

针对场景文本检测任务,近期基于DEtection TRansformer (DETR) 框架预测控制点的研究工作较为活跃。在基于DETR的检测器中,query的构建方式至关重要,现有方法中较为粗糙的位置先验信息构建导致了较低的训练效率以及性能。除此之外,在如何监督模型方面,之前工作中使用的点标签形式影射了人的阅读顺序,本文观察到这实际上会降低检测器的鲁棒性。
为解决以上问题,本文提出了动态点场景文本检测模型DPText-DETR。**①对于query构建方式的问题:**本文提出了一种简洁高效的显式点query构建(Explicit Point Query Modeling, EPQM) 方法,直接利用点的坐标构建显式细化的位置先验信息以加速训练收敛,并且提出了一个增强的因子化自注意(Enhanced Factorized Self-Attention, EFSA) 模块进一步挖掘同一文本实例内控制点query之间的关系。**②对于标签形式的问题:**本文设计了一种简单的位置性形式(Positional Label Form)。为进一步探究真实场景中不同标签形式对检测鲁棒性的影响,本文提出了包含500张图像的测试集Inverse-Text进行验证,其中包含约40%的类反向(inverse-like)文本实例,弥补了现有数据文本类型的缺失。实验表明,本文提出的方法显著改善了模型的收敛速度、数据效率、对旋转文本检测的鲁棒性,并在Total-Text、CTW1500、ICDAR2019 ArT三个基准数据集上分别取得了89.0%、88.8%和78.1% F-measure的最先进性能。**该工作由京东探索研究院、武汉大学、悉尼大学联合完成,已被AAAI 2023接收。**相关代码、模型和数据集均已开源,欢迎大家试用、点赞并反馈。


01 研究背景与动机
