从零到一:带你认识深度学习!

作者:Zied Haj-Yahia
翻译:张玲
校对:丁楠雅
本文约2500字,建议阅读15分钟。
本文为你简要介绍深度学习的基本构成、模型优化的几种方式和模型训练的一些最佳实践。
一年多来,我在LinkedIn、Medium和Arxiv上阅读了不少深度学习相关文章和研究论文。当我几周之前开始麻省理工学院6.S191深度学习在线课程(这里是课程网站的链接)以后,我决定写下这一系列的文章来加深我对深度学习的结构化理解。
我将发布以下4个课程:
深度学习简介
基于神经网络的序列建模
计算机视觉中的深度学习-卷积神经网络
深度生成模型
对于每门课程,我将概述主要概念,并根据以前的阅读资料以及我在统计学和机器学习方面的背景增加更多的细节和解释。
从第2课程开始,我还将为每一课的开源数据集添加一个应用程序。
好的,让我们开始吧!
深度学习简介
背景
传统的机器学习模型在处理结构化数据方面一直非常强大,并且已经被企业广泛用于信用评分、客户流失预测、消费者定位等。
这些模型的成功很大程度上取决于特征工程阶段的性能:我们越接近业务,从结构化数据中提取相关知识越多,模型就越强大。
当涉及到非结构化数据(图像、文本、语音、视频)时,手动特征工程是耗时的、脆弱的,而且在实践中是不可扩展的,这就是神经网络因其可以从原始数据中自动发现特征或者分类所需要的表示而越来越受欢迎的原因。它取代手动特征工程,允许一台机器既能学习特征又能利用这些特征执行特定的任务。
硬件(GPU)和软件(与AI相关的高级模型/研究)的进步也提升了神经网络的学习效果。
基本架构
深度学习的基本组成部分是感知器,它是神经网络中的单个神经元。
给定一组有限的m个输入(例如,m个单词或m个像素),我们将每个输入乘以一个权重
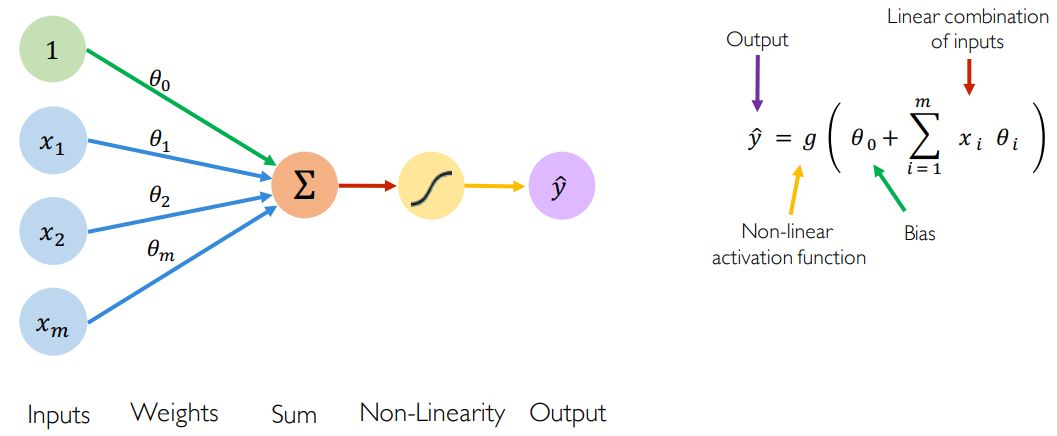
偏差会向输入空间添加另一个维度。因此,在输入全零向量的情况下,激活函数依然提供输出。它在某种程度上是输出的一部分,与输入无关。
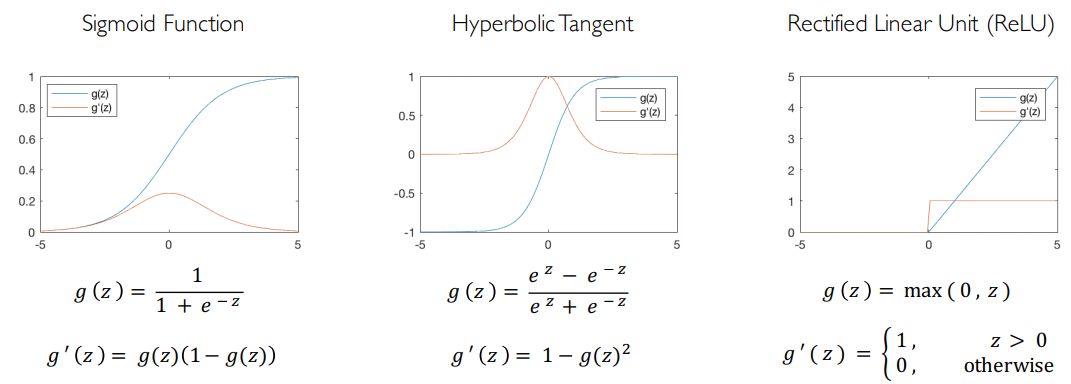
