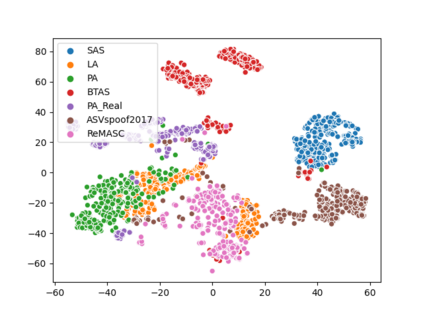
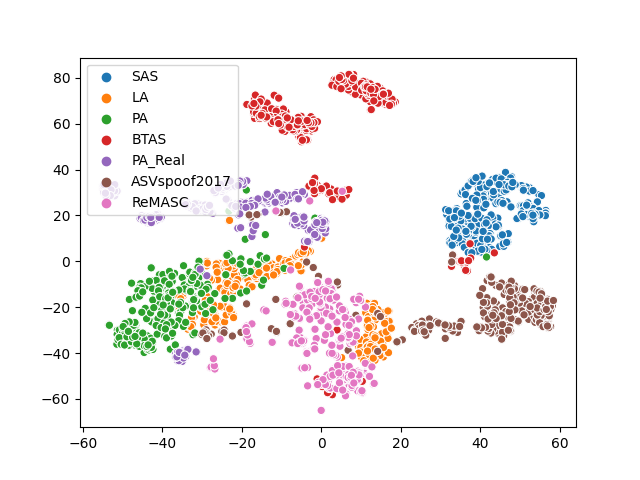
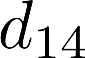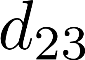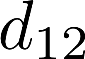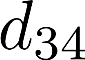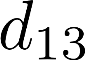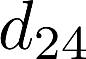Voice anti-spoofing aims at classifying a given speech input either as a bonafide human sample, or a spoofing attack (e.g. synthetic or replayed sample). Numerous voice anti-spoofing methods have been proposed but most of them fail to generalize across domains (corpora) -- and we do not know \emph{why}. We outline a novel interpretative framework for gauging the impact of data quality upon anti-spoofing performance. Our within- and between-domain experiments pool data from seven public corpora and three anti-spoofing methods based on Gaussian mixture and convolutive neural network models. We assess the impacts of long-term spectral information, speaker population (through x-vector speaker embeddings), signal-to-noise ratio, and selected voice quality features.
翻译:语音反播音的目的是将特定语音输入分类为真实的人类样本,或是一种假冒攻击(如合成或重播样本)。提出了许多声音反伪的方法,但大多数方法未能在各领域(公司)中一概而论 -- -- 我们不知道这是为什么。我们勾勒了一个用于衡量数据质量对反伪性能的影响的新的解释性框架。我们从七个公共公司和三个基于高斯混合和混凝土神经网络模型的反伪方法中收集了我们内部和内部的实验数据。我们评估了长期光谱信息、发言者群(通过X-Verctor喇叭嵌入)、信号对噪音比率和选定的声音质量特征的影响。