场景文本检测因其在场景理解、图片检索等应用中具有重要价值,受到了广泛的研究关注,相比于通用目标检测,场景文本的特殊性(比如多变的文字样式与任意形状)带来了别样的挑战。在计算机视觉领域,近期各种源自DETR[1]的先进检测器不断推进着目标检测的性能前沿,如何同时提升模型性能和训练收敛速度是主要的研究问题之一。其中,DAB-DETR[2]提供了影响训练收敛因素的洞见,模型输入的query可被拆解为content和positional两部分,而positional这一负责位置信息的部分对训练的收敛具有重要影响。然而,这些模型仅预测检测框,无法满足场景文本检测所需的任意形状输出要求。对此,近期的工作[3]进一步利用固定数量的控制点query表示每一文本实例,同一文本中不同控制点的positional query共享着编码器后提供的检测框位置信息,如图1所示。我们发现这种建模方式虽然提供了位置先验,但是对于预测控制点的目标来说,这种先验还不够精确,各控制点query缺少了各自独特的、显式的位置信息,并且在解码器中位置信息也难以被逐层更新,这些问题导致了**模型训练收敛相对较慢。**因此,本文对如何构建更高效的query展开了进一步的探索。

图1 先前工作中的控制点query建模方式
基于控制点拟合场景文本轮廓的方案除了带来建模方面的问题,也引入了监督层面的问题,简而言之就是控制点的顺序应该遵从什么规则,这个问题还未被探索。在之前的工作中,控制点标签的顺序在保持顺时针的同时,也受人的阅读顺序影响,如图2(a)所示,对于一个类似于反向的文本,起始边处于空间的下方。这种符合人阅读习惯的形式符合常理也很直观,然而我们观察到即使训练集中存在的类反向文本实例稀少(例如在Total-Text中约为2.8%),模型对旋转文本的检测鲁棒性也会明显下降,比如产生了具有不同起始点的假正例,如图2(b)所示。在图2(c)中,即使在训练过程中采用充分的旋转数据增强,模型仅根据视觉特征难以很好地预测符合阅读顺序的起始点,**那么在文本检测模型的训练过程中,还是否有必要让点的标签顺序与阅读顺序一致呢?**本文从监督信号这一角度,探索了不同标签形式对检测模型鲁棒性的影响。
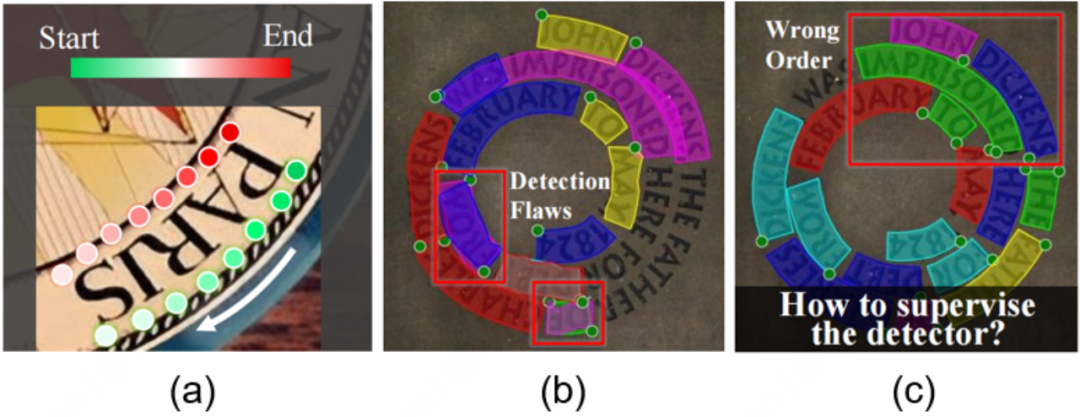
