

提示 (Prompting) 已成为将大型语言模型(LLMs)适配到特定自然语言处理任务的主流范式。尽管这种方法为LLMs的上下文学习开启了大门,但它带来了模型推理的额外计算负担和人力努力的手工设计提示,特别是在使用冗长和复杂的提示来指导和控制LLMs行为时。结果,LLM领域见证了高效提示方法的显著增长。在本文中,我们提供了这些方法的全面综述。从高层次来看,高效提示方法大致可以分为两种途径:具有高效计算的提示和具有高效设计的提示。前者涉及各种压缩提示的方式,后者采用自动提示优化的技术。我们介绍了提示的基本概念,回顾了高效提示的进展,并突出了未来研究方向。
大型语言模型(LLMs)已显著推进了各种自然语言处理(NLP)任务的最新进展,例如对话、机器翻译和摘要生成(Brown et al., 2020; Touvron et al., 2023; Bubeck et al., 2023)。提示是人机交互的一个重要媒介,用于向LLMs明确传达清晰的任务描述,然后通过类比学习生成用户期望的响应。提示的内容在不同上下文中会有所变化,特别是包含指令、问题、带有特定输出格式的多重演示,以及额外要求,如复杂的推理过程和角色扮演命令。在本文中,“提示”一词指的是用户输入给LLMs的内容。
然而,随着LLMs的上下文学习(ICL)能力变得更强(Dong et al., 2022),为不同特定任务设计的提示倾向于多样化和详细化。超长的自然语言提示逐渐引发了两个问题:1) 对LLM本身而言,上下文窗口是有限的,影响其处理过度冗长上下文的潜力;2) 对LLM用户而言,它要求使用大量的计算资源来训练开源模型,或者承担调用闭源模型接口的高成本。从这个角度来看,LLM的使用成本在学术研究和商业部署场景中都相当巨大。显然,性能出色的LLM不能被广泛使用是一种遗憾。虽然模型结构有许多相关改进,如高效注意力机制(参见Xiao & Zhu, 2023; Wan et al., 2023的相关工作),可以有效减轻推理成本,在本文中,我们更侧重于高效提示方法,以节省不必要的财务开销。
考虑到财务和人力资源,效率可以从三个角度得到改善:1) 推理加速,2) 内存消耗下降,和3) 自动设计良好的提示。前两个目标可以通过提示压缩实现,而第三个目标可以基于提示工程而非手工设计,通过自动提示优化实现。据我们所知,文献中关于高效提示方法的全面整合存在显著差距。
在这篇综述中,我们从第2节的提示背景介绍开始。随后,我们从计算(第3节)和设计(第4节)的角度审查现有的高效提示方法。前者将提示压缩组织为三个类别:知识蒸馏(第3.1节)、编码(第3.2节)和过滤(第3.3节)。后者探讨基于传统梯度下降(第4.1节)和智能进化算法(第4.2节)的自动提示优化。特别地,我们将高效提示抽象为一个多目标优化问题,并从理论角度展望未来方向(第5节)。最后,我们在第6节总结了全文。此外,我们还包括了一个方便参考的开源项目列表A.2和高效提示方法的类型图A.3。
总述
**提示范式 **
提示的出现与预训练语言模型(PLMs)的演进和大型语言模型(LLMs)的进步密切相关。PLM演进 PLM范式的演化轨迹已从有效性转向效率。自从Transformer(Vaswani et al., 2017)被提出以来,它已成为广泛PLMs的基础架构。Transformer内部的自监督学习机制已被证明在解决长序列问题上有效。为分别解决基本的自然语言理解(NLU)和自然语言生成(NLG)任务,主流PLMs逐渐演化成BERT(Devlin et al., 2019)和GPT(Radford et al., 2018)系列模型。