自监督学习时间序列分析最新综述

自监督学习(SSL)最近在各种时间序列任务上取得了令人印象深刻的表现。SSL最显著的优点是它减少了对标签数据的依赖。基于预训练和微调策略,即使只有少量的标签数据也可以取得高性能。与许多已发表的关于计算机视觉和自然语言处理的自监督综述相比,关于时间序列SSL的全面综述仍然缺失。为了填补这个空白,我们在这篇文章中回顾了当前针对时间序列数据的最先进的SSL方法。为此,我们首先全面回顾了与SSL和时间序列相关的现有综述,然后提供了一个新的时间序列SSL方法的分类。我们将这些方法归纳为三类:基于生成的,基于对比的和基于对抗的。所有的方法都可以进一步分为十个子类别。为了便于时间序列SSL方法的实验和验证,我们还总结了通常用于时间序列预测、分类、异常检测和聚类任务的数据集。最后,我们展示了时间序列分析的SSL的未来方向。
https://www.zhuanzhi.ai/paper/1340fc4294f6b0fdb60413f4ed9debd9
1.导论
时间序列数据在许多现实世界的场景中非常丰富 [1], [2],包括人类活动识别 [3],工业故障诊断 [4],智能建筑管理 [5] 和医疗保健 [6]。基于时间序列分析的大多数任务的关键是提取有用且信息丰富的特征。近年来,深度学习(DL)在提取数据的隐藏模式和特征方面表现出了令人印象深刻的性能。通常,拥有足够大的标记数据是可靠的基于DL的特征提取模型的关键因素之一,通常被称为监督学习。不幸的是,在某些实际场景中,这一要求很难达到,特别是对于时间序列数据,获得标记数据是一个耗时的过程。作为一种替代方案,自监督学习(SSL)因其标签效率和泛化能力而受到越来越多的关注,因此,许多最新的时间序列建模方法已经遵循了这种学习范式。
自监督学习(SSL)是无监督学习的一个子集,它利用任务任务来从未标记的数据中获取监督信号。这些任务任务是模型为了从数据中学习而解决的自生成的挑战,从而为下游任务创建有价值的表示。SSL不需要额外的手动标记数据,因为监督信号来自数据本身。在精心设计的任务任务的帮助下,SSL最近在计算机视觉(CV)[7]-[10]和自然语言处理(NLP)[11], [12]领域取得了巨大成功。随着SSL在CV和NLP中的巨大成功,将SSL扩展到时间序列数据变得很吸引人。然而,将为CV/NLP设计的任务任务直接转移到时间序列数据并非琐事,并且在许多场景中常常行不通。在这里,我们强调在将SSL应用于时间序列数据时出现的一些典型挑战。