

随着ChatGPT的成功普及,基于Transformer的大型语言模型(LLMs)为通往人工通用智能(AGI)铺平了一条革命性的道路,并已在诸多领域中得到应用,比如作为知识库、人机界面和动态代理。然而,一个普遍的限制存在:许多当前的LLMs,由于资源的限制,主要是在较短的文本上进行预训练的,这使得它们在处理更长上下文的提示时效果不佳,而这种情况在现实世界中是常见的。在本文中,我们提供了一份综述,专注于基于Transformer的LLMs模型架构的进步,以优化从预训练到推理的所有阶段的长上下文处理能力。首先,我们描述并分析了当前基于Transformer模型处理长上下文输入和输出的问题。然后,我们主要提供了一个全面的分类,以解决这些问题的Transformer升级架构的领域。之后,我们提供了对长上下文LLMs广泛使用的评估必需品的调查,包括数据集、度量标准和基线模型,以及一些惊人的优化工具包,如库、系统和编译器,以提高LLMs在不同阶段的效率和效果。最后,我们进一步讨论了这一领域的主要挑战和未来研究的潜在途径。此外,我们建立了一个存储库,在 https://github.com/Strivin0311/long-llms-learning 处实时更新相关文献。
https://www.zhuanzhi.ai/paper/f0b7a0a949304cd3aafb05b9ed4ab7ce
近年来,借助深度学习技术[93],特别是基于Transformer的模型(如BERT [45]、GPT [134, 135, 17]及其变体[97, 105, 137])的兴起,自然语言处理(NLP)已经取得了显著进步,使机器能够理解和生成人类语言[170, 98],从而在自然语言理解(NLU)的众多任务中引起了革命,例如情感分析[206],自然语言生成(NLG)如文档摘要[51],以及其他领域如计算机视觉[81]和自动驾驶[67]。此外,在ChatGPT [121]、PaLM [36]、GPT4 [123, 122]等的推动下,基于Transformer的大型语言模型(LLMs),其规模扩大到1B∼100B参数以激发新能力[183],已显示出通向人工通用智能(AGI)[18]的新兴路线,并迅速被应用于众多人机交互应用中,如聊天机器人[146, 95]、编程助手[184, 196]和教育导师[1, 117]。 Transformer是一个精密的深度神经网络模型,它结合了许多伟大的先前设计[8, 65, 7],并包含多种新颖的组件,最初是为了解决机器翻译中的序列到序列语言建模问题[175]。当代的LLMs大多基于Transformer架构的基础上,采用其全部或部分模块[45, 134, 137]。在这些组件中,基于Transformer的LLMs主要因其核心设计良好的注意力机制而成功,该机制捕获整个输入中每对标记之间的全局依赖性,使模型能够处理具有复杂关系的序列。虽然注意力机制提供了显著的性能,但其与输入序列长度成二次方的时间和空间复杂度导致了显著的计算资源瓶颈,这不仅限制了训练期间允许的输入文本长度,而且由于生成标记增加时的效率不足和昂贵的缓存内存消耗,也限制了提示的有效上下文窗口。对于推理来说更糟糕的是,当LLMs面对比训练中的序列更长的序列时,也会因为输入长度的普遍化机制设计不良而性能下降。
然而,随着LLMs在需要长上下文理解[193, 87]和生成[106, 68]的各种应用中深入人心,对能够有效和高效地理解和生成极长序列的长上下文LLMs的需求变得越来越必不可少和迫切。因此,研究人员投入了大量努力来增强Transformer架构,以解决LLMs中的长上下文问题,包括对注意力效率的优化(第3节)、通过额外内存机制扩展上下文窗口(第4节)、通过外推位置嵌入实现有效的长度泛化(第5节)、上下文预/后处理(第6节),以及其他杂项方法(第7节),如特定的预训练目标、专家混合、量化、并行等。