图2 (a)控制点标签顺序反映了阅读顺序。(b)检测器受到标签影响,隐式地学习阅读顺序而对同一文本产生不同起始点的预测,造成假正例等错误。绿色点为预测的起始点。(c)即使采用充分的旋转数据增强,检测模型也不能很好地学习到正确的阅读顺序。
在DETR的检测框架中,本文主要从如何更好地构建query与如何更有效地监督模型这两个互补的角度,回答了怎样迈向更好的场景文本检测这一问题。最终的模型取得了训练收敛速度、数据效率、检测鲁棒性等方面明显的提升,在仅以1 FPS的推理速度损失为代价的情况下,在三个数据集上取得了当前最佳性能。
另外,由于现有数据集中类反向文本数量稀少,为进一步探究真实场景中模型对该种文本的检测鲁棒性,本文收集并提出了包含500张图像的Inverse-Text测试集进行验证,也便于后续相关研究工作使用,其中约有40%的类反向文本实例,可用于验证模型对高度旋转与反向文本的检测以及端到端识别鲁棒性,助力检测模型与端到端识别模型取得更先进、更稳定的性能。该数据集已开始被相关研究工作所采用并作为测试基准。
02 方法概述
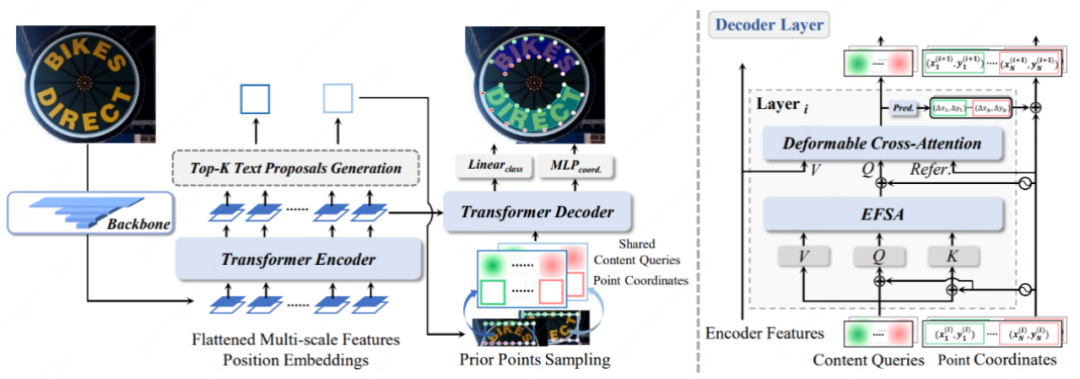
图3 DPText-DETR整体模型与解码器结构图
在DPText-DETR中,我们采用了ResNet-50与使用形变注意力[4]的Transformer编码器进行特征提取与增强,对得到的特征使用MLP头与简单的处理后,选取top-K个文本框作为positional query的生成来源。
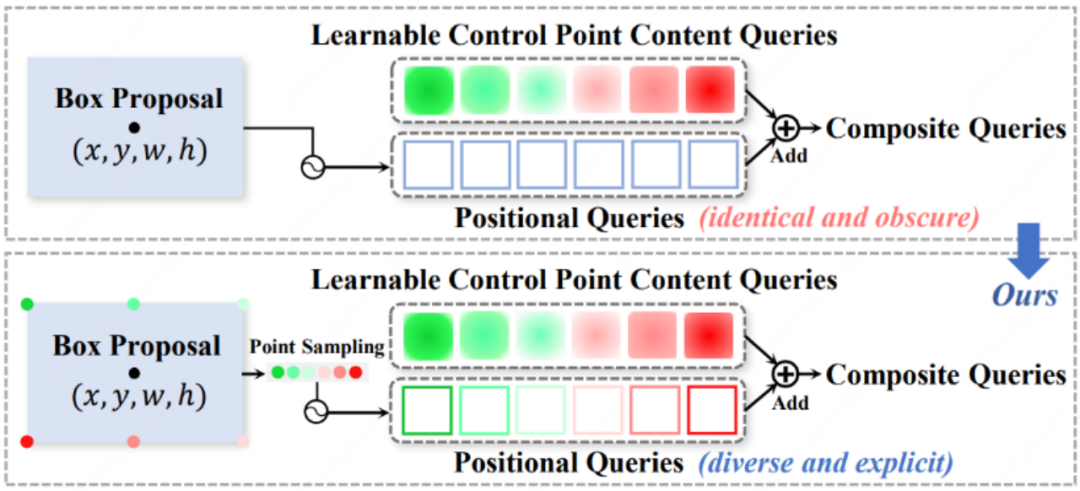
图4 query生成方式对比
在positional query生成的方式上,针对之前方法的缺陷,我们给出了简单有效的EPQM方法。具体而言,我们根据文本框中心点以及宽高的信息可以很容易地得到上下边顺时针均匀采样的多个点,由此再利用点的坐标进行位置编码与投影来生成positional query。生成方式的对比如图4所示。