
主动学习试图在具有尽可能少标注样本的同时最大化模型的性能增益。深度学习(Deep learning, DL)需要大量标注数据,如果模型要学习如何提取高质量的特征,就需要大量的数据供应来优化大量的参数。近年来,由于互联网技术的飞速发展,我们进入了一个以海量可用数据为特征的信息丰富性时代。因此,DL得到了研究者的极大关注,并得到了迅速的发展。但与DL相比,研究者对AL的兴趣相对较低,这主要是因为在DL兴起之前,传统机器学习需要的标记样本相对较少,这意味着早期的AL很少被赋予应有的价值。虽然DL在各个领域都取得了突破,但大部分的成功都要归功于大量公开的带标注的数据集。然而,获取大量高质量的带注释数据集需要耗费大量人力,在需要较高专业知识水平的领域(如语音识别、信息提取、医学图像等)是不可行的,因此AL逐渐得到了它应该得到的重视。
因此,研究是否可以使用AL来降低数据标注的成本,同时保留DL强大的学习能力是很自然的。由于这些调研的结果,深度主动学习(DAL)出现了。虽然对这一课题的研究相当丰富,但至今还没有对相关著作进行全面的调研; 因此,本文旨在填补这一空白。我们为现有的工作提供了一个正式的分类方法,以及一个全面和系统的概述。此外,我们还从应用的角度对DAL的发展进行了分析和总结。最后,我们讨论了与DAL相关的问题,并提出了一些可能的发展方向。
概述:
深度学习(DL)和主动学习(AL)在机器学习领域都有重要的应用。由于其优良的特性,近年来引起了广泛的研究兴趣。更具体地说,DL在各种具有挑战性的任务上取得了前所未有的突破;然而,这很大程度上是由于大量标签数据集的发表[16,87]。因此,在一些需要丰富知识的专业领域,样品标注成本高限制了DL的发展。相比之下,一种有效的AL算法在理论上可以实现标注效率的指数加速。这将极大地节省数据标注成本。然而,经典的AL算法也难以处理高维数据[160]。因此,DL和AL的结合被称为DAL,有望取得更好的效果。DAL被广泛应用于多个领域,包括图像识别[35,47,53,68],文本分类[145,180,185],视觉答题[98],目标检测[3,39,121]等。虽然已经发表了丰富的相关工作,DAL仍然缺乏一个统一的分类框架。为了填补这一空白,在本文中,我们将全面概述现有的DAL相关工作,以及一种正式的分类方法。下面我们将简要回顾DL和AL在各自领域的发展现状。随后,在第二节中,进一步阐述了DL与AL结合的必要性和挑战。
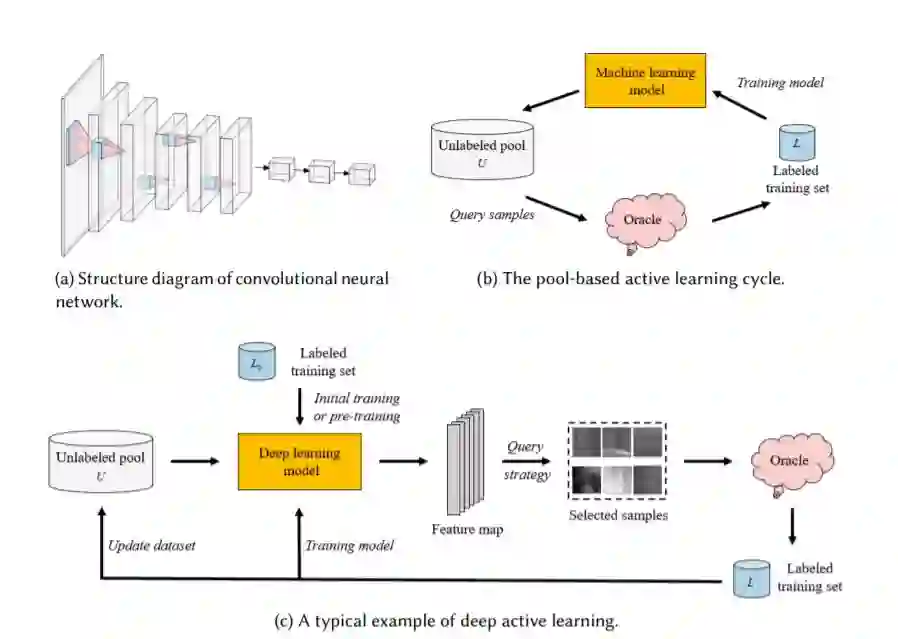
图1所示。DL、AL和DAL的典型体系结构比较。(a)一种常见的DL模型:卷积神经网络。(b) 基于池化的AL框架: 使用查询策略查询未标记的样本池U和将其交给oracle进行标注,然后将查询样本添加到标记的训练数据集L,然后使用新学到的知识查询的下一轮。重复此过程,直到标签预算耗尽或达到预定义的终止条件。(c) DAL的一个典型例子:在标签训练集L0上初始化或预训练DL模型的参数的常变量,利用未标记池U的样本通过DL模型提取特征。然后根据相应的查询策略选择样本,在查询时对标签进行查询,形成新的标签训练集L,然后在L上训练DL模型,同时更新U。重复此过程,直到标签预算耗尽或达到预定义的终止条件。
DAL结合了DL和AL的共同优势:它不仅继承了DL处理高维图像数据和自动提取特征的能力,也继承了AL有效降低标注成本的潜力。因此,DAL具有令人着迷的潜力,特别是在标签需要高水平的专业知识和难以获得的领域。

