

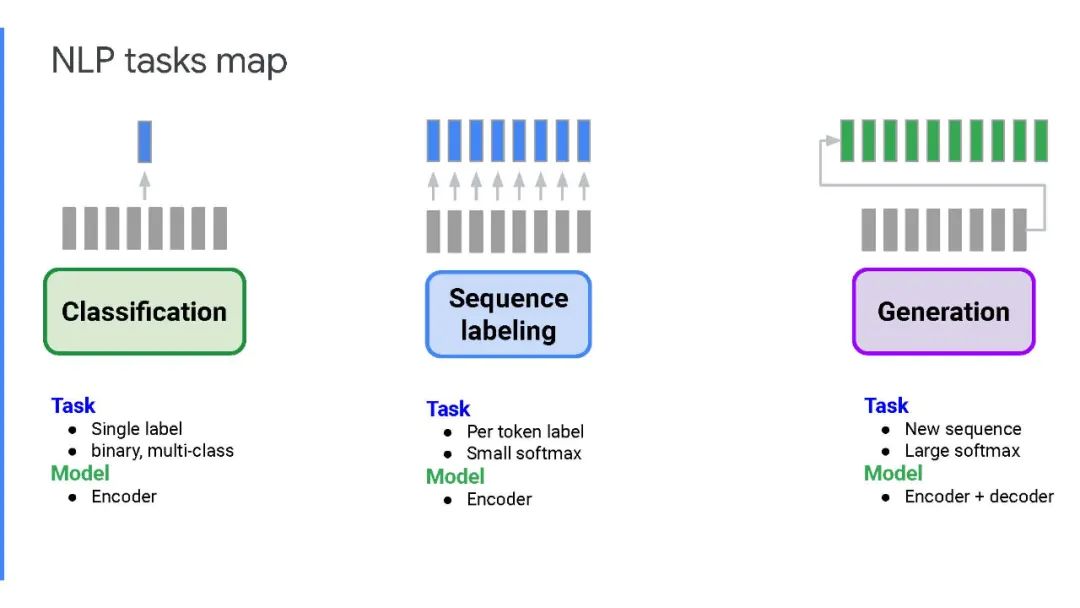
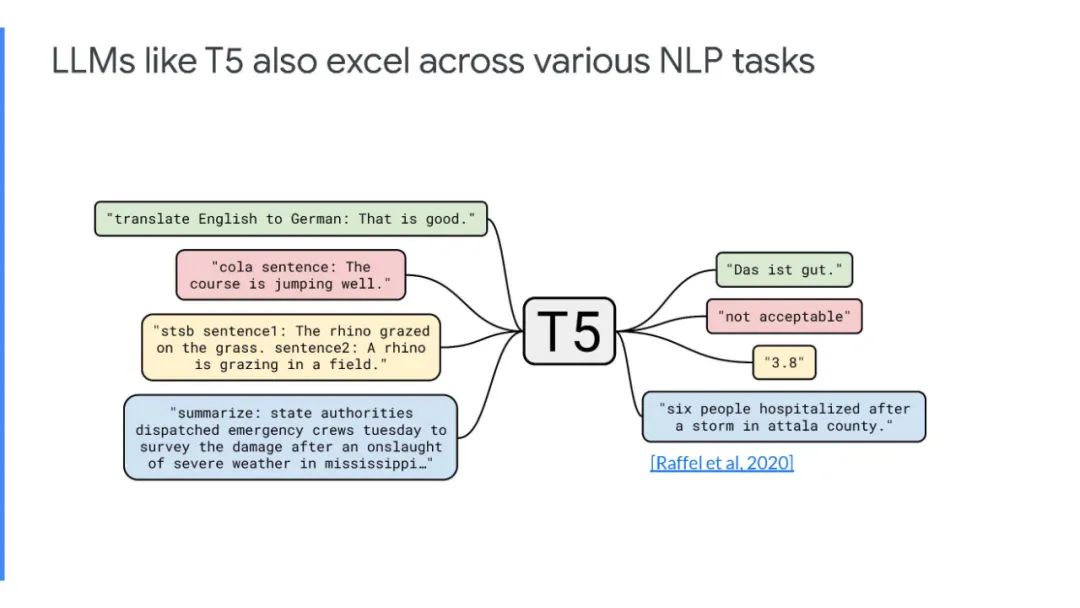
文本编辑模型最近已经成为seq2seq模型在单语言文本生成任务(如语法错误纠正、文本简化和样式转移)中的重要替代方案。这些任务有一个共同的特点——它们在源文本和目标文本之间表现出大量的文本重叠。
文本编辑模型利用了这一观察结果,并通过预测应用于源序列的编辑操作来生成输出。相反,seq2seq模型从头开始逐字生成输出,因此在推断时速度很慢。文本编辑模型比seq2seq模型有几个优点,包括更快的推理速度、更高的样本效率、更好的输出控制和可解释性。
本教程提供了基于文本编辑的模型的全面概述,以及分析其优缺点的当前最先进的方法。我们讨论了与部署相关的挑战,以及这些模型如何帮助减轻幻觉和偏见,这两者都是文本生成领域的紧迫挑战。






成为VIP会员查看完整内容
相关内容
Arxiv
14+阅读 · 2021年2月14日
Arxiv
27+阅读 · 2021年1月21日
Arxiv
17+阅读 · 2020年6月2日
相关主题

相关VIP内容
相关资讯