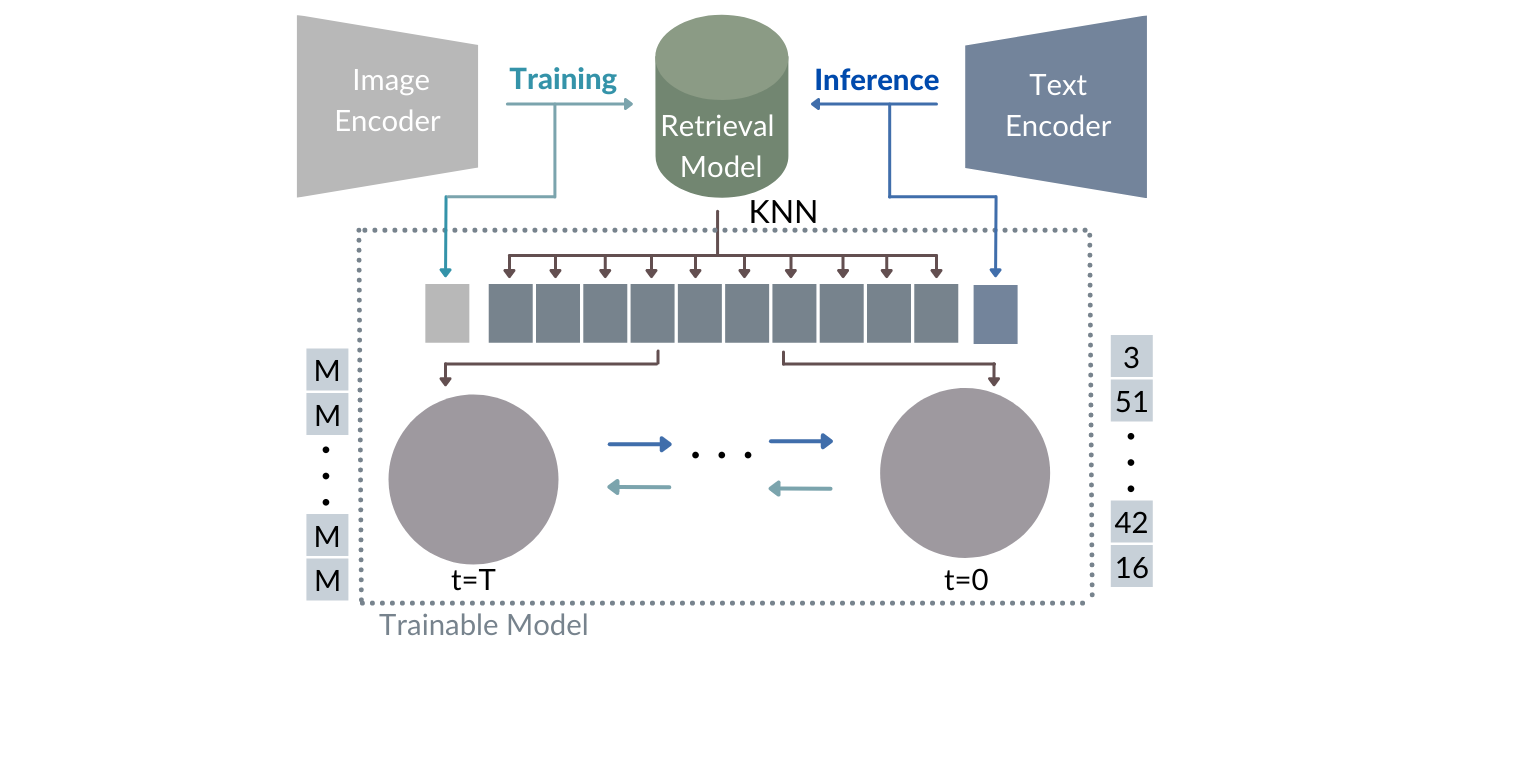
While the availability of massive Text-Image datasets is shown to be extremely useful in training large-scale generative models (e.g. DDPMs, Transformers), their output typically depends on the quality of both the input text, as well as the training dataset. In this work, we show how large-scale retrieval methods, in particular efficient K-Nearest-Neighbors (KNN) search, can be used in order to train a model to adapt to new samples. Learning to adapt enables several new capabilities. Sifting through billions of records at inference time is extremely efficient and can alleviate the need to train or memorize an adequately large generative model. Additionally, fine-tuning trained models to new samples can be achieved by simply adding them to the table. Rare concepts, even without any presence in the training set, can be then leveraged during test time without any modification to the generative model. Our diffusion-based model trains on images only, by leveraging a joint Text-Image multi-modal metric. Compared to baseline methods, our generations achieve state of the art results both in human evaluations as well as with perceptual scores when tested on a public multimodal dataset of natural images, as well as on a collected dataset of 400 million Stickers.
翻译:虽然大量文本图像数据集的可用性在培训大规模基因化模型(例如DDPMS、变异器)方面极为有用,但其输出通常取决于输入文本和培训数据集的质量。在这项工作中,我们展示了如何使用大规模检索方法,特别是高效的K-Nearest-Wearbors(KNN)搜索,以培训适合新样本的模型。学会适应使几个新的能力得以实现。在推断时通过数十亿记录筛选极为高效,可以减轻培训或记忆一个足够大的基因化模型的需要。此外,只要将经过培训的模型添加到表格中,就可以实现对新样本的微调。即使没有在培训数据集中出现,在测试期间也可以在不修改基因化模型的情况下加以利用。我们基于传播模型的图像培训只能通过利用文本-IMage多模式联合测量方法进行。与基线方法相比,我们几代人可以在人类评估400万个艺术成果方面实现状态,同时将收集的图像作为基础数据测试,同时将存储的模型,同时将采集成一个自然和存储的模型。