KDD20 | 基于差分变量去相关的稳定学习

题目: 基于差分变量去相关的稳定学习
会议: KDD 2020
论文链接:http://pengcui.thumedialab.com/papers/Stable_DVD.pdf
推荐理由: 近年来,稳定学习,其旨在训练一个可以在未知环境稳定预测的模型,受到广泛关注,特别在金融等对于模型稳定性有较高的要求的高风险领域。本文提出一种基于差分变量去相关的稳定学习方法,该方法对于变量对的重要性进行了区分,实验证明区分变量对重要性比不区分具有更好的模型稳定性。
1 引言
大量的机器学习模型假设训练数据和测试数据来源于相同的数据分布(IID假设)。然而,在实际情况下,这个条件并不一定满足,比如,我们在不同的时间段和区域内收集的数据可能会有不同的数据分布,从而导致训练和测试数据的分布不同。更严重的是,最近有文献指出,模型偏差可能会引入更大的泛化误差。为了解决训练和测试偏差的问题,已经提出了一些方法,比如,迁移学习,然而其需要预先知道测试数据分布,然而真实情况下测试数据是不可知的。最近,有研究考虑了模型偏差问题,并尝试通过样本重加权实现变量去相关以学习具有稳定性保证的模型。然而,他们尝试通过以下方删除所有变量之间的相关性新的学习样本权重集。但是,这种激进的目标可能会导致样本量过分减少,这种情况会影响机器学习模型性能。
不同于之前去除所有的变量相关性,本文认为并不是所有的相关性都有必要去除。例如,当您想在图像分类任务中识别狗时,尽管狗的鼻子,耳朵和嘴巴可能会由不同的变量代表,它们作为一个整体这样的相关性在不同的环境中都是稳定的。同样,可能存在另一堆变量代表背景(即草)。由于选择偏差,我们可能会观察到这两种变量之间的强相关性在有偏差的训练数据上。但是,这样的“虚假”相关不能推广到新的环境。因此,对于这种情况,我们仅需要消除显著变量和背景变量之间的虚假相关性来获得准确的狗分类器。
2 方法
在本文中,我们研究了用于回归任务的线性模型范围内的稳定学习问题,并在问题设置中引入了两个基本假设:
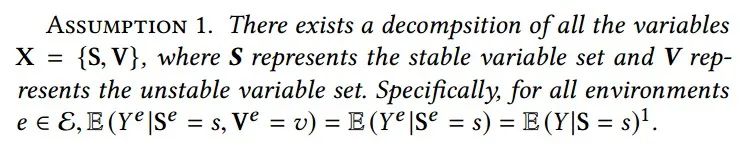

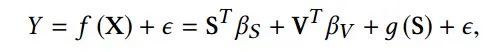
其中, 是传统线性模型学到的回归系数, 是稳定特征的非线性转换函数, 是独立噪声变量。以OLS为例,我们旨在最小化如下平方损失:
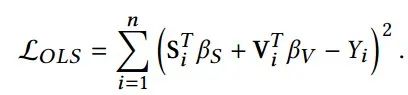
可以导出:
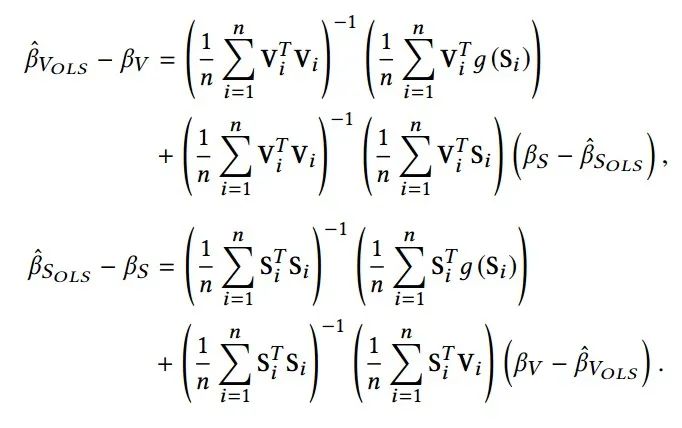
从上式可以看出,我们可以找到估计错误主要是由两个原因引起的:不稳定变量 和模型偏差项 (或 )以及稳定变量 和错误偏差项 之间的相关性。后一种情况是不可避免的,因为我们无法预先获取非线性变换,在某种程度上我们可以忍受。因此,如果我们可以将V和S解相关,则学习的模型会更稳定。
受因果文献中样本加权技术的启发,研究人员提出了使用样本加权技术消除变量之间的相关性。特别地,他们通过联合最小化每个变量对之间的分布差异来学习样本权重:
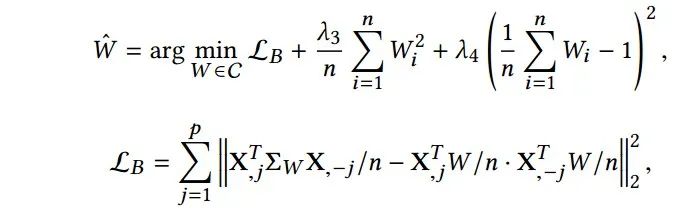
所提出的权重学习算法提供了一个新的角度去除变量相关性而不会丢失重要变量。但是,实际上很难将所有变量去相关,在这种情况下,解的唯一性需要 。因此,本文考虑有区别的去除变量相关性。
差分变量去相关
不是单独考虑所有变量,而受到启发通过前面提到的狗分类的例子,我们假设变量在变化的分布下具有内在的组结构,如下所示:
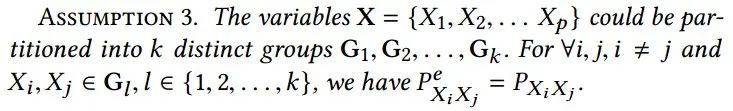
此外结合Assumption 1,我们可以得出结论,将稳定变量 和不稳定变量 划分为不同的变量群体:
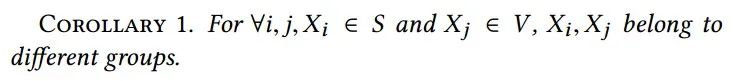
通过利用来自多个环境的额外的未标记数据 ,我们提出通过两个变量联合分布相关性的方差来捕获不变特性并且定义两个变量之间的差异性如下:
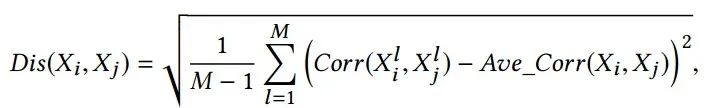
