5月13日-15日举办的CCF青年精英大会(YEF2021),特别组织思想秀,邀请各界贤达与业界青年共同探讨方略大事。作为CCF青年精英大会(YEF)最重要核心的环节之一,“思想秀”邀请海内外在学术、产业、公益等方面的知名学者和企业家作为青年导师向参会者对话演讲,汇聚学术和产业前瞻思想,判研未来发展之路,畅谈社会责任理想,分享历程心得。
哈尔滨工业大学社会计算与信息检索研究中心车万翔教授受邀在中国计算机学会青年精英大会(CCF YEF)2021的“思想秀”环节,以《自然语言处理新范式》为题介绍了自然语言处理的昨天和今天,并展望了明天!本文整理了报告的主要内容。
大家好!我是车万翔,来自哈尔滨工业大学社会计算与信息检索研究中心,今天很高兴有机会和大家分享一下自然语言处理领域的最新进展。
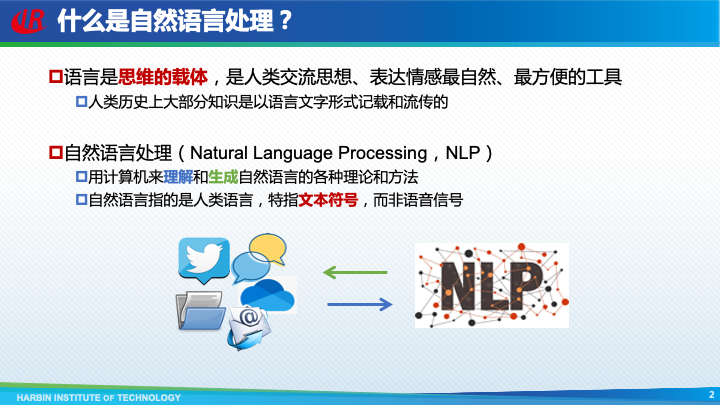
语言是思维的载体,是人类交流思想、表达情感最自然、最方便的工具。人类历史上大部分知识是以语言文字形式记载和流传的。
自然语言处理,英文名称是Natural Language Processing,简称NLP,主要研究用计算机来理解和生成自然语言的各种理论和方法。其中自然语言指的是人类语言,特指文本符号,而非语音信号。对语音信号的识别与合成属于语音处理领域的研究范畴。
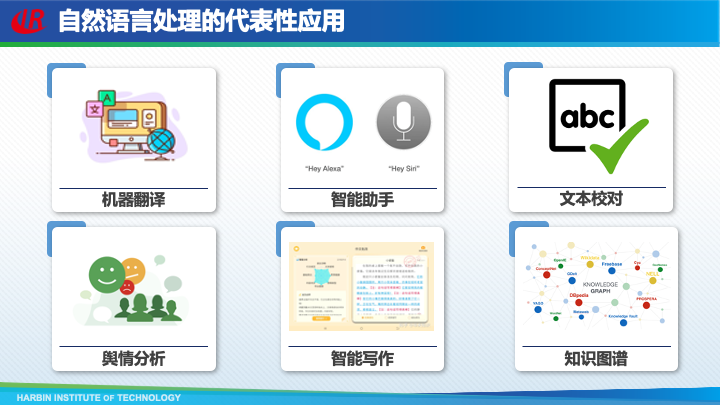
自然语言处理已经产生了很多实际的应用,如机器翻译、手机中的智能助手、文本校对等等。可以说,只要涉及到文本的智能化处理,都离不开自然语言处理技术。然而,目前这些应用给用户的体验并不好,还远远没有达到人们的期待。这是什么原因呢?