这段文字是关于长上下文语言模型(LLMs)领域的一篇综述。它提到了长上下文LLMs是一个非常热门且发展迅速的研究领域,其中一些现有的综述文献汇总了相关文献工作。这些综述中,有的提供了关于长文档摘要的概述,但没有深入探讨长文本建模的内在技术。其他综述主要集中在提高长文本场景下Transformer的计算效率上。还有的综述强调LLMs在处理长序列时面临的挑战,讨论的方法主要与高效的Transformer相关。最近的一项工作更接近于这篇综述的研究,介绍了长文本建模和Transformer应用的方法,涵盖了预处理技术、部分高效的Transformer和长文档的特殊特性。然而,目前还缺乏全面的研究来回顾文献,探索从操作角度改进Transformer架构,以打破上下文长度的限制,实现更复杂、可扩展的基于Transformer的LLMs。
这篇综述的目标是全面回顾文献中关于扩大现有基于Transformer的LLMs有效上下文窗口长度的架构演变。主要贡献包括:
建立了一个全面的分类法,将Transformer架构分解为五部分,并探讨在每个阶段(包括预训练、微调、推理和预/后处理)增强长上下文LLMs的现有方法。
探索广泛使用的评估需求,包括数据集、度量标准和特别评估LLMs长上下文能力的基线,以及一些流行的优化工具包,以提高LLMs在训练和推理过程中的效率和效果。
确定改造Transformer结构以处理广泛上下文的关键挑战,并提出相应的未来方向以推动前沿。
考虑到这个领域的极速发展,构建了一个收集该特定领域相关文献的仓库,并将持续更新,帮助读者跟上最新进展。
综述的组织结构如下:第2节概述了长上下文LLMs,包括语言建模的目标和阶段、基于Transformer的LLMs的关键组成部分、LLMs处理长上下文的结构限制分析以及现有努力提升Transformer架构的分类。接下来的五个部分(第3、4、5、6、7节)主要深入讨论分类中的每一部分方法。第8节总结了长上下文能力评估的必要条件,并收集了一些流行的优化工具包,以提高LLMs在训练和推理过程中的效果和效率。第9节探讨了关键挑战及其带来的潜在机遇,并从现有突破中得出洞见。最后,第10节以对这个领域全景的总体结论以及这项研究的动机结束了这篇综述。
总述
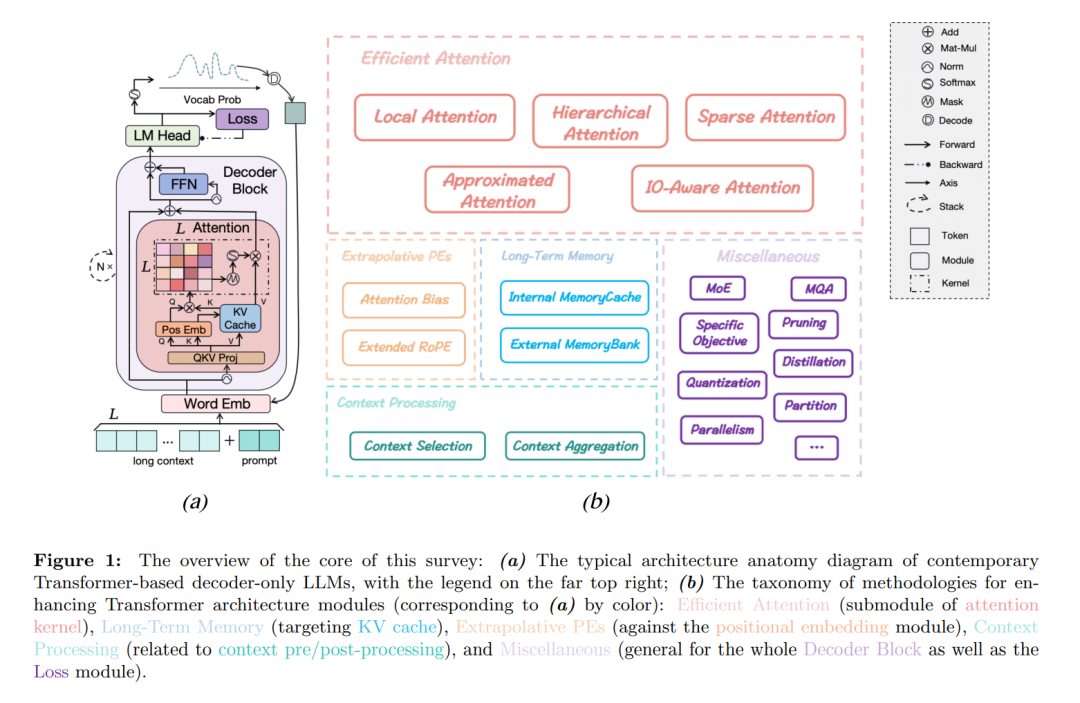
在本节中,我们首先从基础语言模型目标、典型模型阶段到变换器(Transformer)基础的仅解码器大型语言模型(LLMs)中关键的架构模块进行初步介绍(见图1 (a))。随后,我们对于当LLMs遇到广泛上下文窗口时的架构限制进行了简要分析(见2.2节)。最后,我们提出了一个全面的方法学分类(见2.3节),旨在通过架构创新提高LLMs的长上下文处理能力(见图1 (b))。此分类将作为接下来的五个部分——第3、4、5、6、7节的指导方针。
基于2.1节所提出的基础见解和2.2节讨论的限制,有多种途径可以探索,以提升变换器(Transformer)结构,赋予大型语言模型(LLMs)更强的长上下文处理能力。例如,通过减少训练期间的注意力复杂性、设计高效的记忆机制、增强长度外推能力,正如[129]所概述的那样,模型在短序列上进行训练,但在推理时测试更长的序列。因此,在本文中,我们提供了对最近旨在改善LLMs长上下文能力的方法学进展的全面回顾,并将它们组织成统一的分类法,如图1 (b)所示。具体来说,这些方法被分为以下五个主要类别: • 高效注意力(第3节):这些方法侧重于实施计算需求降低的高效注意力机制,甚至实现线性复杂性。通过这样做,它们在预训练阶段直接增加了Lmax,从而扩展了LLMs在推理期间有效上下文长度边界。 第一类方法致力于优化注意力机制,特别是关注那些使变换器(Transformer)模块成为计算瓶颈的核心操作(见公式4)。这种方法在推理过程中通过直接增加预训练阶段的超参数Lmax,使大型语言模型(LLMs)的有效上下文长度边界得以扩展。我们进一步将这些方法分为五种不同的策略,每种都有特定的焦点:局部注意力(第3.1节)、分层注意力(第3.2节)、稀疏注意力(第3.3节)、近似注意力(第3.4节)和IO-感知注意力(第3.5节)。
