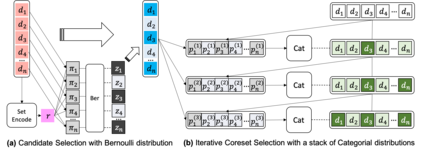
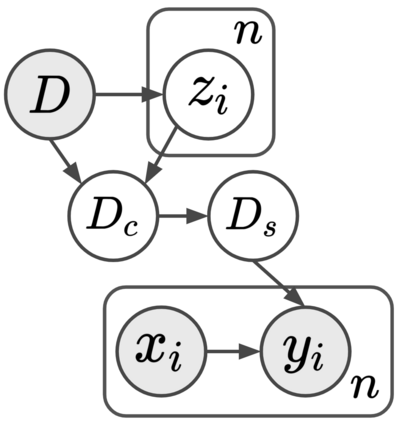
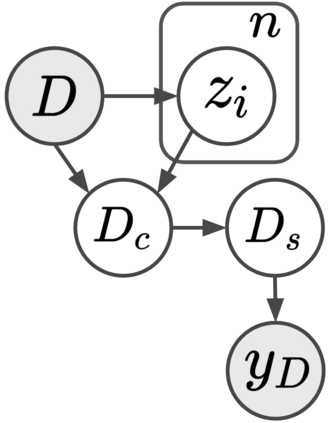
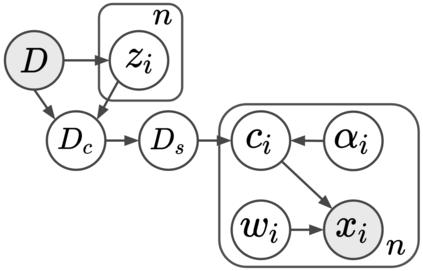
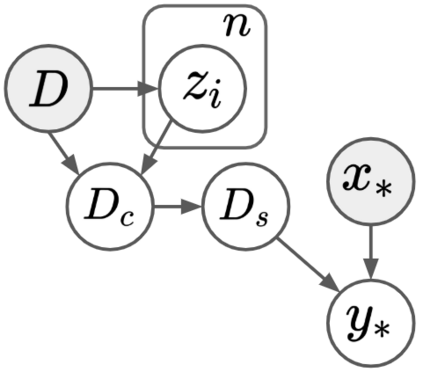
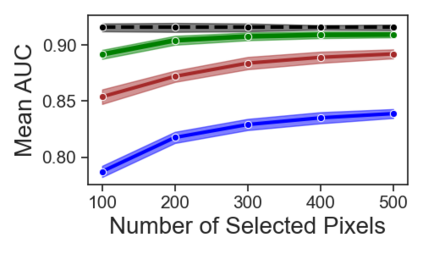
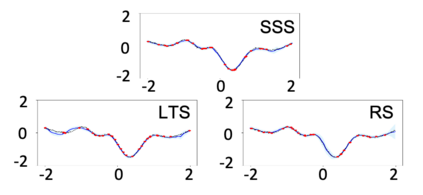
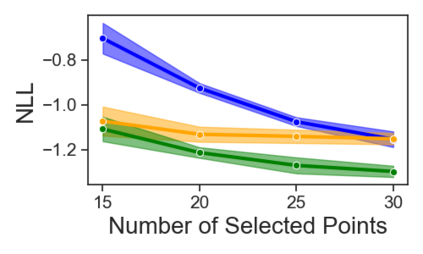
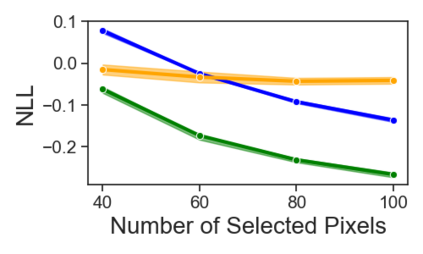
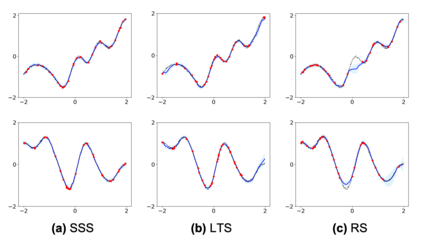
Current machine learning algorithms are designed to work with huge volumes of high dimensional data such as images. However, these algorithms are being increasingly deployed to resource constrained systems such as mobile devices and embedded systems. Even in cases where large computing infrastructure is available, the size of each data instance, as well as datasets, can provide a huge bottleneck in data transfer across communication channels. Also, there is a huge incentive both in energy and monetary terms in reducing both the computational and memory requirements of these algorithms. For non-parametric models that require to leverage the stored training data at the inference time, the increased cost in memory and computation could be even more problematic. In this work, we aim to reduce the volume of data these algorithms must process through an end-to-end two-stage neural subset selection model, where the first stage selects a set of candidate points using a conditionally independent Bernoulli mask followed by an iterative coreset selection via a conditional Categorical distribution. The subset selection model is trained by meta-learning with a distribution of sets. We validate our method on set reconstruction and classification tasks with feature selection as well as the selection of representative samples from a given dataset, on which our method outperforms relevant baselines. We also show in our experiments that our method enhances scalability of non-parametric models such as Neural Processes.
翻译:目前的机器学习算法旨在利用大量高维数据,如图像等。然而,这些算法正越来越多地被运用到诸如移动装置和嵌入系统等资源有限的系统。即便在有大型计算基础设施的情况下,每个数据实例和数据集的大小也能为跨通信渠道的数据传输提供巨大的瓶颈。此外,在减少这些算法的计算和记忆要求方面,在能源和货币方面都有着巨大的动力。对于非参数模型来说,为了在推论时间利用储存的培训数据,记忆和计算成本的增加可能更成问题。在这项工作中,我们的目标是减少数据的数量,这些算法必须通过一个端到端两阶段的神经子选择模型进行处理,第一阶段利用一个有条件的独立的伯努尔尼利掩码选择一组候选点,然后通过一个有条件的剖析分布法进行迭代核心集选择。子选择模型通过元学习和一组数据集的分布来培训。我们验证了我们关于设置重建与分类任务的方法,其特性选择必须经过一个端至端两个阶段的精度分数选择模型。我们从一个有代表性的模型中选择一个比重的模型。我们从一个比重的模型的模型来显示一个比重的模型。