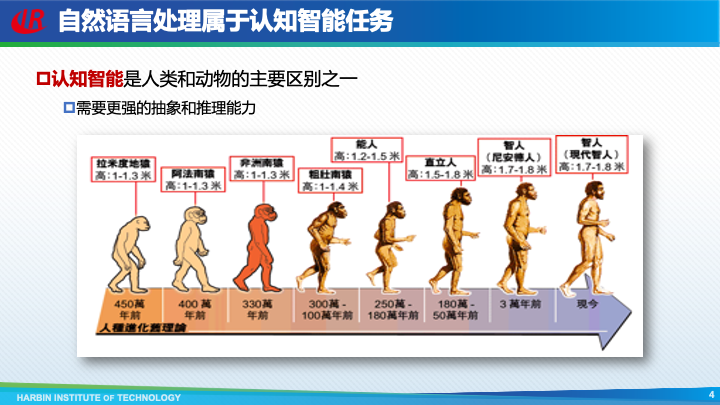
这主要是由于自然语言处理属于认知智能任务,而认知智能是人类和动物的主要区别之一,需要更强的抽象和推理能力才能实现。通俗地讲,就是自然语言处理太难了!
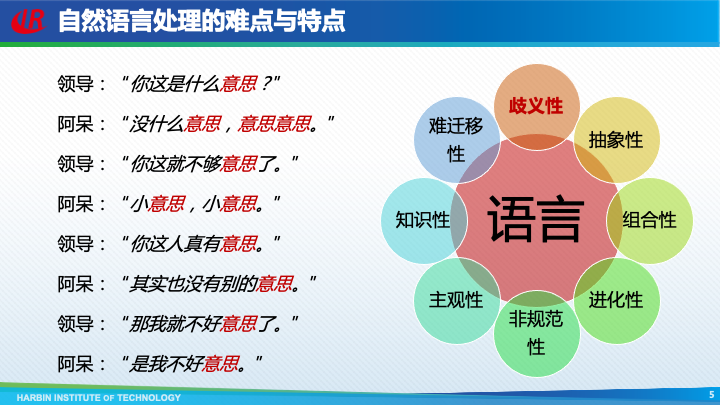
那么,自然语言处理到底难在哪呢?我们通过一个例子来看一下,这是领导和阿呆的对话,其中有很多的“意思”,它们又有很多不同的意思。这体现了自然语言具有非常严重的歧义性的特点,除了歧义性外,自然语言还具有抽象性、组合性、进化性、非规范性等八个主要特点。
以上这些难点和特点为自然语言处理带来了极大的挑战,并使自然语言处理成为目前制约人工智能取得更大突破和更广泛应用的瓶颈之一。包括多位图灵奖得主在内的多位知名学者都表示了对自然语言处理的极大关注。甚至图灵本人,也将验证机器是否具有智能的手段—“图灵测试”,设定为通过自然语言进行人机对话的场景。因此,自然语言处理也被誉为“人工智能皇冠上的明珠”。
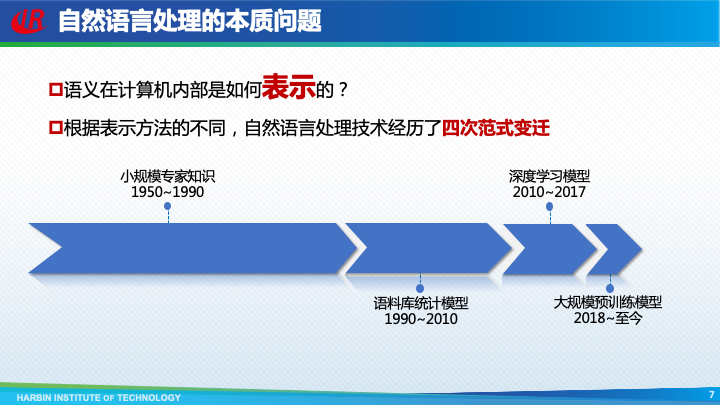
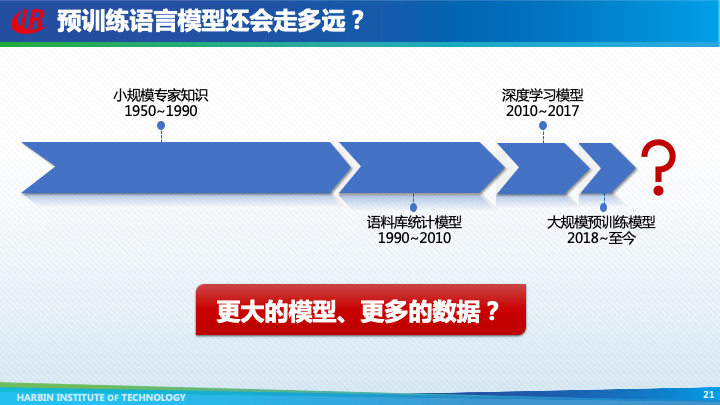
经过60余年的发展,人们已经研发了各种各样自然语言处理技术,这些纷繁复杂的技术本质上都是在试图回答一个问题:语义在计算机内部是如何表示的?根据表示方法的不同,自然语言处理技术共经历了四次范式变迁。
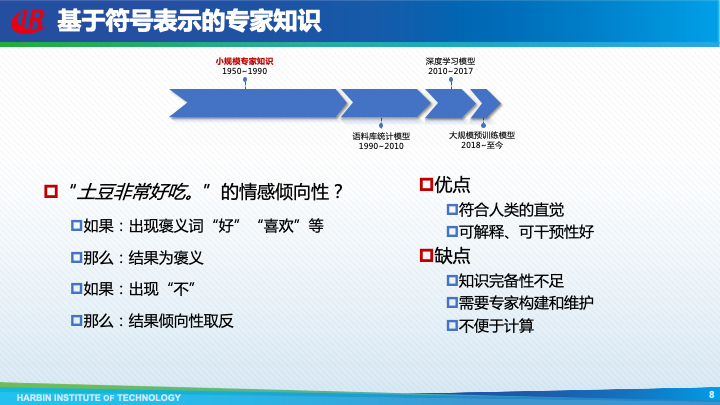
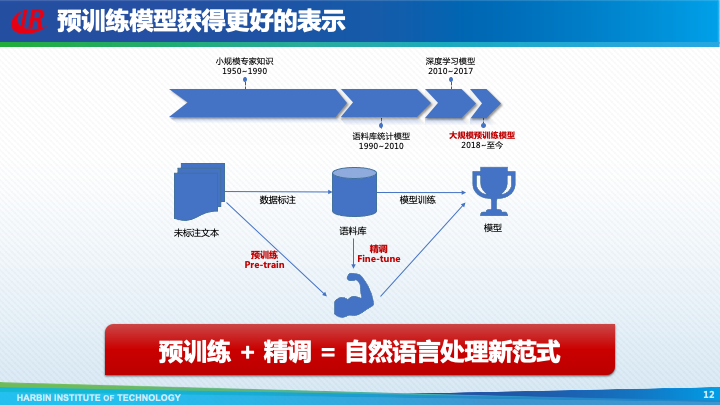