有许多优化策略,如探索编码方法(Su et al., 2021)、改进自监督学习机制(Roy et al., 2021)和精炼模型结构(Li et al., 2021),以实现PLMs在解决特定任务上的高效表现。NLP范式转变 NLP训练范式经历了两次关键转变(Liu et al., 2023b),从“完全监督学习”演化为“预训练与微调”,最终演化为“预训练、提示和预测”(如图1所示)。在这篇综述中,我们将专注于目前最广泛采用的提示范式,深入探讨其最近的发展。值得注意的是,GPT-3(Brown et al., 2020)在引入硬提示方面发挥了开创性作用,使人类能够使用自然语言与语言模型交互。这一突破得益于大规模参数,它使GPT-3具备了深入理解自然语言的能力,从而允许它利用复杂的硬提示进行少量样本学习,无需微调。LLM进展 在GPT-3开创LLM时代之后,ChatGPT作为塑造当前主流范式“LLM + 提示”的重要里程碑而脱颖而出。其NLU和NLG能力的完美整合吸引了整个人工智能社区的关注。随着规模法则(Wei et al., 2022a)展示了显著的新兴能力(例如,指令跟随、上下文学习和复杂推理),研究人员持续探索提示的性能边界,无论是开源还是闭源的LLMs。例如,像思维链(CoT)(Wei et al., 2022b)这样的复杂提示通过大声思考,增强了LLMs的潜在推理能力。随着提示范式逐渐稳固其地位,LLM仍然面临着由于其大规模参数而导致的计算和人力资源挑战。因此,有效的提示方法以节约资源引起了广泛兴趣。
提示类型
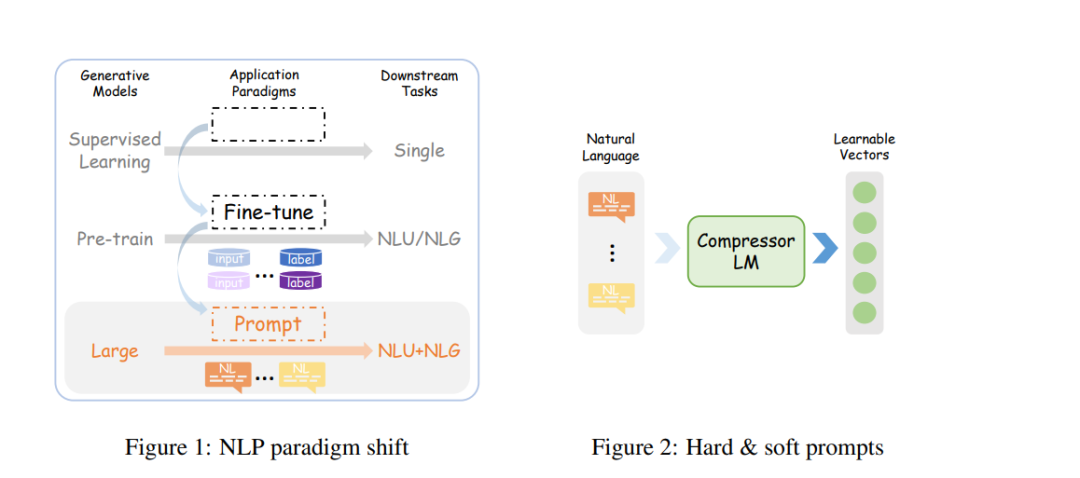
本质上,提示的主要目标是实现有效的少量样本学习,而不是不必要的全参数微调所消耗的资源。提示表达可以分为两种主要类型,如图2所示:离散的自然语言提示(称为硬提示)和连续的可学习向量(称为软提示)。2.2.1 硬提示 硬提示特别适用于生成性语言模型,尤其是GPT系列模型的一个显著例子。关注硬提示的原因有两个方面。从积极的角度来看,由于大量的预训练数据集成到LLMs中,人类可以通过母语轻松地与世界知识压缩器(即LLM)交互,最终获得有用的响应。从消极的角度来看,由于当前LLMs广泛采用闭源性质,使得其参数权重不可访问,用户别无选择,只能通过API调用与LLMs使用硬提示。尽管如此,LLM强大的指令跟随能力为硬提示的发展奠定了坚实的基础,而自然语言作为无缝人机交互的媒介指日可待。重要的是要强调硬提示之间的多样性。最初,硬提示包括类似于Cloze任务设计的简洁任务指令。然而,随着LLMs的理解能力不断提高,硬提示已演化为包含更广泛元素的数组,最常见的包括演示和思维链,如图3所示。当前NLP社区对硬提示的日益兴趣,甚至是解锁LLMs全部潜力的教程,表明了对人模型对齐导致人工通用智能(AGI)的渴望。2.2.2 软提示 在提示相关研究的早期阶段,软提示以适配器(Houlsby et al., 2019)、前缀(Li & Liang, 2021)甚至是无法解释的向量的形式出现。许多研究(Lester et al., 2021; Liu et al., 2022)探讨了软提示在通过探索不同嵌入位置来增强高效训练的好处。标准方法涉及冻结原始模型参数,仅训练软提示以实现完整参数微调的效果。Ding et al.(2022)的工作中有更详细的介绍。鉴于可学习向量可以与神经网络参数一起更新,软提示显然更有利于LLMs有效理解提示。需要注意的是,本文讨论的软提示仅仅是LLMs的硬提示的向量表示,如图2所示,而不是从零开始开发的抽象向量。一些努力涉及将较长的硬提示压缩成显著更短的软提示(参见第3.1节和第3.2节以获取详细见解)。
