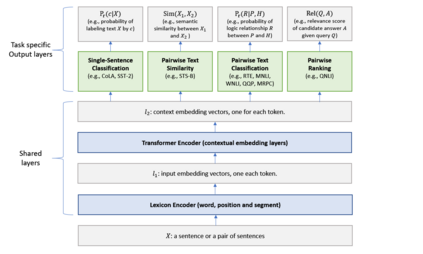
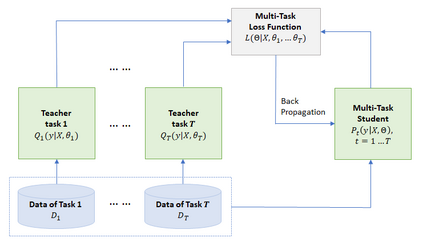
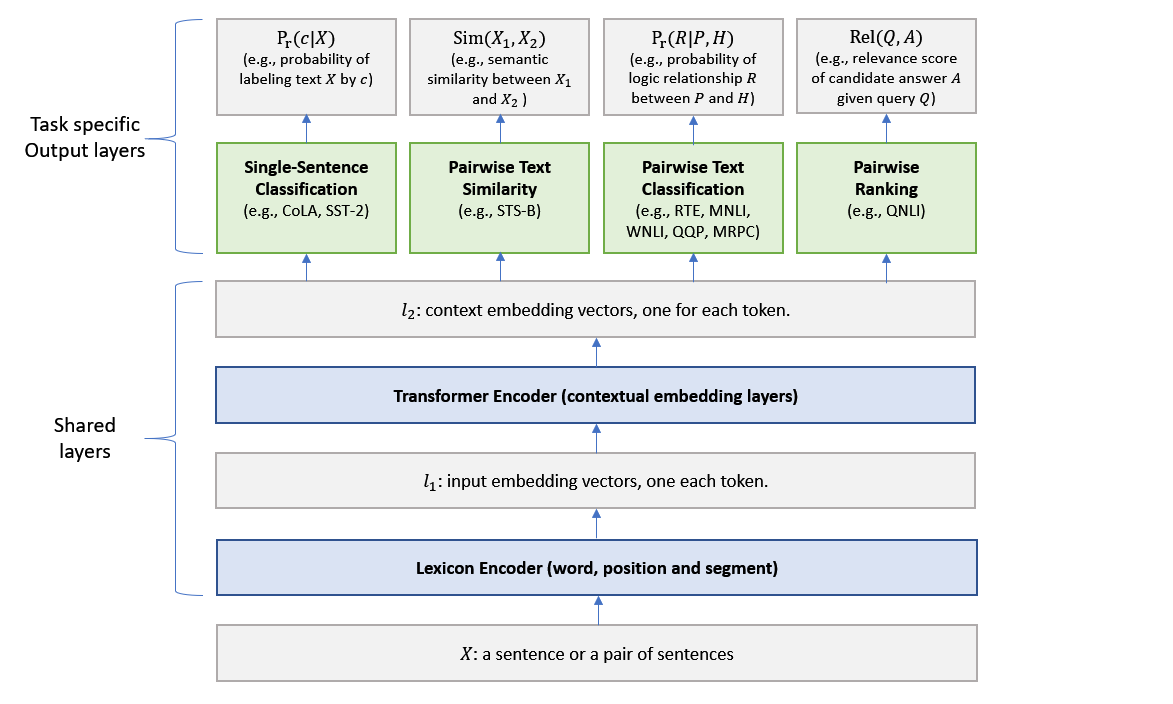
This paper explores the use of knowledge distillation to improve a Multi-Task Deep Neural Network (MT-DNN) (Liu et al., 2019) for learning text representations across multiple natural language understanding tasks. Although ensemble learning can improve model performance, serving an ensemble of large DNNs such as MT-DNN can be prohibitively expensive. Here we apply the knowledge distillation method (Hinton et al., 2015) in the multi-task learning setting. For each task, we train an ensemble of different MT-DNNs (teacher) that outperforms any single model, and then train a single MT-DNN (student) via multi-task learning to \emph{distill} knowledge from these ensemble teachers. We show that the distilled MT-DNN significantly outperforms the original MT-DNN on 7 out of 9 GLUE tasks, pushing the GLUE benchmark (single model) to 83.7\% (1.5\% absolute improvement\footnote{ Based on the GLUE leaderboard at https://gluebenchmark.com/leaderboard as of April 1, 2019.}). The code and pre-trained models will be made publicly available at https://github.com/namisan/mt-dnn.
翻译:本文探索如何利用知识蒸馏法改进多任务深神经网络(MT- DNN)(Liu等人,2019年),以在多种自然语言理解任务中学习文本代表。尽管混合学习可以提高模型性能,但能为大型DNN(如MT-DNN)等大型DNN(如MT-DNN)提供连锁服务,费用可高得令人望而却步。在这里,我们在多任务学习环境中应用了知识蒸馏法(Hinton等人,2015年),对于每一项任务,我们培训了一个超越任何单一模式的不同MT-DNN(教师)的集合体,然后通过多任务学习来培训单一的MT-DNN(学生) (MT-DNN) 。 我们显示,在9项GLUE任务中7项的原始MT- DNNN(H,2015年), 将GLUE基准(Singlegle 模型) 推向83.7\\ (1.5\ 绝对改进\ foot notn_fornotement {blead基础, 在 httpGLUEILUI/ beld_Bardard 上, 2019 begleadroadroadd.