• 长期记忆(第4节):为了解决上下文工作记忆的限制,一些方法旨在设计明确的记忆机制,以弥补LLMs中高效和有效的长期记忆的缺乏。 由于在上下文工作记忆中的作用,Transformer架构通常难以捕捉长期依赖性,正如第2.2节所强调的。研究人员探索了两个主要途径来应对这一挑战,同时不损害全注意力的优势。首先,受到RNNs的启发,一些研究者将递归机制引入到注意力中,通过将内部记忆缓存整合进注意力层。这种方法使模型能够在更长的序列上维护和检索信息,弥补了内建长期记忆的固有缺乏。其次,另一种方法涉及利用现有模型作为外部知识库的接口,如特定文档或数据集。在推理过程中,模型可以从这些知识库中读取信息以丰富其上下文输入,并且可以根据用户的响应向它们写入信息以刷新其长期记忆。通过以这种方式整合外部知识,模型获得了访问更广泛上下文的能力,从而有效提升其处理长期依赖性的能力。
• 外推性位置编码(第5节):最近的努力旨在通过改进现有位置编码方案的外推性能力,提高LLMs的长度泛化能力。 认识到需要将推理长度的边界推向超出Lmax的范围,研究社区在这方面做出了显著努力。值得注意的是,根据[5],他们已经确定,在偶数任务的长度泛化中失败的主要原因是分心因素。然而,通过像scratchpad提示[120]这样的方法,这些问题可以被大幅度减轻。尽管如此,在本节中,我们的重点仍然在于当前位置编码(PEs)在更普遍场景中长度泛化中不可否认的作用。
• 上下文处理(第6节):除了提升特定低级变换器模块的方法外,一些方法涉及将现成的LLMs与额外的上下文预/后处理相结合。这些方法确保每次调用时提供给LLMs的输入始终满足最大长度要求,并通过引入多次调用开销来打破上下文窗口限制。 早前讨论的许多方法论提出了围绕Transformer架构中的注意力模块的复杂设计,包括高效的注意力核心(第3节)、长期记忆机制(第4节)和外推性位置编码(PEs)(第5节)。相比之下,还存在一些更简单、更直接的方法,将预训练的大型语言模型(LLMs)视为黑盒或灰盒模型。这些方法通过多次调用模型来解决处理超出模型长度限制的长上下文输入的挑战,确保每次调用时提供给LLM的实际输入不超过Lmax。尽管这些方法没有显式地增强LLMs处理长上下文的固有能力,但它们利用LLMs显著的在上下文中的学习能力来解决这个问题,尽管代价是增加了计算量和可能减少了答案的准确性。 • 其他(第7节):这一部分探索了各种不完全符合前四个类别的通用且有价值的方法,为在LLMs中提高长上下文能力提供了更广泛的视角。
结论
在这篇综述中,我们全面地导航了基于Transformer的大型语言模型(LLMs)的架构进步领域,以增强在各个发展阶段处理广泛上下文窗口的能力,采用了一个全面的分类法,将这些针对Transformer中不同模块设计的方法论进行分类。然后,我们探讨了长文本任务特有的评估必要性以及一些集成了多种工具的优化工具包,用以增强LLMs的效率和有效性。我们进一步确定了关键挑战及其对应的未来方向。此外,我们的存储库确保读者能够及时了解这一动态领域的最新研究。随着LLMs的快速发展,我们真诚地希望我们的综述能成为研究人员的宝贵资源,帮助他们利用LLMs的力量构建强大的长上下文LLMs,最终推动走向通用人工智能(AGI)时代的追求。