通过这种先验点采样(Prior Point Sampling)的方式,控制点query也就自然地转化成了彻底、显式的点形式,**同一文本实例内不同控制点的content query独享各自的显式先验位置信息,**并且在解码器层间可以便利地使用一个MLP头预测偏移量来进行点位置的更新(Point Update),以此渐进式地获得更贴合文本轮廓的控制点坐标,这些新的点坐标也将用于生成新的positional query并作为形变注意力的参考点获得更精确的图像特征。
在解码器中,有了query输入后,通常需要考虑如何挖掘query之间的关系。在之前的工作中,首先对同一实例内的不同点使用自注意机制挖掘实例内关系,其次在代表不同实例的维度上构建实例间关系。这种关系建模(称为Factorized Self-Attention, FSA)虽涵盖了实例内与实例间的关系,却缺少了对实例内不同控制点空间归纳偏置的显式建模。针对多边形的文本表示形式,可以观察到**文本的多边形控制点呈现明显的闭合环形,**因此我们引入了环形卷积[5]与实例内自注意力并行以提供显式的环形引导,引入更多的先验以充分挖掘实例内不同控制点query的关系。增强的实例内关系建模与实例间关系建模共同构成了EFSA模块。在EFSA模块后,query被送入Deformable Cross-attention模块聚合多尺度的图像特征信息。根据解码器最后一层后得到的置信度与控制点位置即可得到最终的检测结果。
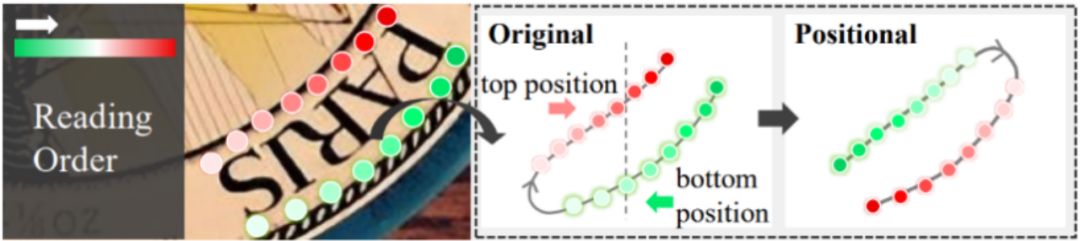
**图5 控制点标签形式示意图 **
在标签问题方面,原始的标签形式诱导检测器隐式地学习文本阅读顺序。训练过程中当文本处于各种旋转角度时,无疑给模型优化增加了额外的负担,在推理时,模型也更容易对处于较大旋转角度的文本产生不稳定的预测结果。为了缓解这一问题,我们采用了一种位置性的形式,在保证控制点按顺时针排列的同时,监督模型从单纯的空间意义上区分场景文本的顶部与底部,而不考虑文本的具体文字内容,如图5所示。更多网络结构与实现细节可参考论文原文以及代码。
03 实验结果
3.1 与SOTA方法的对比
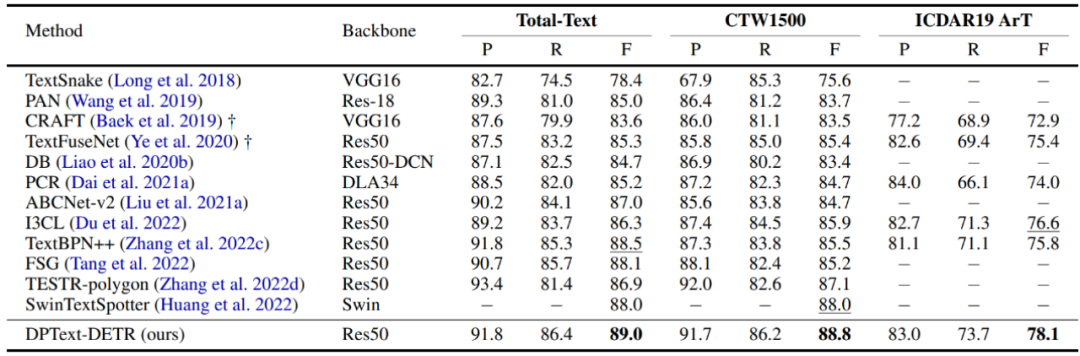
