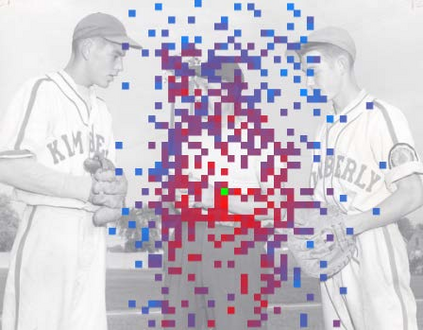
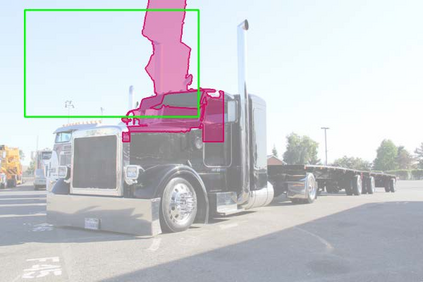
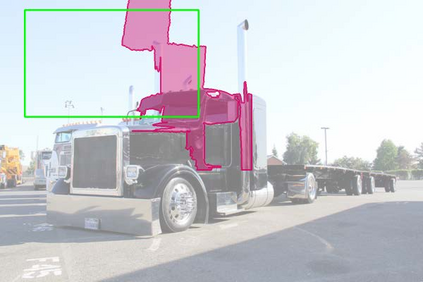
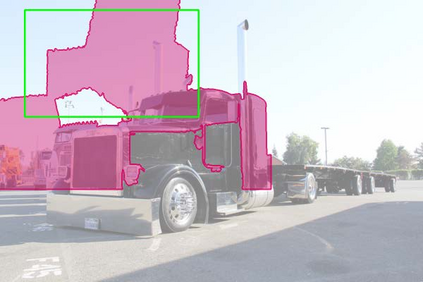
The superior performance of Deformable Convolutional Networks arises from its ability to adapt to the geometric variations of objects. Through an examination of its adaptive behavior, we observe that while the spatial support for its neural features conforms more closely than regular ConvNets to object structure, this support may nevertheless extend well beyond the region of interest, causing features to be influenced by irrelevant image content. To address this problem, we present a reformulation of Deformable ConvNets that improves its ability to focus on pertinent image regions, through increased modeling power and stronger training. The modeling power is enhanced through a more comprehensive integration of deformable convolution within the network, and by introducing a modulation mechanism that expands the scope of deformation modeling. To effectively harness this enriched modeling capability, we guide network training via a proposed feature mimicking scheme that helps the network to learn features that reflect the object focus and classification power of R-CNN features. With the proposed contributions, this new version of Deformable ConvNets yields significant performance gains over the original model and produces leading results on the COCO benchmark for object detection and instance segmentation.
翻译:变形变异网络的优异性能来自其适应物体的几何变化的能力。通过对其适应行为的审查,我们观察到,虽然对其神经功能的空间支持比常规的ConvNet更接近于目标结构,但这种支持可能远远超出感兴趣的区域,造成不相干图像内容的影响。为解决这一问题,我们提出了变形变异的ConvNet的重新组合,通过增加建模力和强化培训,提高了其关注相关图像区域的能力。通过在网络内更全面地整合变形变异性变异功能,并通过引入一个调制机制,扩大变形模型的范围,加强了模型的力量。为有效利用这种变异模型能力,我们通过一个拟议的功能模拟方案指导网络培训,帮助网络学习反映R-CNN特性的物体焦点和分类能力。根据拟议的贡献,变形的ConvNet新版本在原始模型上取得了显著的绩效收益,并在COCO物体探测和图像断段基准上产生了领先的成果。