
可供性检测是指识别图像中物体的潜在动作可能性,是智能体感知和操纵的重要能力。为了在未知场景中赋予智能体这种能力,研究员们考虑了具有挑战性的单样本可供性检测问题,即,给定描述动作目的的支持图像,应检测出场景中具有共同可供性的所有对象(如图3.1所示)。
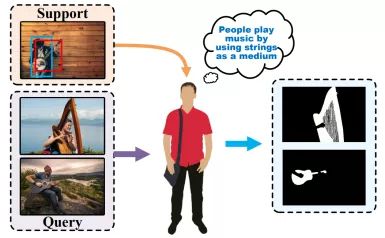
图3.1 单样本可供性检测的流程图
与对象检测/分割问题不同,对象的可供性和语义类别高度相关,但并不相互暗示。一个对象可能有多种可供性(见图 3.2),例如,沙发可用于坐下或躺下。实际上,可能的可供性取决于人在实际应用场景中的目的。在没有目的的指导下直接从单个图像中学习可供性使模型倾向于关注统计上占主导地位的可供性,而忽略可能适合完成任务的其他可供性。
为了解决这个问题:1)研究员们试图从单个支持图像中找到关于动作目的的明确提示(即通过主体和客体的位置信息),它隐含地定义了对象可供性,并且这是未知场景中的合理设置。2)研究员们采用协作学习来捕捉不同对象之间的内在关系,以抵消视觉外观差异带来的干扰,提高泛化能力。具体来说,研究员们设计了一种新颖的 One-Shot Affordance Detection (OS-AD) 网络来解决这个问题(如图3.3所示)。以一张图像作为支持,一组图像(本文中为 5 张图像)作为查询。
网络首先使用意图学习模块(PLM)从支持图像中捕获人与对象的交互,以对动作意图进行编码。然后,设计了一个意图转移模块 (PTM) 以使用动作目的的编码来激活查询图像中具有共同可供性的特征。最后,设计了一个协作增强模块(CEM)来捕捉具有相同可供性的对象之间的内在关系,并抑制与动作意图无关的背景。通过这种方式,OS-AD网络可以学习到良好的适应能力来感知未知场景中的物体可供性。
此外,由于物体可供性多样性的限制,现有数据集相对于实际应用场景仍然存在差距。 为了解决数据集的局限性,研究员们收集并提出了PAD可供性数据集,其中包含 4,002 张不同的图像,涵盖 31 个可供性类别以及来自不同场景的 72 个对象类别。
最后,研究员们对提议的 PAD 基准进行的实验表明,OS-AD网络优于包含3种类型(分割模型,显著性检测模型和协同显著性模型)的6个SOTA模型(UNet, PSPNet, CPD, BASNet, CSNet 和 CoEGNet),可以作为未来研究的强大基线。