自然语言处理发展的前40年,利用的是基于符号表示的小规模专家知识,也就是通过人工定义的规则以及语言知识库,来解决一些简单的自然语言处理问题。这种方法的优点是符合人类的直觉,并且具有良好的可解释和可干预性。但是缺点也非常明显,首先是知识完备性不足,无法覆盖很多的长尾语言现象;其次是需要大量的专家来构建和维护规则和知识库;最后就是非常不便于计算。
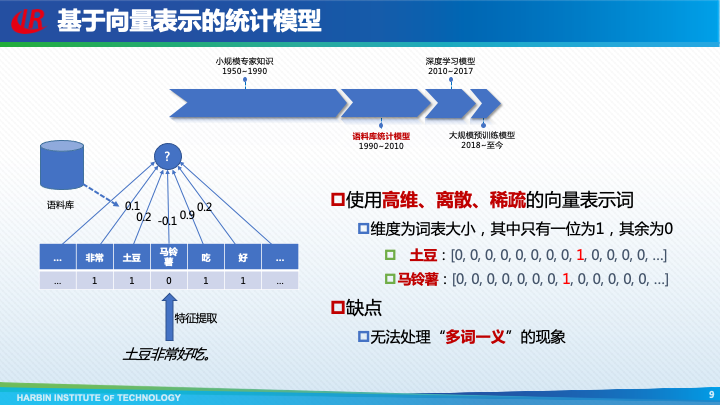
于是,从上世纪90年代初,自然语言处理全面转向了基于语料库统计模型的范式。这一时期主要特点是使用提取特征的方式,将自然语言表示为高维、离散、稀疏的向量,然后对向量中的数值进行加权求和,结果作为最终判断的依据。其中权重是通过对语料库的统计获得的。
对于词的表示也是类似,维度为词表大小,其中只有一位为1,其余为0,这又被称为独热向量表示。然而,这种独热词向量表示的方法无法解决“多词一义”的问题,也就是说即便两个词含义相近,那么它们的表示也是截然不同的。如“马铃薯”和“土豆”使用两个不同的独热向量表示。
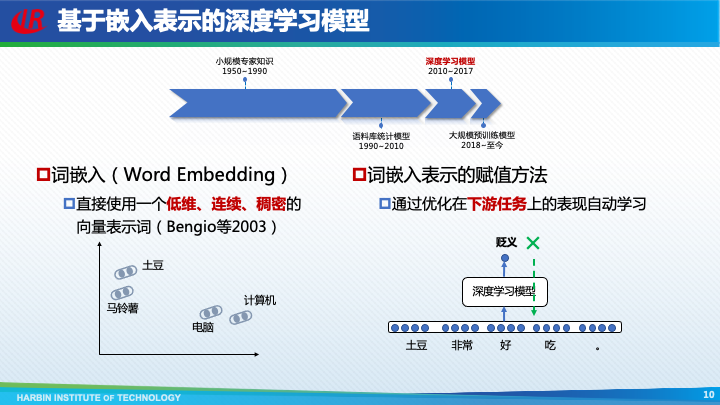
2010年左右,自然语言处理逐渐开始采用深度学习模型,其特点是使用嵌入表示来表示语义。图灵奖得主Bengio于2003年首次提出了词嵌入(Word Embedding)的概念,即直接使用一个低维、稠密、连续的向量表示词。这样,语义上相近的两个词,它们嵌入表示的距离也比较近。
那么,如何对词嵌入表示进行赋值呢?我们可以通过优化其在下游任务上表现自动地进行学习。如仍然以“土豆非常好吃”为例,首先将每个词转换为词嵌入,然后经过一个深度学习模型,如果识别的结果为“贬义“,显然结果是错误的,这种错误的信息就可以通过反向传播的方式用于更新模型的参数,包括词嵌入表示。