首先,时间序列数据表现出独特的属性,如季节性、趋势和频域信息 [13]-[15]。由于大多数为图像或语言数据设计的任务任务没有考虑与时间序列数据相关的语义,因此不能直接采用。其次,SSL中常用的一些技术,如数据增强,需要为时间序列数据专门设计。例如,旋转和裁剪是图像数据的常用增强技术 [16]。然而,这两种技术可能会破坏序列数据的时间依赖性。第三,大多数时间序列数据包含多个维度,即多变量时间序列。然而,有用的信息通常只存在于少数维度中,这使得使用针对其他数据类型的SSL方法在时间序列中提取有用信息变得困难。
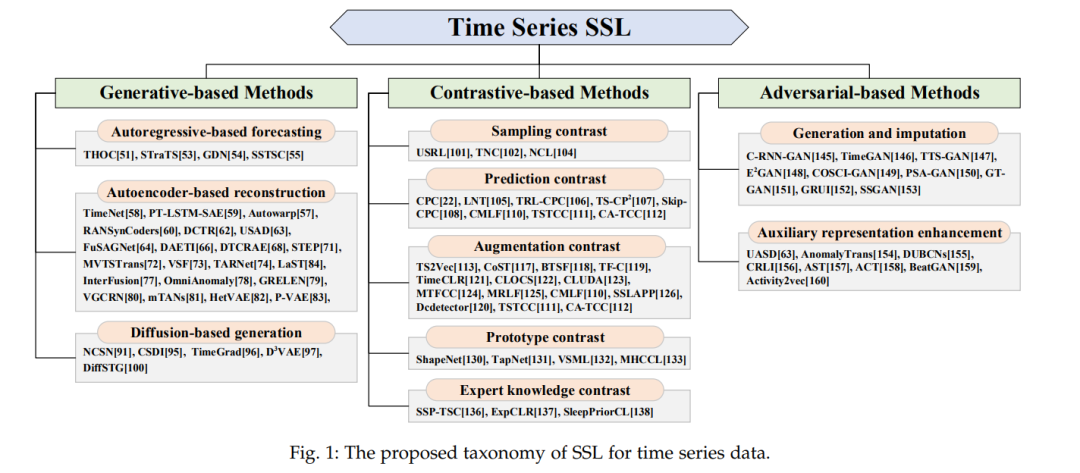
据我们所知,尚未有针对时间序列数据的自监督学习(SSL)的全面和系统的回顾,这与关于CV或NLP的SSL的丰富文献形成鲜明对比 [17], [18]。Eldele等人[19]和Deldari等人[20]提出的调查与我们的工作在某种程度上相似。然而,这两篇综述仅讨论了自监督对比学习(SSCL)的一小部分,这需要更全面的文献回顾。此外,还需要包括基准时间序列数据集的总结,而时间序列SSL的潜在研究方向也非常稀少。本文回顾了当前针对时间序列数据的最先进的SSL方法。我们首先总结了关于SSL和时间序列数据的最近综述,然后从三个角度提出了一种新的分类法:基于生成的,基于对比的和基于对抗的。这个分类法与刘等人[21]提出的类似,但专注于时间序列数据。对于基于生成的方法,我们描述了三个框架:基于自回归的预测,基于自编码器的重构和基于扩散的生成。对于基于对比的方法,我们根据正样本和负样本的生成方式,将现有的工作划分为五个类别,包括采样对比,预测对比,增强对比,原型对比和专家知识对比。对于每一个类别,我们分析其见解和局限性。然后我们整理和总结了基于两个目标任务的基于对抗的方法:时间序列生成/插补和辅助表示增强。所提出的分类法显示在图1中。我们通过讨论时间序列SSL的可能未来方向来结束这项工作,包括数据增强的选择和组合,SSCL中正样本和负样本的选择,时间序列SSL的归纳偏见,SSCL的理论分析,时间序列的对抗攻击和鲁棒分析,时间序列领域适应,时间序列的预训练和大型模型,时间序列SSL在协作系统中的应用,以及时间序列SSL的基准评估。