激活函数的目的是将非线性引入网络。实际上,无论输入分布如何,线性激活函数都会产生线性决策。非线性使我们能够更好地逼近任意复杂的函数,这里有一些常见的激活函数示例:
深度神经网络只是组合多个感知器(隐藏层),以产生输出。
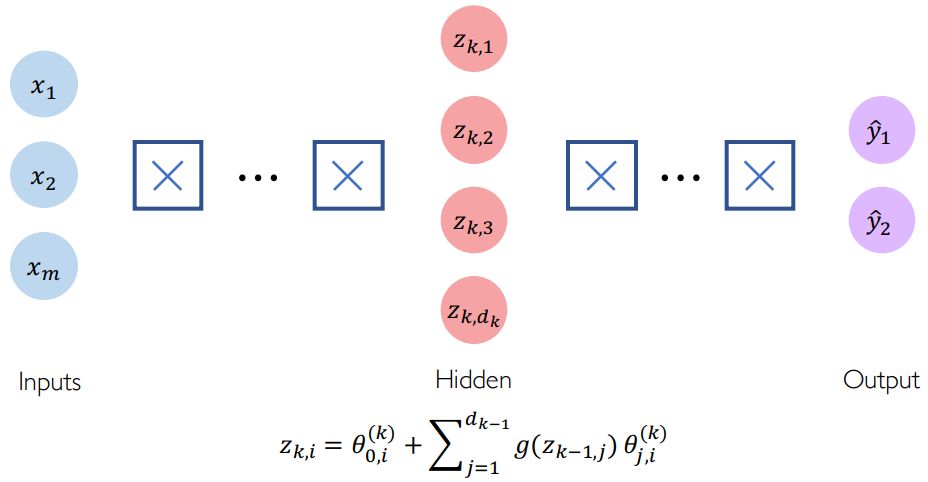
现在,我们已经了解了深度神经网络的基本架构,让我们看看它如何用于给定的任务。
训练神经网络
比方说,对于一组X射线图像,我们需要模型来自动区分病人与正常人。
为此,机器学习模型需要像人一样通过观察病人和正常人的图像来学会区分这两类图像。因此,它们自动理解可以更好地描述每类图像的模式,这就是我们所说的训练阶段。
具体地说,模式是一些输入(图像、部分图像或其他模式)的加权组合。因此,训练阶段只不过是我们估计模型权重(也称为参数)的阶段。
当谈论估计时,谈论的是我们必须优化的目标函数。构建这个函数,应该最好地反映训练阶段的性能。当涉及到预测任务时,这个目标函数通常称为损失函数,度量不正确的预测所产生的成本。当模型预测非常接近真实输出的东西时,损失函数非常低,反之亦然。
在存在输入数据的情况下,我们计算经验损失(分类的二元交叉熵损失和回归的均方差损失)来度量整个数据集上的总损失。
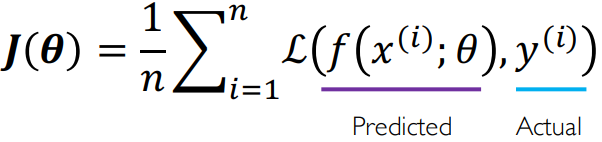
由于损失是网络权重的函数,我们的任务是找到实现最低损失的权重集:
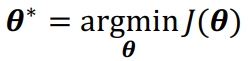
如果只有两个权重
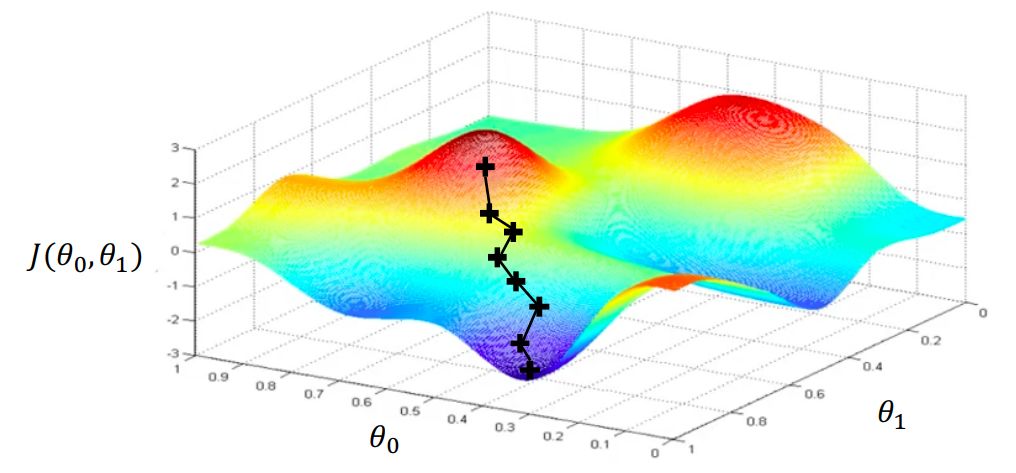
为了最小化损失函数,我们可以应用梯度下降算法:
首先,我们随机选择权重的初始p向量(例如,遵循正态分布)。
然后,我们计算初始p向量中损失函数的梯度。
梯度方向指示的是使损失函数最大化的方向。 因此,我们在梯度的反方向上迈出了一小步,使用此更新规则相应地更新权重值:
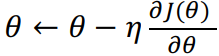
我们不断移动,直至收敛达到这张图的最低点(局部最小值)。
注意:
在更新规则中,