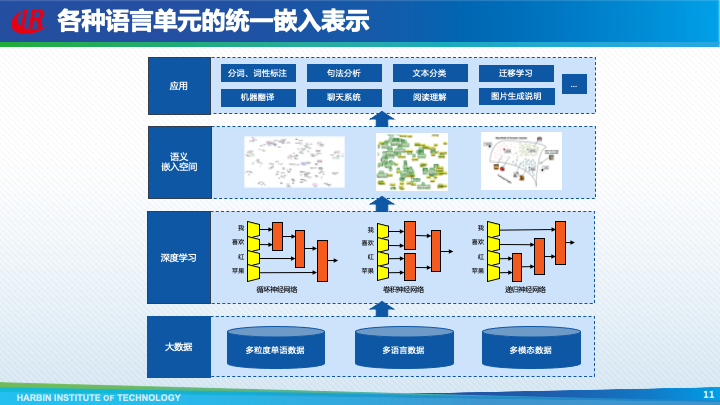
不光是词的表示,短语、句子、篇章等更长的语言单元,可以使用循环神经网络、卷积神经网络等深度学习模型,对词嵌入表示进行组合,从而获得更长单元的嵌入表示。甚至多语言、多模态数据都可以使用嵌入向量进行表示。
无论是语料库统计模型还是深度学习模型,都是基于人工标注的语料库,由于标注成本过高,导致语料库的规模非常有限。如果能够先在更大规模的未标注文本上进行预训练,然后使用下游任务的语料库进行精调,就可以获得更强大的模型。现在,这种预训练 + 精调的模式,已经成为了自然语言处理的新范式。
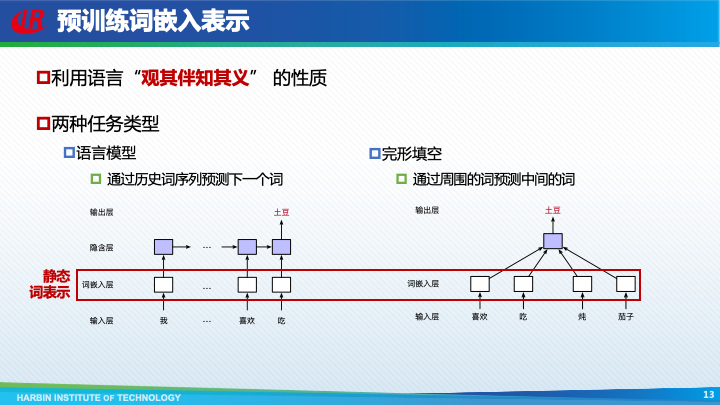
人们最开始只想到对词嵌入进行预训练,其思想是利用语言存在“观其伴知其义”的性质,自然构成一个“下游任务”。具体的任务可以分为两类:第一类是通过历史词序列,预测下一个词,这又被称作”语言模型“任务;另一类是利用周围的词预测中间的词,这类似于”完形填空“任务。这样,各种电子文档、图书乃至整个互联网上的文本数据,都可以作为训练数据,从而极大增强了词嵌入表示的学习能力。
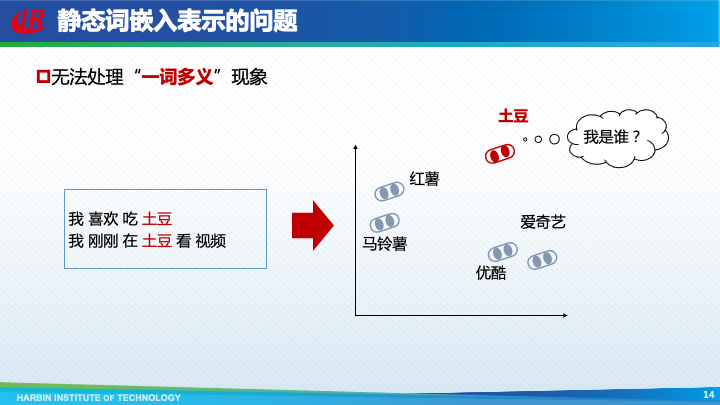
虽然可以处理”多词一义“现象,但是静态词嵌入表示本身仍然存在一个致命的固有缺陷,即无法处理”一词多义“现象。因为词嵌入的一个基本假设是每一个词对应唯一一个词嵌入表示。这样,如果一个词有多种词义,那么用哪个词义的向量来表示这个词呢?仍然以”土豆“这个词为例,它即是一种蔬菜,此时应该和”马铃薯“等词的表示相似;同时也是一个视频网站,此时又应该和”爱奇艺“等词的表示相似,那么最终”土豆“的词嵌入表示必将是个”四不像“。
