成为VIP会员查看完整内容
VIP会员码认证
首页
主题
发现
会员
服务
注册
·
登录
深度学习
关注
7681
机器学习的一个分支,它基于试图使用包含复杂结构或由多重非线性变换构成的多个处理层对数据进行高层抽象的一系列算法。
综合
百科
荟萃
VIP
热门
动态
论文
精华
Limits of trust in medical AI
Arxiv
0+阅读 · 4月3日
A GAN-Enhanced Deep Learning Framework for Rooftop Detection from Historical Aerial Imagery
Arxiv
0+阅读 · 4月3日
Towards Assessing Deep Learning Test Input Generators
Arxiv
0+阅读 · 4月3日
Cooper: A Library for Constrained Optimization in Deep Learning
Arxiv
0+阅读 · 4月1日
Machine Unlearning Fails to Remove Data Poisoning Attacks
Arxiv
0+阅读 · 4月1日
Causal Concept Graph Models: Beyond Causal Opacity in Deep Learning
Arxiv
0+阅读 · 4月1日
Oriented Object Detection in Optical Remote Sensing Images using Deep Learning: A Survey
Arxiv
0+阅读 · 4月1日
A Multi-Stage Auto-Context Deep Learning Framework for Tissue and Nuclei Segmentation and Classification in H&E-Stained Histological Images of Advanced Melanoma
Arxiv
0+阅读 · 3月31日
Certified Approximate Reachability (CARe): Formal Error Bounds on Deep Learning of Reachable Sets
Arxiv
0+阅读 · 3月31日
A SAT-centered XAI method for Deep Learning based Video Understanding
Arxiv
0+阅读 · 3月31日
Data Poisoning in Deep Learning: A Survey
Arxiv
0+阅读 · 3月27日
THEMIS: Towards Practical Intellectual Property Protection for Post-Deployment On-Device Deep Learning Models
Arxiv
0+阅读 · 3月31日
Deep Learning Model Deployment in Multiple Cloud Providers: an Exploratory Study Using Low Computing Power Environments
Arxiv
0+阅读 · 3月31日
Hiding Latencies in Network-Based Image Loading for Deep Learning
Arxiv
0+阅读 · 3月28日
Interpretable Deep Learning Paradigm for Airborne Transient Electromagnetic Inversion
Arxiv
0+阅读 · 3月28日
参考链接
父主题
专知—深度学习:算法到实战
神经网络
子主题
自编码器
深度学习框架
Afshine Amidi
百度深度学习技术平台部
深度前馈网络
生成式对抗网络
激活函数
Dropout
深度学习花书
前馈神经网络
自动深度学习
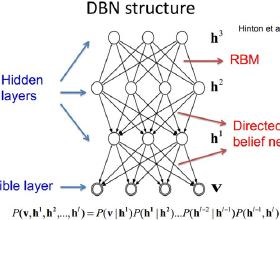
深度信念网络
循环神经网络
图深度学习
多模态
卷积神经网络
Nesterov 动量
预训练模型
随机梯度下降
提示
微信扫码
咨询专知VIP会员与技术项目合作
(加微信请备注: "专知")
微信扫码咨询专知VIP会员
Top