是学习率,决定着我们在梯度反方向上移动步伐的大小。它的选择非常重要,因为现代神经网络的架构是非常非凸的。如果学习率太低,模型可能陷入局部最小值;如果学习率太大,模型则可能发散。可以采用自适应学习率来调整梯度每次迭代时的学习率。有关更详细的说明,请阅读Sebastian Ruder对梯度下降优化算法的概述。
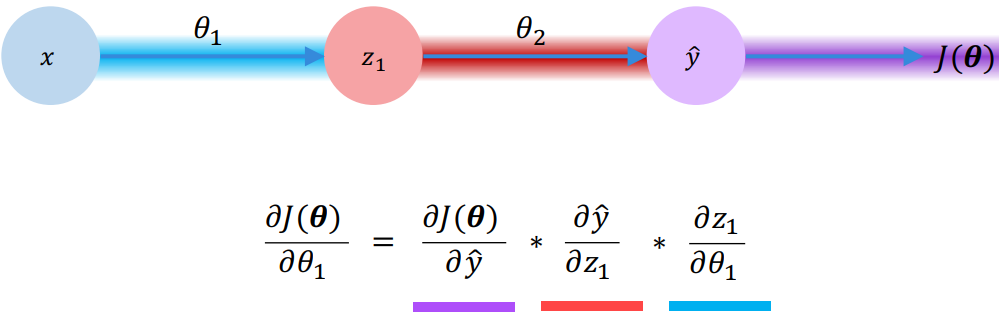
为了计算给定向量的损失函数的梯度,我们使用反向传播。考虑上面的简单神经网路络,它包含一个隐含层和一个输出层。想要计算与每个参数有关的损失函数的梯度
,首先,应用链规则,因为
。然后,再次应用链规则来将梯度反向传播给前一层。出于同样的原因,我们可以这样做,因为
(隐藏状态)仅取决于输入
。因此,反向传播包括使用来自后面层的梯度对网络中每个权重重复这样的过程。
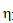
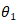
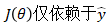

神经网络实践
在存在大数据集的情况下,关于每个权重的梯度计算可能非常昂贵(考虑反向传播中的链规则)。为此,我们可以计算数据子集(小批量)的梯度,将其作为真实梯度的估计值。它能给出比仅随机进行一次观察的随机梯度下降(SGD)更准确的梯度估计值,而且比使用全部数据进行梯度计算的方式要快。每次迭代使用小批量梯度计算,可以快速训练模型,特别是当我们使用不同的线程(GPU)时。我们可以并行计算每个迭代:每个权重和梯度的批处理在单独的线程中计算。然后,收集计算以完成迭代。
和任何其他“经典”机器学习算法一样,神经网络可能面临过度拟合的问题。理想情况下,在机器学习中,我们希望构建这样的模型:能够从训练数据中学习问题描述,而且也能够很好地概括看不见的测试数据。正则化是一种限制优化问题、避免产生复杂模型(即避免记忆数据)的方法。当谈论正则化时,我们通常会讨论Dropout。它在训练阶段随机丢弃(丢弃,即将相关激活设置为0)某些隐藏神经元或者在有可能过度拟合的情况下提前结束训练过程。为此,我们计算相对于训练迭代次数的训练和测试阶段的损失。当测试阶段的损失函数开始增加时,我们停止学习。
总结