为了解决上述问题,AI2于2018年提出了ELMo(Embeddings from Language Models)模型,其核心思想是使用语言模型的输出作为词向量,该表示是上下文相关的,也叫做动态词嵌入表示。如在句子”我喜欢吃土豆“中,”土豆“的表示应该和”马铃薯“相似;而在句子”我在土豆上看电影“中,”土豆“的表示则应该和”爱奇艺“相似。将ELMo输出的词向量作为特征,极大提高了多种下游任务的性能。
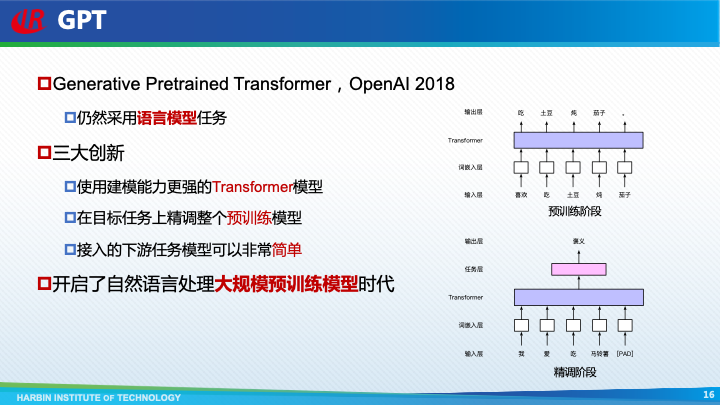
然而,好景不长,ELMo提出不久,OpenAI便提出了第一代GPT(Generative Pretrained Transformer)模型,正式将自然语言处理带入到“预训练”时代。和ELMo一样,GPT也是使用语言模型任务作为预训练任务,不过GPT模型有三大创新:首先,它使用了性能更强大的Transformer模型;其次,它提出在目标任务上精调整个模型,而不是只将模型的输出结果作为固定的词向量特征;最后,由于预训练模型自身足够复杂,所以接入的下游任务模型可以非常简单,这极大降低了自然语言处理的门槛。
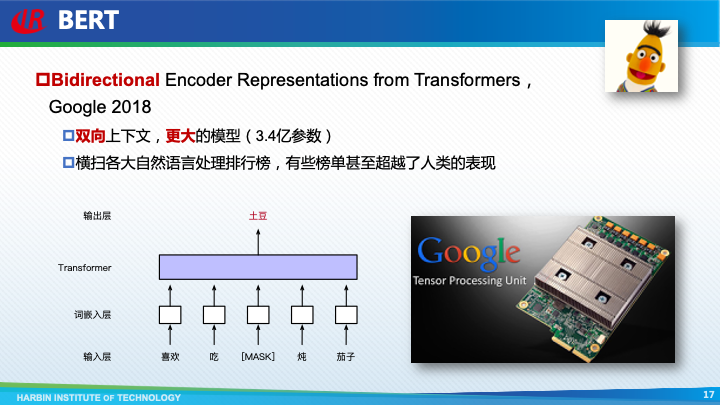