表1 与现有方法的检测性能对比
我们在Total-Text、CTW1500和ICDAR2019 ArT三个最主要的任意形状场景文本数据集上与现有方法进行比较,检测性能的对比如表1所示,其中F值是主要关注的评价指标。使用ResNet-50 backbone时,DPText-DETR在三个数据集上均取得了最佳的性能。检测结果可视化如图6所示。

图6 Total-Text(左)、CTW1500(中)与ArT(右)检测结果可视化
3.2 消融实验
本文在Total-Text、Rot.Total-Text测试集以及提出的Inverse-Text上进行了消融实验。Rot.Total-Text测试图片由Total-Text测试图片额外旋转45°、135°、180°、225°、315°得到,用于检验模型对旋转文本的鲁棒性。Inverse-Text共有500张测试图片,其中约有40%的类反向文本实例,可用于验证真实场景下对旋转文本检测以及端到端识别的鲁棒性,样例如图7所示,一些统计指标在图8中给出。在消融实验中,为了更直观地评估在Total-Text上模型训练效率的改善程度,我们只使用了Total-Text训练集进行训练,没有使用合成数据进行预训练。

图7 Rot.Total-Text与Inverse-Text测试集样例
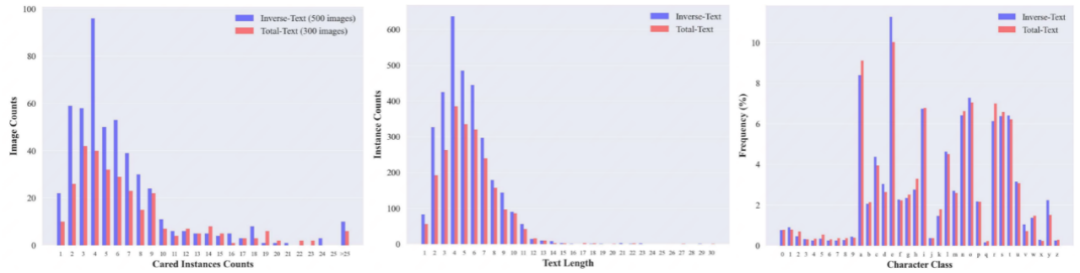
图8 Inverse-Text与Total-Text测试集在每张图片包含的文本数量、文本长度、字符类别频率等统计指标上的对比
主要的消融实验结果如表2所示。**关于位置性标签:**①将原始标签处理为位置性形式并用于训练时,测试集上的检测性能均有增益,尤其是在Rot.Total-Text以及Inverse-Text上,例如对比第1、2行结果,不使用旋转数据增强时,在Total-Text、Rot.Total-Text、Inverse-Text上分别提升了0.68%、3.90%、3.07%,这验证了即使训练数据中即使存在极少量的类反向文本,原标签形式也会较明显地降低模型检测的鲁棒性。