
微软亚洲研究院提出的 OCR 方法的主要思想是显式地把像素分类问题转化成物体区域分类问题,这与语义分割问题的原始定义是一致的,即每一个像素的类别就是该像素属于的物体的类别,换言之,与 PSPNet 和 DeepLabv3 的上下文信息最主要的不同就在于 OCR 方法显式地增强了物体信息。
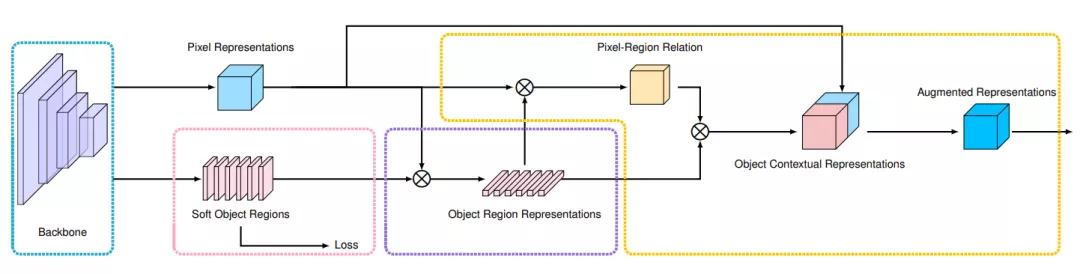
OCR 方法的实现主要包括3个阶段:(1) 根据网络中间层的特征表示估测一个粗略的语义分割结果作为 OCR 方法的一个输入 ,即软物体区域(Soft Object Regions),(2) 根据粗略的语义分割结果和网络最深层的特征表示计算出 K 组向量,即物体区域表示(Object Region Representations),其中每一个向量对应一个语义类别的特征表示,(3) 计算网络最深层输出的像素特征表示(Pixel Representations)与计算得到的物体区域特征表示(Object Region Representation)之间的关系矩阵,然后根据每个像素和物体区域特征表示在关系矩阵中的数值把物体区域特征加权求和,得到最后的物体上下文特征表示 OCR (Object Contextual Representation) 。当把物体上下文特征表示 OCR 与网络最深层输入的特征表示拼接之后作为上下文信息增强的特征表示(Augmented Representation),可以基于增强后的特征表示预测每个像素的语义类别,具体算法框架可以参考图6。综上,OCR 可计算一组物体区域的特征表达,然后根据物体区域特征表示与像素特征表示之间的相似度将这些物体区域特征表示传播给每一个像素。
OCRNet 框架: https://www.zhuanzhi.ai/paper/e2dfdc82307194b70ba81ef91a6f82d4