GPT提出后不久,大名鼎鼎的 BERT(Bidirectional Encoder Representations from Transformers)模型便登场了。和GPT相比,BERT最大的改进就体现在它名字中的字母**B**,即双向的意思。也就是说利用两边的上下文,来预测中间的词,即使用完形填空作为预训练任务。由于使用了更丰富的上下文以及更大的模型,BERT获得了更好的预训练效果,横扫了各大自然语言处理任务排行榜,在有些榜单上甚至超越了人类的表现。
BERT的提出者是几位当时刚从微软跳槽到Google的研究人员,所以Google真的是非常幸运,能够笼络到如此优秀的人才,不过我们也要注意到,正是由于Google在人工智能领域多年的积累,尤其是拥有强大的人工智能算力—TPU,才使得BERT模型能够横空出世。
后来,微软痛定思痛,建造了自己的超大规模人工智能计算平台,并同OpenAI联合训练了GPT-3模型。和前两代GPT模型相比,GTP-3在模型结构上并没有太大的变化,不过它含有1750亿超大规模参数,由于模型参数太大,以致于无法再对它进行精调的操作了。为了适应于不同的任务,需要针对不同任务提供相应的“提示语”,如:只输入任务描述“Translate English to French:”以及具体的问题,“cheese => ”,那么GPT-3就能够直接输出翻译的结果;如果在输入任务描述之后再给一个或几个示例,那么任务完成的效果会更好。GPT-3更惊艳的是能够无需针对下游任务进行训练,便可以完成各种”文本“生成任务,这里面的”文本“是打引号的,也就是说不但能够生成纯文本,还能生成网页、乐谱甚至程序代码等。有人说GPT-3更像是一种通用的人工智能,因为它能够完成各种非预先设定的任务。
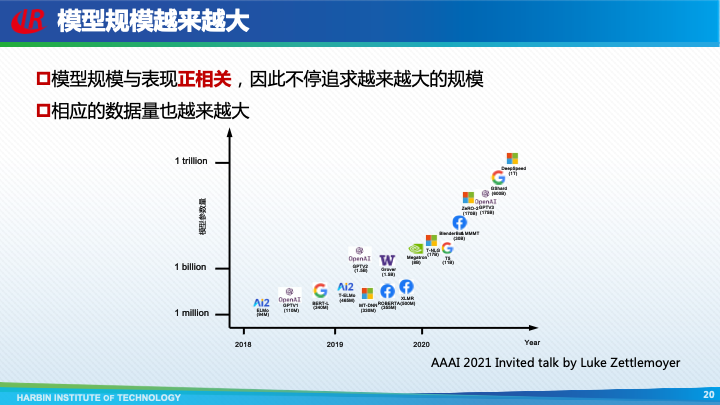