②当使用充分的旋转数据增强时,各测试集上的性能均有显著提高,实际上旋转增强是一种廉价有效的提升模型性能及鲁棒性的手段,而在此基础上将原始标签形式替换为位置性标签,各测试集上的性能仍有明显的提升,并且如图9所示收敛的速度也得到改善,这意味着位置性形式标签有效改善了模型对阅读顺序的学习负担,降低了优化难度,相比原形式,能与旋转增强更好地协同起效。**关于EPQM与EFSA:**根据表2结果与图9收敛曲线,两个模块均对模型性能与收敛速度有明显贡献,并且推理速度的损失较为可观。其中EPQM大大加速了模型训练的收敛,可以减少所需的训练成本。除此以外,相比于原始标签形式,位置性标签为这两个模块提供了更合适的监督信号,模型因此精度更佳,模型结构方面的优化与监督信号方面的改进是展现了适宜的互补关系。
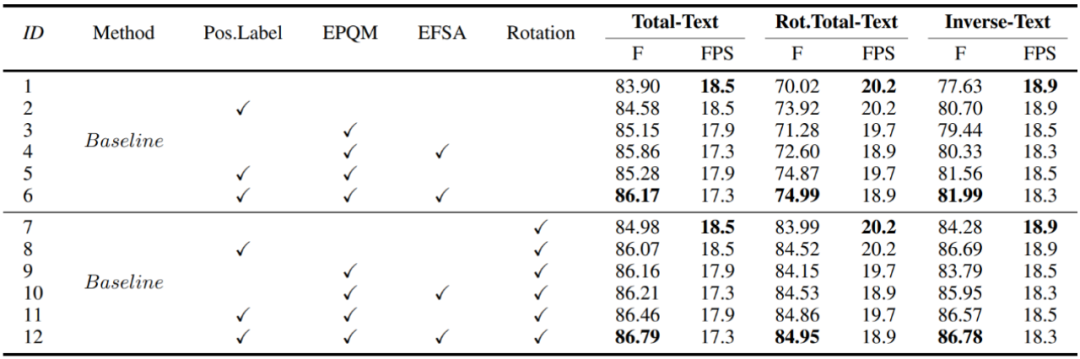
表2 消融实验。“Pos.Label”代表使用位置性标签。不使用EFSA时FSA模块将被使用
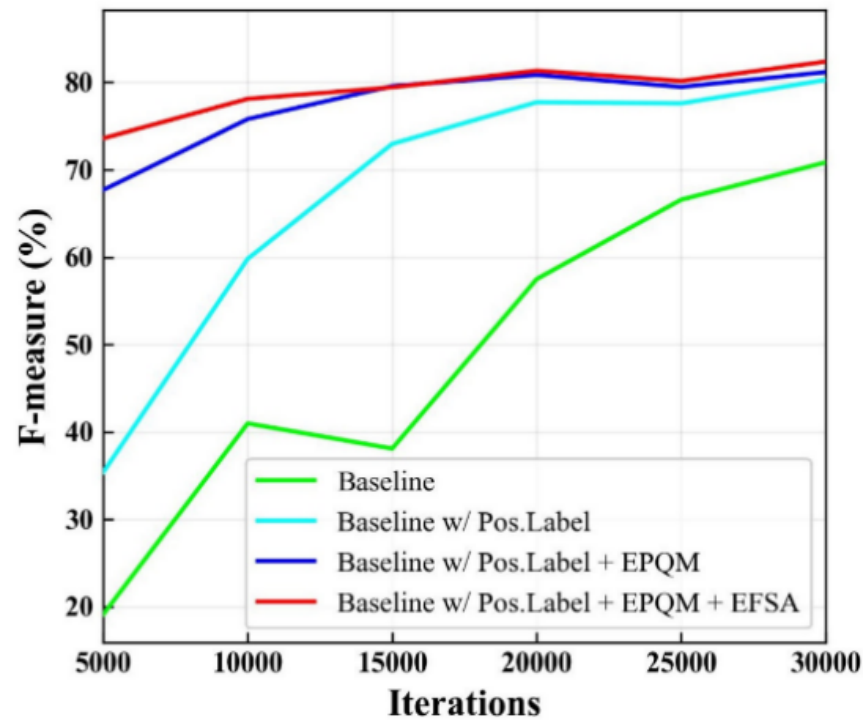
图9 使用旋转数据增强时在Rot.Total-Text上前30K迭代的收敛曲线
接下来,我们继续对EPQM和EFSA展开了减少训练步数与数据量的测试,实验结果如表3所示,训练过程中没有使用旋转数据增强。当使用全量训练数据时,将训练步数减少至原来的十分之一时,仅使用EPQM获得了9.07%的F值提升,使用EFSA有进一步改善。当减少训练数据量并保持相同训练轮数时,基线方法的检测精度断崖式下降。而使用EPQM、EFSA时受到的影响较少,相比基线最多取得了55.55%的F值提升,这表明显式的、引入更多先验的query建模方式能够极大提升训练效率。
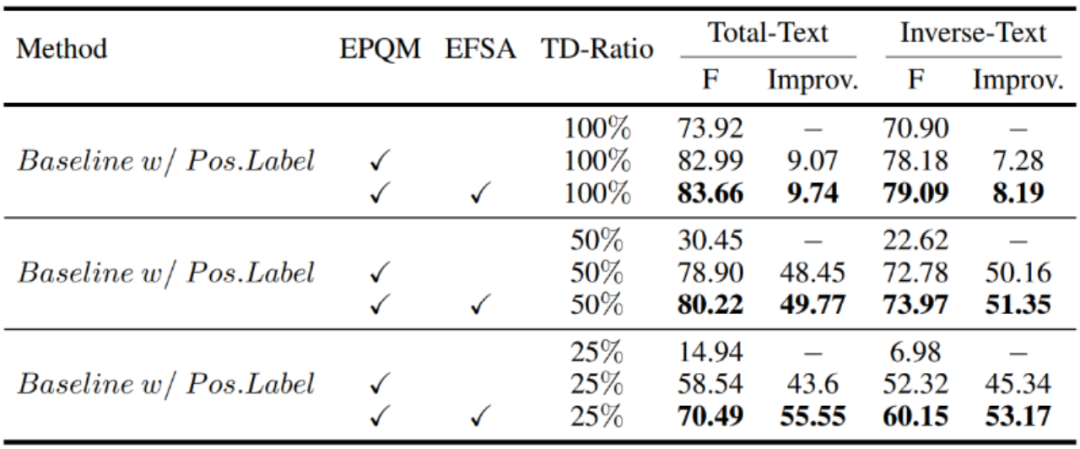
表3 使用EPQM与EFSA在更少的训练迭代次数与更少数据条件下的表现。“TD-Ratio”指训练数据使用比例,“Improv.”指检测精度的绝对提升值
