Beyond 预训练语言模型,NLP还需要什么样的知识?
预训练语言模型的不足

用知识弥补模型的不足

解语:关联中文文本与词汇知识
https://www.paddlepaddle.org.cn/textToKnowledge
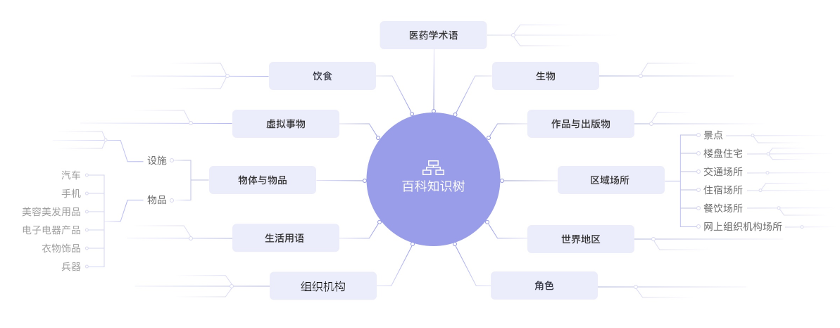
百科知识树(TermTree)
中文词类知识标注工具(WordTag)
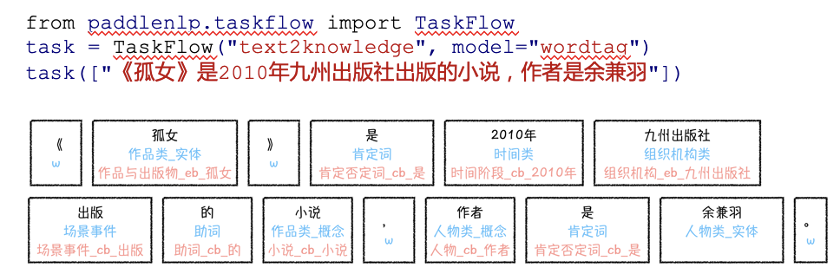

解语的应用场景示例
总结与展望

https://www.paddlepaddle.org.cn/textToKnowledge
https://github.com/PaddlePaddle/PaddleNLP/tree/develop/examples/text_to_knowledge
https://github.com/PaddlePaddle/PaddleNLP
参考资料
[2] Zhong Z, Chen D. A Frustratingly Easy Approach for Entity and Relation Extraction[J]. arXiv preprint arXiv:2010.12812, 2020.
登录查看更多
相关内容

Arxiv
0+阅读 · 2022年4月17日
Arxiv
0+阅读 · 2022年4月15日
Arxiv
11+阅读 · 2018年2月16日


相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2022年4月17日
Arxiv
0+阅读 · 2022年4月15日
Arxiv
11+阅读 · 2018年2月16日