直观地讲,差异性较低的变量更有可能在不断变化的环境中保持稳定的联合分布并应归为同一组变量。通过计算所有变量对之间的不相似性以及进一步的变换每个变量进入p维向量空间:
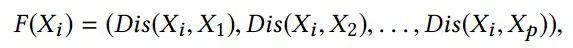
将具有较低差异性的变量分组到同一组中等同于对F执行常规聚类分析,我们可以使用k-means技术。
结合变量聚类过程,我们提出了差分变量解相关(DVD)算法,如下所示:
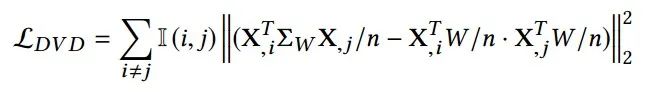
利用学习的样本权重W 可以解相关不同聚类之间的变量,可以运行如下加权最小二乘来估算回归系数:
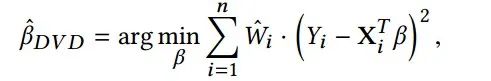
3 实验
本文在仿真数据集和真实数据上验证了模型的有效性。
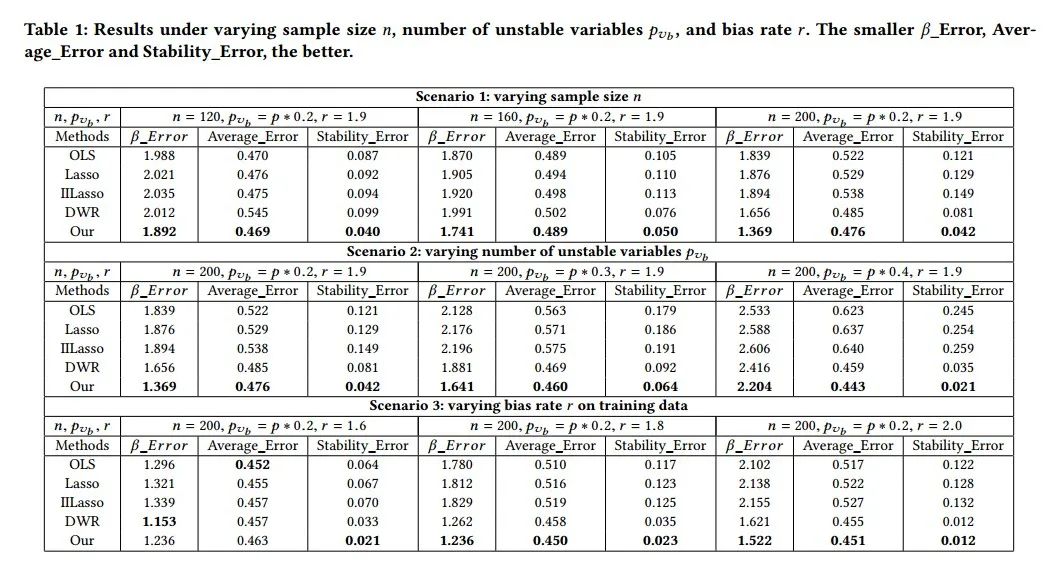
表1是仿真数据的结果,可以看出在不同偏差条件下所提出的方法相对于对比方法都有较稳定性能提升。
4 结论
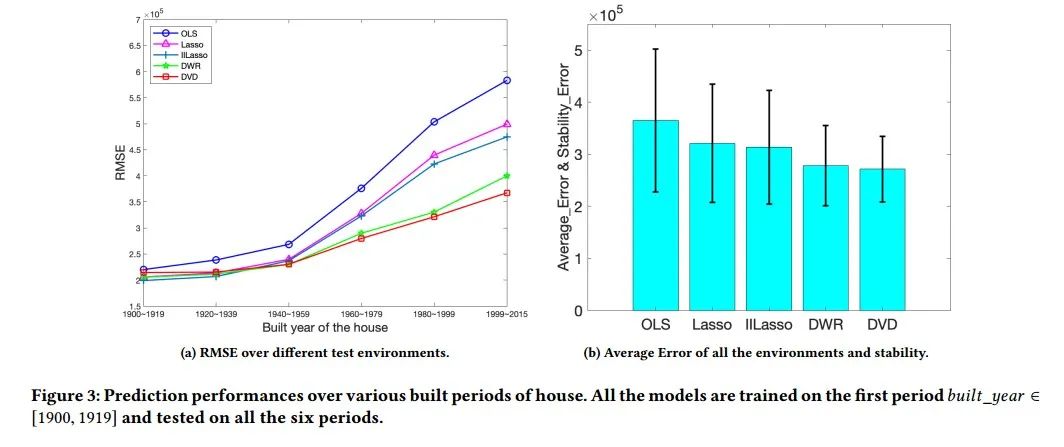
在本文中,我们重点研究如何在有模型偏差的条件下实现机器学习模型在非稳定环境下的稳定预测。我们认为以前基于变量解相关的方法设置的目标是删除变量之间的所有依赖关系。但是,在高维真实环境中很难完成并可能导致样本量过分减少。实际上,只有虚假相关在不同环境下可能会有所不同,是应该消除的。与这个观念相一致,我们将异构的未标记数据融合到变量解相关框架中并提出基于变量聚类的差分变量解相关(DVD)算法,能够消除偏差数据中的虚假相关性,而保持更高的有效样本量。在合成数据集和真实数据集上的实验,都清楚地表明了DVD算法在变化分布上对于改善模型参数的估计和预测稳定性的有效性。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“SLDV” 可以获取《KDD20 | 基于差分变量去相关的稳定学习》专知下载链接索引