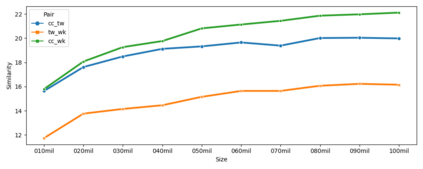
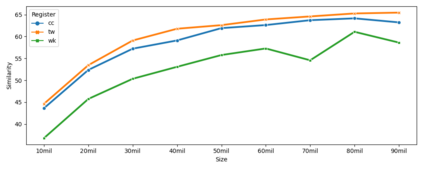
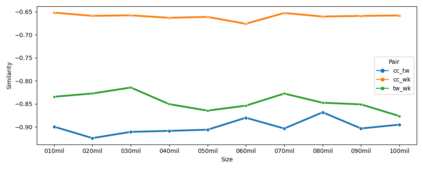
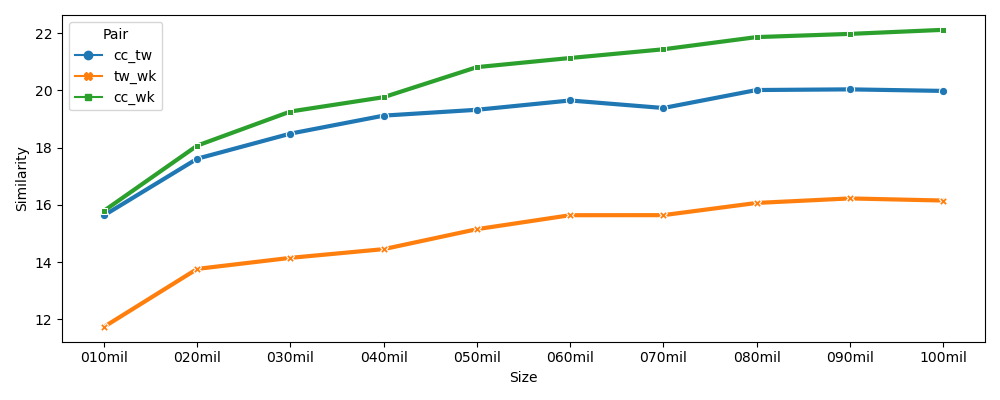
This paper simulates a low-resource setting across 17 languages in order to evaluate embedding similarity, stability, and reliability under different conditions. The goal is to use corpus similarity measures before training to predict properties of embeddings after training. The main contribution of the paper is to show that it is possible to predict downstream embedding similarity using upstream corpus similarity measures. This finding is then applied to low-resource settings by modelling the reliability of embeddings created from very limited training data. Results show that it is possible to estimate the reliability of low-resource embeddings using corpus similarity measures that remain robust on small amounts of data. These findings have significant implications for the evaluation of truly low-resource languages in which such systematic downstream validation methods are not possible because of data limitations.
翻译:本文模拟了17种语言的低资源环境,以评价在不同条件下嵌入相似性、稳定性和可靠性;目的是在培训前使用大量相似性措施,以预测培训后嵌入的特性;主要贡献是表明有可能利用上游物质类似性措施预测下游嵌入相似性;然后,通过模拟从非常有限的培训数据中生成的嵌入的可靠性,将这一结论应用于低资源环境;结果显示,有可能利用对少量数据仍保持稳健的质态类似性措施来估计低资源嵌入的可靠性;这些结论对评估真正低资源语言有重大影响,因为数据有限,无法使用这种系统的下游验证方法。