成为VIP会员查看完整内容
VIP会员码认证
首页
主题
发现
会员
服务
注册
·
登录
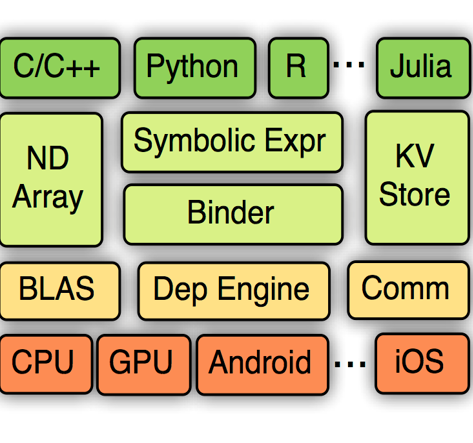
深度学习框架
关注
99
综合
百科
VIP
热门
动态
论文
精华
PyTorch 成为 Linux 基金会的顶级项目
InfoQ
0+阅读 · 2022年11月7日
华为昇思AI挑战赛,6万奖金、3大赛道、参与即有奖|竞赛报名
量子位
1+阅读 · 2022年9月15日
活动报名 | AI思享会:新一代AI基础软件发展探讨
THU数据派
1+阅读 · 2022年9月5日
活动报名 | AI思享会:中国AI基础软件发展探讨
THU数据派
1+阅读 · 2022年8月24日
WAIC 开发者日Workshop预告:旷视天元 MegEngine 推动低比特量化技术的落地
机器之心
0+阅读 · 2022年8月24日
超越TensorFlow、PyTorch,百度飞桨登顶中国市场应用规模第一 | 信通院最新报告
量子位
2+阅读 · 2022年8月2日
计图:5秒训好NeRF!已开源
量子位
5+阅读 · 2022年6月5日
对话「一流科技」创始人袁进辉:瞄准AI底层架构,打造人工智能深度学习框架OneFlow
创业邦杂志
0+阅读 · 2022年4月26日
许锦波团队开发蛋白逆折叠深度学习框架,用更少结构数据训练获得更准确序列预测
机器之心
0+阅读 · 2022年4月24日
解读 Pathways (二):向前一步是 OneFlow
THU数据派
0+阅读 · 2022年4月15日
中国开源深度学习框架第六年:百度飞桨国内综合份额第一,全球开发者超400万
量子位
0+阅读 · 2022年4月8日
稚晖君与昇思MindSpore一起过TechDay生日趴!
PaperWeekly
0+阅读 · 2022年3月26日
昇思MindSpore TechDay重磅来袭!聚焦AI技术创新与开发者成长
PaperWeekly
0+阅读 · 2022年3月24日
哈工大博士历时半年整理的《Pytorch常用函数函数手册》开放下载!内含200余个函数!
夕小瑶的卖萌屋
7+阅读 · 2022年3月23日
参考链接
父主题
深度学习
子主题
Deeplearning4j
TensorFlow
MXNet
PyTorch
Theano
ONNX
Torch
Caffe
PaddlePaddle(飞桨)
Darknet
提示
微信扫码
咨询专知VIP会员与技术项目合作
(加微信请备注: "专知")
微信扫码咨询专知VIP会员
Top