第一篇文章是对深度学习的介绍,可归纳为3个要点:
首先,我们了解了深度学习的基本组成部分,即感知器。
然后,我们学会了将这些感知器组合在一起以组成更复杂的层次模型,并学会了如何使用反向传播和梯度下降从数学上来优化这些模型。
最后,我们已经看到了在现实生活中训练这些模型的一些实际挑战,以及一些最佳实践,如自适应学习,批处理和避免过度拟合的正则化。
下一篇文章将是关于神经网络的序列建模。我们将学习如何模拟序列,重点关注递归神经网络(RNN)及其短期记忆和长期短期记忆(LSTM)以及它们在多个时间步长内跟踪信息的能力。
敬请关注!
原文标题:
Introduction to Deep Learning
原文链接:
https://www.kdnuggets.com/2018/09/introduction-deep-learning.html
译者简介

张玲,在岗数据分析师,计算机硕士毕业。从事数据工作,需要重塑自我的勇气,也需要终生学习的毅力。但我依旧热爱它的严谨,痴迷它的艺术。数据海洋一望无境,数据工作充满挑战。感谢数据派THU提供如此专业的平台,希望在这里能和最专业的你们共同进步!
翻译组招募信息
工作内容:将选取好的外文前沿文章准确地翻译成流畅的中文。如果你是数据科学/统计学/计算机专业的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友,数据派翻译组欢迎你们加入!
你能得到:提高对于数据科学前沿的认知,提高对外文新闻来源渠道的认知,海外的朋友可以和国内技术应用发展保持联系,数据派团队产学研的背景为志愿者带来好的发展机遇。
其他福利:和来自于名企的数据科学工作者,北大清华以及海外等名校学生共同合作、交流。
点击文末“阅读原文”加入数据派团队~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派THU ID:DatapiTHU),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
发布后请将链接反馈至联系邮箱(见下方)。未经许可的转载以及改编者,我们将依法追究其法律责任。


点击“阅读原文”拥抱组织