我们的主要贡献可以总结如下: • 新的分类法和全面回顾。我们提供了一个新的分类法和一个详细且最新的时间序列SSL的回顾。我们将现有方法分为十个类别,对于每个类别,我们描述了基本框架、数学表达式、细粒度分类和详细比较。据我们所知,这是第一项全面和系统地回顾时间序列数据的SSL现有研究的工作。 • 应用和数据集的收集。我们收集了有关时间序列SSL的资源,包括应用和数据集,并研究了相关数据来源、特征和相应的工作。 • 丰富的未来方向。我们从应用和方法论的角度指出了这个领域的一些关键问题,分析了它们的原因和可能的解决方案,并讨论了时间序列SSL的未来研究方向。我们坚信,我们的努力将激发对时间序列SSL的进一步研究兴趣。
本文的其余部分组织如下。第2节提供了有关SSL和时间序列数据的一些文献回顾。第3节到第5节分别描述了基于生成的方法、基于对比的方法和基于对抗的方法。第6节从应用的角度列出了一些常用的时间序列数据集。第7节讨论了时间序列SSL的几个有前景的方向,而第8节总结了本文。
2. 自监督学习

这个类别关注模型架构和训练目标。SSL方法大致可以分为以下几类:基于生成的方法、基于对比的方法和基于对抗的方法。这些类别的模型架构如图2所示,可以总结为:
• 基于生成的方法首先使用编码器将输入x映射到表示z,然后使用解码器从z重构x。训练目标是最小化输入x和重构输入xˆ之间的重构误差。 • 基于对比的方法是最广泛使用的SSL策略之一,通过数据增强或上下文采样构建正样本和负样本。然后通过最大化两个正样本之间的互信息(MI)来训练模型。基于对比的方法通常使用对比相似度度量,如InfoNCE损失[22]。 • 基于对抗的方法通常包括生成器和判别器。生成器生成假样本,判别器用于区分它们和真实样本。 使用学习范式作为分类法可以说是现有SSL调查中最受欢迎的,包括[20],[23]-[28]。然而,并非所有的调查都涵盖了上述三个类别。更多细节请参考这些调查。在表1中,我们还提供了每项调查涉及的数据模态,这可以帮助读者快速找到与他们密切相关的研究工作。
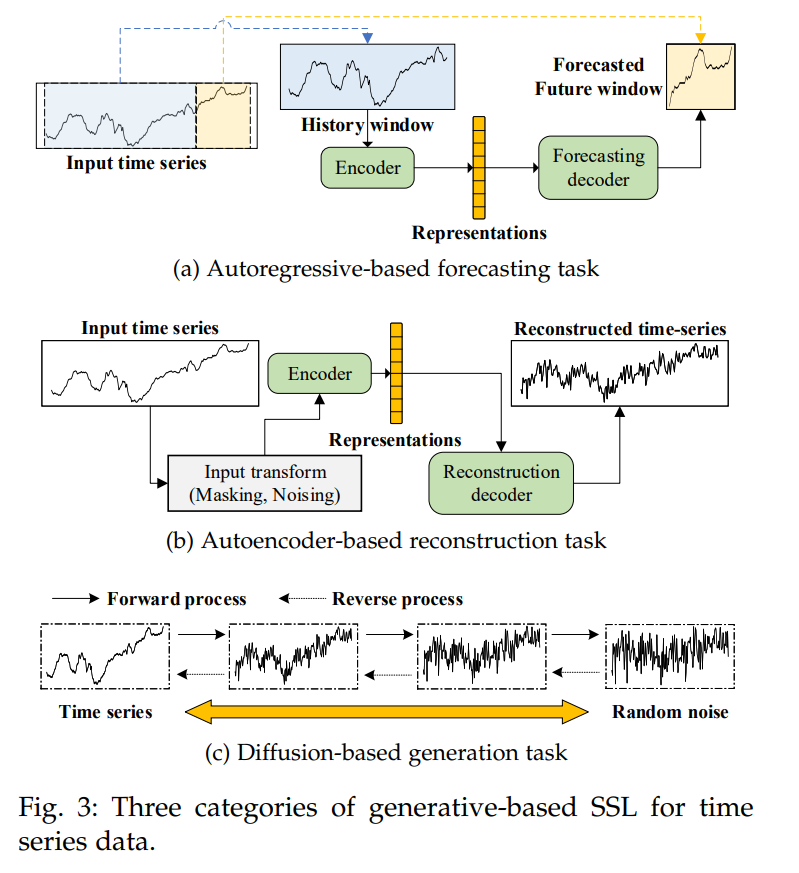
3. 基于生成的方法:在这个类别中,预文本任务是基于给定的数据视图生成预期的数据。在时间序列建模的背景下,常用的预文本任务包括使用过去的系列来预测未来的时间窗口或特定的时间戳,使用编码器和解码器重构输入,以及预测被遮盖的时间序列的未见部分。本节从自回归预测、基于自编码器的重构和基于扩散的生成的角度整理了时间序列建模中现有的自监督表示学习方法。值得注意的是,基于自编码器的重构任务也被视为一种无监督框架。在自监督学习(SSL)的背景下,我们主要使用重构任务作为预文本任务,最终目标是通过自编码器模型获得表示。
