千亿 KV 数据存储和查询方案
(点击上方公众号,可快速关注)
来源:任何忧伤,都抵不过世界的美丽,
zqhxuyuan.github.io/2015/12/17/Billion-KV/#
背景
md5是不可解密的. 通常网站http://www.cmd5.com/宣称的解密都是有一个MD5到值的映射数据库(彩虹表).
做法是提前将数据用MD5加密,然后保存成MD5到原数据的映射关系,解密时只要查询MD5对应的值就可以了.

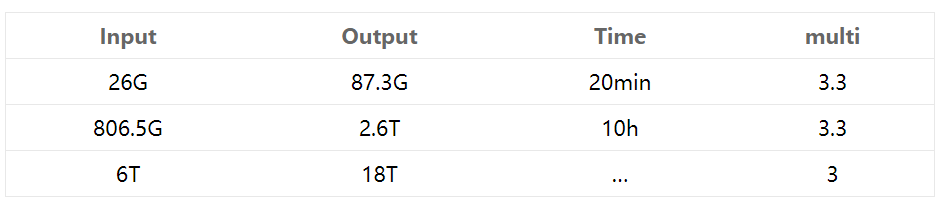
业务数据将近1000亿,估算下来大概占用6T. 由于MD5的数据是32位,而且每一位都属于0-f.
如果直接查询生成的6T数据,速度估计很慢. 于是想到分区, 比如以32位MD5的前几位相同的作为一个分区,
查询时首先将MD5路由到指定的分区, 再查询这个分区的所有数据,这样每个分区的数据量就会少很多.
原始文件data.txt(最后两个字段表示MD5的前四位):
111111111111111,001e5a2b1c68d7b7dddddddddddddddc,00,1e
222222222222222,01271cc012464ae8ccccccccccccccce,01,27
Hive分区(×)
临时表和分区表:
CREATE EXTERNAL TABLE `mob_mdf_tmp`(
`mob` string,
`mdf` string,
`mdf_1` string,
`mdf_2` string
)
ROW FORMAT delimited fields terminated by ','
LOCATION 'hdfs://tdhdfs/user/tongdun/mob_mdf_tmp';
CREATE EXTERNAL TABLE `mob_mdf`(
`mob` string,
`mdf` string
)
PARTITIONED BY (
mdf_1 string,
mdf_2 string)
stored as parquet
LOCATION 'hdfs://tdhdfs/user/tongdun/mob_mdf';
将原始文件导入到临时表(或者用hive的load命令),然后读取临时表,加载数据到分区表
#!/bin/sh
file=$1
/usr/install/hadoop/bin/hadoop fs -put $file /user/tongdun/mod_mdf_tmp
#LOAD DATA LOCAL INPATH 'id.txt' INTO TABLE id_mdf PARTITION(mdf_1='ab',mdf_2='cd');
#LOAD DATA LOCAL INPATH 'id.txt' INTO TABLE id_mdf_tmp;
/usr/install/apache-hive/bin/hive -e "
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
SET hive.exec.max.dynamic.partitions=100000;
SET hive.exec.max.dynamic.partitions.pernode=100000;
set mapreduce.map.memory.mb=5120;
set mapreduce.reduce.memory.mb=5120;
INSERT into TABLE mod_mdf PARTITION (mdf_1,mdf_2) SELECT mod,mdf,mdf_1,mdf_2 FROM mod_mdf_tmp;
msck repair table mod_mdf;
"
问题:将原始文件导入到HDFS是很快的,基本分分钟搞定.但是转换成分区的Hive表,速度起慢无比. %><%
AWK脚本处理分区
A.原始文件首先拆分成一级文件,再拆分成二级文件(×)
一级拆分: awk -F, ‘{print >> $3}’ data.txt
上面的awk命令会按照第三列即MD5的前两个字符分组生成不同的文件. 比如生成00,01文件.
然后进行二级拆分: 遍历所有的一级文件, 生成二级文件. 比如001e.txt, 0127.txt.
nums=('0' '1' '2' '3' '4' '5' '6' '7' '8' '9' 'a' 'b' 'c' 'd' 'e' 'f')
for n1 in ${nums[@]};
do
for n2 in ${nums[@]};
do
var=$n1$n2
awk -F, '{OFS=",";print $1,$2 >> $3_$4".txt"}' $var
done
done
echo "end."