为了进一步揭示EPQM中让训练收敛更快的因素,我们进行了进一步的消融,结果如图10所示。可以发现当进行点的更新时,模型的精度与收敛速度得到了更多的提升,而显式的点采样是进行点位置更新的先决条件。这表明在针对控制点query的构建过程中,对稀疏点的显式建模是提升训练效率的关键所在。之前的有关工作[2][6]表明,来自显式框的query或者进行RoIAlign的稀疏特征采样有助于提升DETR类模型的训练效率,在我们对场景文本检测设计的模型中,进一步证明由于任务与需求的差别,相比于框的信息,稀疏的显式点更能加速收敛与提升精度。

图10 对EPQM的进一步消融量化结果与收敛曲线
最后,我们也选择了一些端到端识别模型在Inverse-Text上进行测试。在预测控制点类型的模型上测试位置性标签后,检测F值仍有明显的提升。另外,相比于这些模型在Total-Text上的性能表现,这些模型在Inverse-Text上直接测试能达到相似的检测精度,但是端到端识别精度显著更低,这也说明端到端识别模型对于高度旋转以及反向文本的识别鲁棒性仍有较大的提升空间,Inverse-Text可以作为测试集,便于后续有关工作评估真实场景中模型对旋转文本的识别鲁棒性。
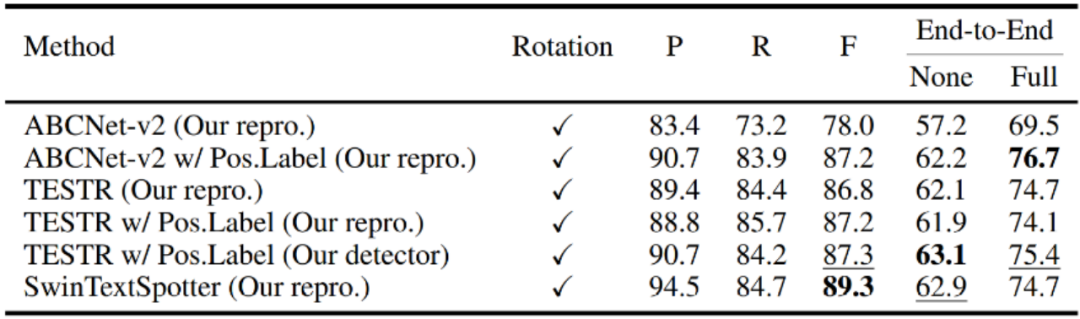
表4 现有端到端识别模型在Inverse-Text上的测试精度

图11 端到端识别模型对Inverse-Text中高度旋转以及类反向文本的识别效果较差。红框标出了识别错例
04 结论
我们基于DETR框架提出了一种简洁有效的场景文本检测模型DPText-DETR,将query重构为完全显式的点形式,显著地提升了训练收敛速度与数据效率,并探究了控制点标签形式对检测鲁棒性的影响,实验表明DPText-DETR在三个最主要的任意形状场景文本数据集上取得了SOTA性能。另外,我们也提出了Inverse-Text测试集以便后续相关工作使用。
【论文】https://arxiv.org/abs/2207.04491
【代码】https://github.com/ymy-k/DPText-DETR