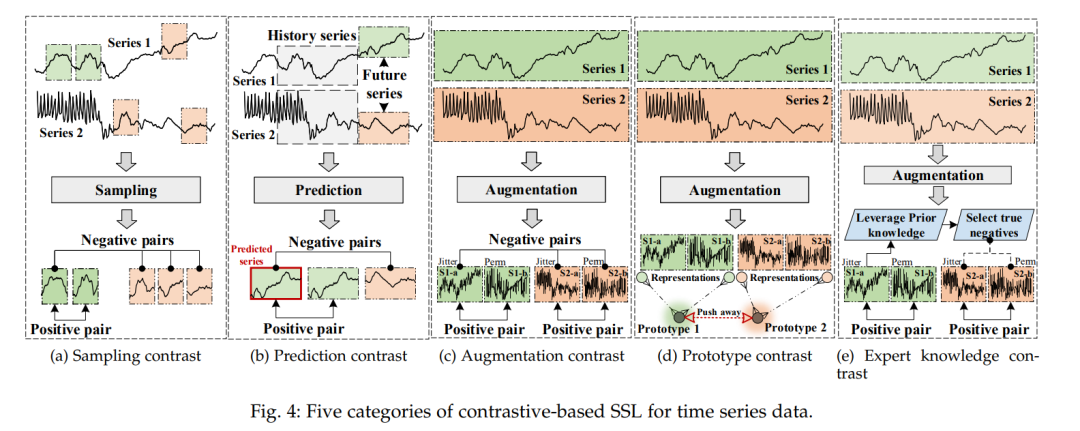
4. 基于对比的方法:对比学习是一种广泛使用的自监督学习策略,在计算机视觉和自然语言处理中表现出强大的学习能力。与学习将数据映射到真实标签的判别模型和试图重构输入的生成模型不同,基于对比的方法旨在通过在正样本和负样本之间进行对比来学习数据表示。具体而言,正样本应具有相似的表示,而负样本应具有不同的表示。因此,正样本和负样本的选择对基于对比的方法非常重要。本节根据正样本和负样本的选择对时间序列建模中现有的基于对比的方法进行整理和总结。
5 基于对抗的方法:基于对抗的自监督表示学习方法利用生成对抗网络(GANs)来构建预文本任务。GAN包含一个生成器G和一个判别器D。生成器G负责生成类似于真实数据的合成数据,而判别器D负责判断生成的数据是真实数据还是合成数据。因此,生成器的目标是最大化判别器的判断失败率,而判别器的目标是最小化其失败率[48],[139]。生成器G和判别器D是相互博弈的关系,因此学习目标是:
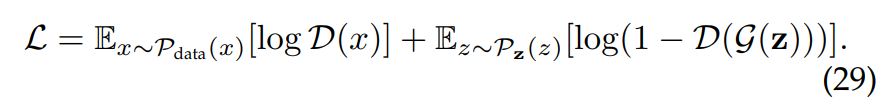
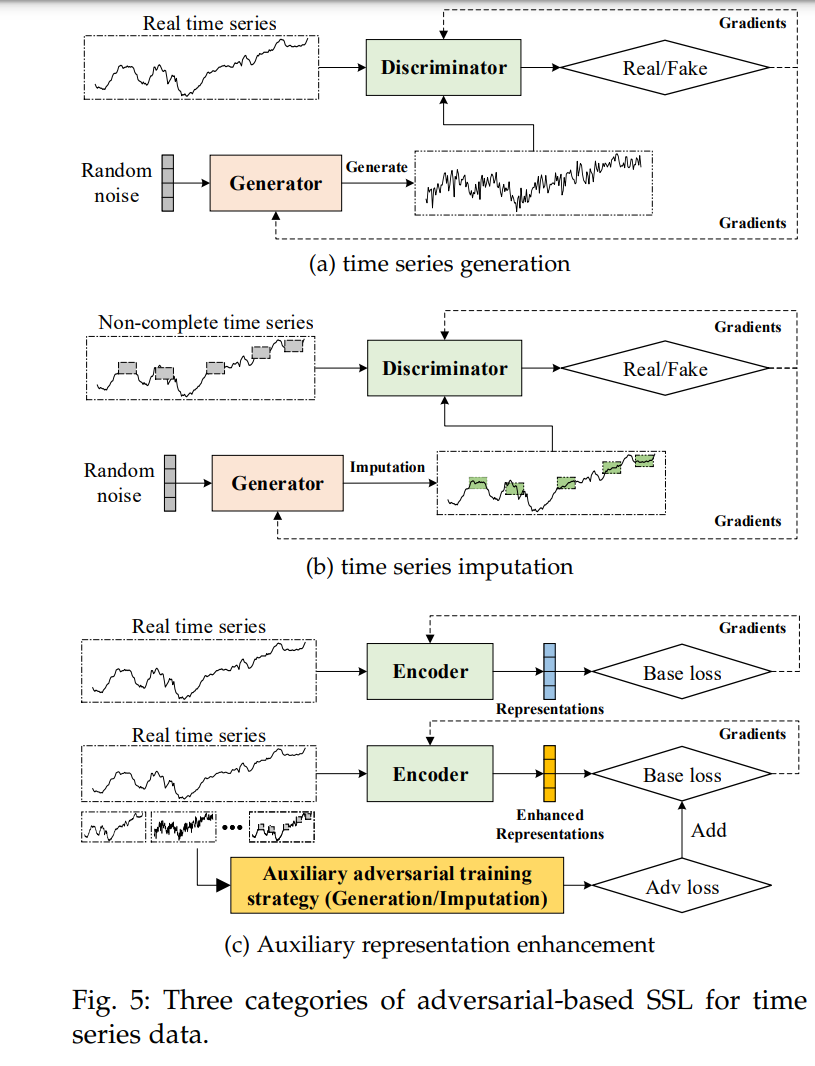
根据最终任务,现有的基于对抗的表示学习方法可以分为时间序列生成与填充,以及辅助表示增强。这些基于对抗的自监督学习(SSL)的示例显示在图5中。
6 应用与数据集:自监督学习(SSL)在不同的时间序列任务中有很多应用,如预测、分类、异常检测等。我们根据应用领域总结了最常用的数据集和代表性的参考文献。在本文中,我们收集了四个任务中广泛使用的数据集:异常检测、预测、分类和聚类。如表2所示,我们提供了有用的信息,包括数据集名称、维度、大小、来源、引用和有用的注释。分类任务和聚类任务的数据集一起列出,因为这两个任务的目标是一致的。

7 结论:本文集中讨论时间序列自监督学习(SSL)方法,并提供了一个新的分类法。我们根据学习范式将现有方法分为三大类:基于生成的、基于对比的和基于对抗的。此外,我们将所有方法整理成十个详细的子类别:基于自回归的预测、基于自编码器的重构、基于扩散的生成、采样对比、预测对比、增强对比、原型对比、专家知识对比、生成和填充,以及辅助表示增强。我们还提供了关于应用和广泛使用的时间序列数据集的有用信息。最后,总结了多个未来的发展方向。我们相信,这篇综述填补了时间序列SSL的空白,并激发了对时间序列数据的SSL的进一步研究兴趣。