缺点: 每个数据文件都必须在自己的范围内生成一级文件, 然后在自己的一级文件基础上生成二级文件.
最后所有的二级文件要合并为一个文件. 比较麻烦, %><%
B.原始文件直接生成两级拆分文件
直接拆分成两级的: awk -F, ‘{OFS=”,”;print $1,$2 >> $3_$4″.txt”}’ data.txt
优点: 由于有多个原始数据文件, 执行同样的awk命令, 生成最终结果不需要任何处理.
问题: 大文件分组,速度比较慢,而且不像上面的分成两次,0000.txt文件并不会立刻有数据生成.
同样还有一个问题: 如果多个文件一起追加>>数据, 会产生冲突,即写到同一行.
C.切分原始大文件(×)
对原始大文件(20G~100G)先split: split -C 2014m $file,再进行上面的二级拆分过程.
结果: 27G切分成2G一个文件, 耗时538s. 估算6T数据需要500h~20D. %><%
paldb@linkedin(×)
linkedin开源的paldb声称对于写一次的kv存储读取性能很好. 但是一个严重的问题是不支持在已有的db文件中新增数据.
Can you open a store for writing subsequent times?
No, the final binary file is created when StoreWriter.close() is called.
所以要读取所有的原始文件后,不能一个一个文件地处理. 这期间StoreWriter要一直打开,下面是索引文件的代码:
//直接读取所有原始文件, 生成paldb
public static void indexRawFile(String[] files) throws Exception{
List<String> prefix = generateFile();
//提前准备好Writer
Map<String,StoreWriter> maps = new HashMap();
for(String pref : prefix){
StoreWriter writer = PalDB.createWriter(new File(folder + pref + ".paldb"));
maps.put(pref, writer);
}
for(String filepath : files){
File file = new File(folder + filepath);
BufferedInputStream fis = new BufferedInputStream(new FileInputStream(file));
BufferedReader reader = new BufferedReader(new InputStreamReader(fis,"utf-8"),5*1024*1024);// 用5M的缓冲读取文本文件
String line = "";
while((line = reader.readLine()) != null){
String[] data = line.split(",");
//根据前两位, 确定要使用哪个Writer. 相同2位前缀的记录写到同一个db文件里
String prefData = data[2];
maps.get(prefData).put(data[1], data[0]);
}
fis.close();
reader.close();
}
for (Map.Entry<String, StoreWriter> entry : maps.entrySet()) {
entry.getValue().close();
}
}
查询一条记录就很简单了, 首先解析出MD5的前两位, 找到对应的paldb文件, 直接读取:
System.out.println("QUERYING>>>>>>>>>");
String file = md5.substring(0,2) + ".paldb";
StoreReader reader = PalDB.createReader(new File(folder + file));
String id = reader.get(md5);
System.out.println(id);
sparkey@spotify
sparkey也声称对于read-heavy systems with infrequent large bulk inserts对于经常读,不经常(大批量)写的性能很好.
sparkey有两种文件:索引文件(index file)和日志文件(log file).
Spark BulkLoad
HBaseRDD:
https://github.com/unicredit/hbase-rdd
SparkOnHBase在最新的HBase版本中已经合并到了hbase代码中.
建立一个columnfamily=id. 并且在这个cf下有一个column=id存储id数据(cf必须事先建立,column则是动态的).
create 'data.md5_id','id'
put 'data.md5_id','a9fdddddddddddddddddddddddddddde','id:id','111111111111'
get 'data.md5_id','a9fdddddddddddddddddddddddddddde'
scan 'data.md5_id'
Spark的基本思路是: 读取文本文件, 构造RowKey -> Map<CF -> Map<Column -> Value>>的RDD:
val rdd = sc.textFile(folder).map({ line =>
val data = line split ","
val content = Map(cf -> Map(column -> data(0)))
data(1) -> content
})
rdd.toHBaseBulk(table)
HBase BulkLoad
HBase的BulkLoad分为两个节点: 运行MapReduce生成HFile文件, 导入到HBase集群
数据存储: http://zqhxuyuan.github.io/2015/12/19/2015-12-19-HBase-BulkLoad/
查询(多线程): http://zqhxuyuan.github.io/2015/12/21/2015-12-21-HBase-Query/

存在的问题: 在生成HFile时,是对每个原始文件做MR任务的,即每个原始文件都启动一个MR作业生成HFile.
