
题目: Order-Preserving Key Compression for In-Memory Search Trees
简介:
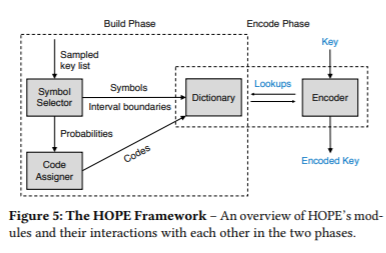
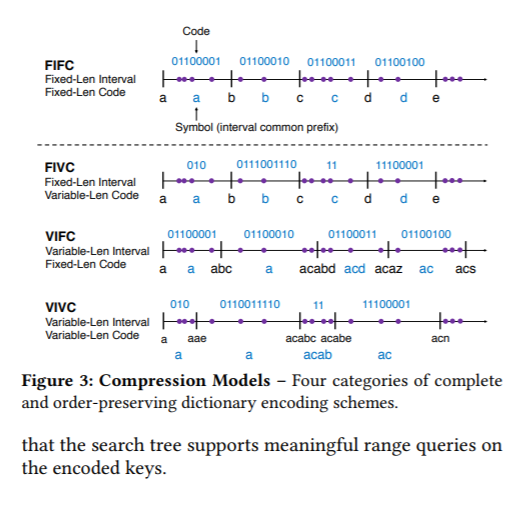
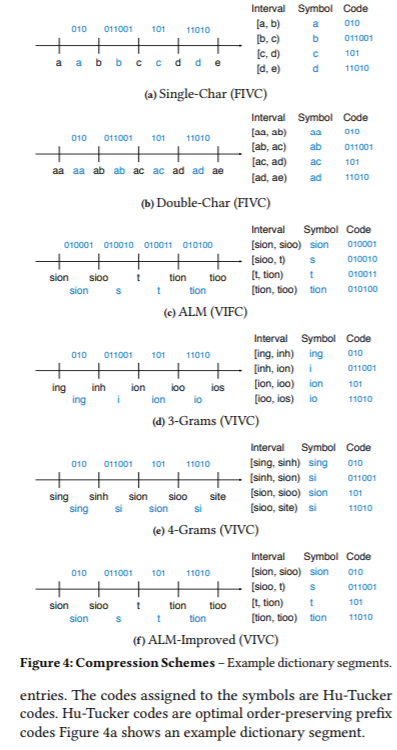
本文提出了一种用于内存搜索树的高速保序编码器(HOPE)。HOPE是一个快速的基于字典的压缩器,它可以对任意键进行编码,同时保持它们的顺序。HOPE的方法是在细粒度上识别常见的键模式,并利用熵实现小字典的高压缩率。我们首先建立了一个理论模型来推理关于保留订单的字典设计。在此基础上,选取了6种具有代表性的压缩方案,并进行了实验验证。这些方案在压缩率和编码速度之间进行了不同的权衡。我们对数据库中使用的五种数据结构进行了评估:SuRF、ART、HOT、B+tree和Prefix B+tree。我们的实验表明,对于大多数字符串键工作负载,使用HOPE允许搜索树同时实现更低的查询延迟(最多降低40%)和更好的内存效率(最多降低30%)。
成为VIP会员查看完整内容
相关内容
专知会员服务
31+阅读 · 2020年5月20日
专知会员服务
43+阅读 · 2020年4月22日
专知会员服务
11+阅读 · 2019年12月28日
专知会员服务
26+阅读 · 2019年11月23日
专知会员服务
36+阅读 · 2019年11月15日
Arxiv
18+阅读 · 2019年9月25日
Arxiv
5+阅读 · 2019年1月10日
Arxiv
5+阅读 · 2018年8月6日
Arxiv
4+阅读 · 2018年3月16日




相关VIP内容
专知会员服务
31+阅读 · 2020年5月20日
专知会员服务
43+阅读 · 2020年4月22日
专知会员服务
11+阅读 · 2019年12月28日
专知会员服务
26+阅读 · 2019年11月23日
专知会员服务
36+阅读 · 2019年11月15日
相关资讯
相关论文
Arxiv
18+阅读 · 2019年9月25日
Arxiv
5+阅读 · 2019年1月10日
Arxiv
5+阅读 · 2018年8月6日
Arxiv
4+阅读 · 2018年3月16日