随着研究的逐渐深入,人们意识到模型规模与模型表现之间具有非常强的正相关性,因此预训练模型变得越来越大,各大厂商俨然开始了一场军备竞赛。
那么,自然语言处理会沿着预训练模型这条路一直走下去么?
也就是说模型会越来越大,数据会越来越多么?
答案显然是否定的。
首先,现在模型规模的增大趋势远远超过了摩尔定律,所以硬件迟早会无法支撑特别大规模的预训练模型;
其次,人们能获得的文本数据毕竟也不可能是无限的。
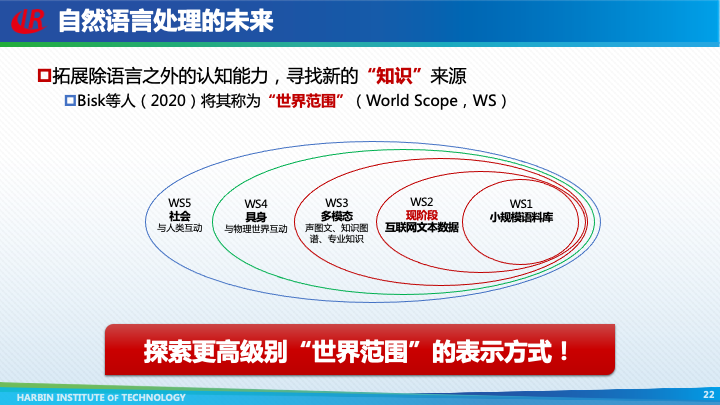
为了未来真正实现自然语言处理,一定要拓展除语言之外的认知能力,寻找新的“知识”来源。Bisk等人(2020)将其称为“世界范围”(World Scope,WS),并划分了五个级别。
现阶段,基于互联网文本数据的预训练模型只达到了第二个级别。然而,人类的知识并非仅仅存放于文本之中,还有大量其它模态的知识是以视频、图像、知识图谱、专业知识等方式存储的,因此,下一个阶段一定需要融合更多其它模态的知识。
即便能够将所有模态的知识都利用起来,如果一个自然语言处理系统不与物理世界进行互动的话,它也无法真正理解诸如”什么是冷、什么是暖;什么是软、什么时候硬“等概念。
最后,语言本质上是人与人交流的工具,所以系统还需要通过与人类社会的互动,才能更自然地运用语言。只有到了这一步,真正的自然语言处理,甚至通用人工智能才可能带来。
为了实现这一目标,自然语言处理研究的下一步就是要努力探索更高级别“世界范围”的表示方式!
编辑:钟蔚弘,彭湃,朱文轩,冯晨,牟虹霖,张馨,王若珂,高建男
长按下图即可关注哈尔滨工业大学社会计算与信息检索研究中心微信公众号『哈工大SCIR』。