这样只保证了Reduce生成的HFile在这个原始文件是有序的.不能保证所有原始文件生成的HFile是全局有序的.
这样当只导入第一个文件夹时,BulkLoad是直接移动文件.但是导入接下来生成的文件夹时,就会发生Split操作!
虽然每个MapReduce生成的HFile在这个文件夹内是有序的. 但是不能保证所有MR作业的HFile是全局有序的!
MapReduce/importtsv completebulkload(mv)
txt1 -------------------> HFile(00-03) --------------------> Region
HFile(03-10) --------------------> Region
HFile(10-30) ️ --------------------> Region
MapReduce/importtsv bulkload(split and copy!)
txt2 -------------------> HFile(01-04)
HFile(04-06)
HFile(06-15)
数据验证:
hbase(main):002:0> get 'data.md5_mob2','2774f8075a3a7707ddf6b3429c78c041'
COLUMN CELL
0 row(s) in 0.2790 seconds
hbase(main):003:0> get 'data.md5_mob2','695c52195b25cd74fef1a02f4947d2b5'
COLUMN CELL
mob:c1 timestamp=1450535656819, value=69
mob:c2 timestamp=1450535656819, value=5c
mob:mob timestamp=1450535656819, value=13829274666
3 row(s) in 0.0640 seconds
Cassandra
Cassandra和HBase都是列式数据库.HBase因为使用MapReduce,所以读取HDFS上的大文件时,会分成多个Map任务.
Cassandra导入数据不可避免的是需要读取原始的大文件,一种直接生成SSTable,一种是读取后直接写入到集群中.
SSTable Writer
//构造Cassandra的Writer对象
CQLSSTableWriter.Builder builder = CQLSSTableWriter.builder();
builder.inDirectory(outputDir).forTable(SCHEMA).using(INSERT_STMT).withPartitioner(new Murmur3Partitioner());
CQLSSTableWriter writer = builder.build();
//读取大文件,写入到Writer对象,最终会生成SSTable文件
while ((line = reader.readLine()) != null) {
writer.addRow(line.split(",")[1],line.split(",")[0]);
}
单独地遍历文件,不做任何事情,耗时100s=2min. 则读取6T的文件,耗时2000min=33hour.
Driver API
List<Statement> statementList = new ArrayList();
while ((line = reader.readLine()) != null) {
BoundStatement bound = insert.bind(line.split(",")[1],line.split(",")[0]);
statementList.add(bound);
if(statementList.size() >= 65535){
flush(statementList);
statementList.clear();
}
}
// 批量写入
public static void flush(List<Statement> buffer) {
BatchStatement batch = new BatchStatement(BatchStatement.Type.UNLOGGED);
for (Statement bound : buffer) {
batch.add(bound);
}
client.execute(batch);
}
KV DataBase
其实我们的业务中只是KeyValue,最适合的不是列式数据库,而是KV数据库.常见的KV数据库有:MemCache,Redis,LevelDB/RocksDB,Riak.
LevelDB
一个数据库一次只能被一个进程打开。leveldb的实现要求使用来自操作系统的锁来阻止对数据库的滥用。在单进程中,同一个leveldb::DB对象可以被多个并发线程安全地共享。即,针对同一个数据库,在没有任何外部同步措施的前提下(leveldb实现本身将会自动去做所需要的同步过程),不同的线程可以写入迭代器或者获取迭代器或者调用Get方法。但是,其它的对象(比如Iterator和WriteBatch)可能需要外部的同步过程。如果两个线程共享一个这样的对象,这俩线程必须通过它们各自的加锁协议(locking protocol)来保护对这个对象的访问。
-rw-r--r--. 1 qihuang.zheng users 0 12月 24 11:44 000003.log
-rw-r--r--. 1 qihuang.zheng users 16 12月 24 11:44 CURRENT
-rw-r--r--. 1 qihuang.zheng users 0 12月 24 11:44 LOCK
-rw-r--r--. 1 qihuang.zheng users 57 12月 24 11:44 LOG
-rw-r--r--. 1 qihuang.zheng users 65536 12月 24 11:44 MANIFEST-000002
⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇
-rw-r--r--. 1 qihuang.zheng users 2116214 12月 24 11:49 000408.sst
...