挑战
鉴于硬提示已被广泛认可并应用于各种下游任务。设计的提示更加详细以提高任务准确性,因此导致更长且更复杂的提示。在这篇综述中,我们从效率的角度提出了硬提示面临的两个关键挑战:长度问题 提示的长度通常取决于特定任务,演示越多,性能越好。例如,思维链(CoT)提示显著增强了LLMs的逻辑推理能力,导致出现了各种基于CoT的方法。像Self-Ask(Press et al., 2022)和最少到最多提示(Zhou et al., 2022a)帮助LLMs将复杂问题分解为更简单的子问题以进行逐步回答。Wang et al.(2022)采样了多样化的推理路径,而Wang et al.(2023b)指导LLMs生成正确的PS(计划和解决方案),然后选择最终答案。然而,使用这种复杂提示的优势伴随着更高的财务负担,以及LLMs的信息感知能力降低。难以设计的提示 由于自然语言的离散性质,早期可用的硬提示通常是手工设计的,然后通过反复试错获得。手工制作的提示模板严重依赖于经验知识,并涉及明显的人为主观性。但是,人类解决问题的方法与神经网络之间存在差异,换句话说,LLMs的可解释性仍然是持续探索的话题,目前尚无公认的理论指导。因此,针对LLMs的提示设计面临许多挑战,包括LLMs对自然语言提示格式的高敏感性、语义相似提示的大性能差距、提示复杂性与任务难度之间的关联,以及提示的模型和任务特定属性。因此,面对不同模型和不同任务,手动设计高质量提示既耗时又费力。总之,提示有效地缓解了应用于下游任务时的参数冗余问题,从而节省了财务资源。然而,在LLMs时代,提示长度的增加带来了更大的内存需求、更慢的推理速度和更高的劳动强度等挑战,这偏离了提示的原始目的。因此,这篇综述深入探讨了当前在LLMs中使用的高效提示方法。
使用高效计算的提示
随着大型语言模型(LLMs)规模的不断扩大,“使用高效计算的提示”概念应运而生,旨在减轻长提示对开源和闭源LLMs带来的经济负担。已观察到,压缩的提示可以被LLMs有效重构,并减少生成文本的长度(Jiang et al., 2023a)。在本节中,我们提供了与提示压缩相关研究的见解,将其分类为文本到向量级别和文本到文本级别的方法。提示压缩的主要目的是从原始提示中提取必要信息,以便LLMs能够保持与原始提示相当的性能水平。
使用高效设计的提示
“使用高效设计的提示”概念是为了应对提示内容的日益复杂性而引入的。随着耗时且劳力密集的手工设计提示方法逐渐退出历史舞台,以及梯度基础的提示微调方法不再适用于闭源LLMs,基于提示工程(PE)的自动优化逐渐成为焦点。具体来说,本文提出的“离散”提示优化涉及在给定的搜索空间内找到最佳的“自然语言”提示,以最大化任务准确性。基于LLMs的强大通用能力,自动提示优化显示出了有希望的进展,其工作流程大致如图4所示。我们将从传统数学优化和智能算法优化的视角深入探讨这个问题,因此将本节分为基于梯度的方法和基于进化的方法。
结论
在这项工作中,我们总结了用于LLMs的高效提示方法,目的是提高LLM的效率和性能。我们回顾了具有高度认可的现有相关工作,揭示了各类别内部的固有联系,并从理论角度深度抽象这些方法。最后,我们为LLM实践者提供了一个开源项目清单A.2,以便在科学研究和商业部署中快速参考,以及一个类型学图A.3,以概览高效提示领域。