-rw-r--r--. 1 qihuang.zheng users 3080192 12月 24 11:55 001210.sst
-rw-r--r--. 1 qihuang.zheng users 16 12月 24 11:44 CURRENT
-rw-r--r--. 1 qihuang.zheng users 0 12月 24 11:44 LOCK
-rw-r--r--. 1 qihuang.zheng users 215845 12月 24 11:55 LOG
-rw-r--r--. 1 qihuang.zheng users 196608 12月 24 11:55 MANIFEST-000002
可以看到旧的sst(SSTable)不断被删除,并用新的sst文件代替. 但是速度在处理大文件时依旧很慢.
结论: 涉及到要读取原始文件,遍历每一行,然后调用存储的写入方式即使采用批量,也会很慢.
而HBase的BulkLoad会开启多个Map任务读取大文件,因此速度会比遍历读取大文件要快.
happybase
既然读取大文件很慢,能不能在生成md5数据的时候不写文件, 直接写到目标数据库.
import happybase
connection = happybase.Connection('192.168.47.213')
table = connection.table('data.md5_id2')
def write_data(li):
batch = table.batch(wal=False)
for ele in li:
#wf.write(','.join(ele) + '\n')
#wf.flush()
batch.put(ele[0], {'id:id': ele[1]})
batch.send()
运行一个省份(35,记录数34亿)耗时:
2015-12-29 09:53:38 350100 19550229 999 60000
2015-12-31 02:35:38 359002 20011119 999 3457560000
其他
删除文件名长度=4的所有文件(不包括文件名后缀)
find . -type f | grep -P '/.{8}$' | xargs rm
a=($(ls | grep -E '[0-9a-f]{4}.txt')) && for i in "${a[@]}";do rm -rf "$i";done
查看进程的文件句柄数量(开了两个进程在跑,每个进程用了16^4=65535)
[qihuang.zheng@192-168-47-248 version2]$ lsof -n|awk '{print $2}'|sort|uniq -c |sort -nr|head -2
65562 6516
65562 10230
[qihuang.zheng@192-168-47-248 version2]$ jps
6516 GenIdCardRawFile
10230 GenIdCardRawFile
Final:Cassandra
数据存储
建表,列名统一为md5和id
CREATE KEYSPACE data WITH replication = {
'class': 'NetworkTopologyStrategy',
'DC2': '1',
'DC1': '1'
};
use data;
CREATE TABLE md5_id (
md5 text,
id text,
PRIMARY KEY (md5)
);
CREATE TABLE md5_mob (
md5 text,
id text,
PRIMARY KEY (md5)
);
存储时,指定tbl比如md5_id或者md5_mob
nohup java -cp /home/qihuang.zheng/rainbow-table-1.0-SNAPSHOT-jar-with-dependencies.jar \
com.td.bigdata.rainbowtable.store.Rainbow2Cassandra \
-size 5000 -host 192.168.48.47 -tbl md5_mob > rainbow-table.log 2>&1 &
单机SSD,设置批处理大小为5000,不能设置太大,写入记录数36亿,耗时52小时(身份证表)。
total cost[normal]:75705 s
total cost[error]:0 s
结果手工验证
根据md5查询一条记录,大概在6ms之内,看起来能满足线上的要求了。
cqlsh:data> select * from md5_mob where md5='00905121bedd2bb93247f4bd55ff6a73'
activity | timestamp | source | source_elapsed
-------------------------------------------------------------------------------------------+--------------+---------------+----------------
execute_cql3_query | 11:57:08,100 | 192.168.48.47 | 0
Parsing select * from md5_mob where md5='00905121bedd2bb93247f4bd55ff6a73'\n LIMIT 10000; | 11:57:08,102 | 192.168.48.47 | 1340
Preparing statement | 11:57:08,103 | 192.168.48.47 | 2529
Executing single-partition query on md5_mob | 11:57:08,104 | 192.168.48.47 | 3576
Acquiring sstable references | 11:57:08,104 | 192.168.48.47 | 3711
Merging memtable tombstones | 11:57:08,104 | 192.168.48.47 | 3822
Partition index with 0 entries found for sstable 2790 | 11:57:08,105 | 192.168.48.47 | 4726
Seeking to partition beginning in data file | 11:57:08,105 | 192.168.48.47 | 4765
Skipped 0/1 non-slice-intersecting sstables, included 0 due to tombstones | 11:57:08,106 | 192.168.48.47 | 5570
Merging data from memtables and 1 sstables | 11:57:08,106 | 192.168.48.47 | 5597
Read 1 live and 0 tombstone cells | 11:57:08,106 | 192.168.48.47 | 5728
Request complete | 11:57:08,106 | 192.168.48.47 | 6243
发生一次查询后查看系统的状态
[qihuang.zheng@192-168-48-47 ~]$ nodetool cfstats data.md5_mob
Keyspace: data
Read Count: 1
Read Latency: 2.361 ms.
Write Count: 3600002520
Write Latency: 0.008993030521545303 ms.
Pending Tasks: 0
Table: md5_mob
SSTable count: 11
Space used (live), bytes: 372167591162
Space used (total), bytes: 372167591162
Off heap memory used (total), bytes: 5780134424
SSTable Compression Ratio: 0.57171179318478
Number of keys (estimate): 3599990528
Memtable cell count: 20292
Memtable data size, bytes: 9344184
Memtable switch count: 9599
Local read count: 1
Local read latency: 2.361 ms
Local write count: 3600002520
Local write latency: 0.000 ms
Pending tasks: 0
Bloom filter false positives: 0
Bloom filter false ratio: 0.00000
Bloom filter space used, bytes: 4500010896
Bloom filter off heap memory used, bytes: 4,500,010,808
Index summary off heap memory used, bytes: 1237496744
Compression metadata off heap memory used, bytes: 42626872
Compacted partition minimum bytes: 87
Compacted partition maximum bytes: 103
Compacted partition mean bytes: 103
Average live cells per slice (last five minutes): 1.0
Average tombstones per slice (last five minutes): 0.0
查看直方统计图:
[qihuang.zheng@192-168-48-47 ~]$ nodetool cfhistograms data md5_mob
data/md5_mob histograms
SSTables per Read
1 sstables: 1
Write Latency (microseconds)
1 us: 57588
2 us: 10773767
3 us: 87425134
4 us: 309487598
5 us: 632214057
6 us: 802464460
7 us: 704315044
8 us: 477557852
10 us: 419183030
12 us: 108322995
14 us: 28197472
17 us: 10274579
20 us: 2620990
24 us: 1673315
29 us: 1436756
35 us: 833132
42 us: 328493
50 us: 154832
60 us: 119731
72 us: 109200
86 us: 111004
103 us: 87783
124 us: 95593
149 us: 94378
179 us: 93731
215 us: 102252
258 us: 107963
310 us: 109766
372 us: 112553
446 us: 110686
535 us: 108196
642 us: 101888
770 us: 96206
924 us: 90912
1109 us: 88118
1331 us: 83811
1597 us: 80263
1916 us: 75550
2299 us: 73414
2759 us: 65003
3311 us: 57738
3973 us: 46244
4768 us: 42409
5722 us: 72641
6866 us: 106743
8239 us: 84552
9887 us: 47690
11864 us: 36826
14237 us: 26347
17084 us: 13423
20501 us: 7169
24601 us: 3241
29521 us: 1327
35425 us: 547
42510 us: 242
51012 us: 82
61214 us: 31
73457 us: 31
88148 us: 255
105778 us: 244
126934 us: 322
152321 us: 1882
182785 us: 4259
219342 us: 5060
263210 us: 3006
315852 us: 629
379022 us: 340
454826 us: 95
545791 us: 13
654949 us: 5
785939 us: 10
943127 us: 0
1131752 us: 19
1358102 us: 0
1629722 us: 0
1955666 us: 0
2346799 us: 2
2816159 us: 1
Read Latency (microseconds)
2759 us: 1
Partition Size (bytes)
103 bytes: 3599989854
Cell Count per Partition
2 cells: 3599989854
随机查询RT是否满足。
看完本文有收获?请转发分享给更多人
关注「ImportNew」,提升Java技能