最新10篇《知识图谱》论文推荐(ICML, CVPR, ACL, KDD, IJCAI 2019)
【导读】知识图谱一直是研究热点,研究者近年来广泛关注知识图谱嵌入(Knowledge Graph Embedding,简称KGE)方法,在保留语义的同时,将知识图谱中的实体和关系映射到连续的、稠密的低维向量空间,从而可以通过向量来高效计算实体与关系的语义联系,利用学习得到的实体/关系的表征向量支撑下游应用。专知整理了最新ACL、CVPR、KDD、ICML等顶会关于知识图谱的10篇最新论文,欢迎查看!
1. 多视角知识图谱嵌入的实体对齐,Multi-view Knowledge Graph Embedding for Entity Alignment
IJCAI ’19 南京大学
作者:Qingheng Zhang, Zequn Sun, Wei Hu, Muhao Chen, Lingbing Guo, Yuzhong Qu
摘要:我们研究了基于知识图谱嵌入的实体对齐问题。之前的工作主要关注实体的关系结构。有些还进一步合并了另一种类型的特性,例如属性,以进行细化。然而,大量的实体特性仍然没有被平等地放在一起处理,这损害了基于嵌入的实体对齐的准确性和健壮性。在本文中,我们提出了一个新的框架,它统一了实体的多个视图来学习实体对齐的嵌入。具体来说,我们使用几种组合策略基于实体名称、关系和属性的视图嵌入实体。此外,我们设计了一些跨知识图谱推理方法来增强两个知识图谱之间的对齐,我们在实际数据集上的实验表明,该框架的性能显著优于目前最先进的基于嵌入的实体对齐方法。所选择的视图、跨知识图谱推理和组合策略都有助于性能的提高。
网址:
http://www.zhuanzhi.ai/paper/37af68666dac9cd9f7954a6d92a56daf
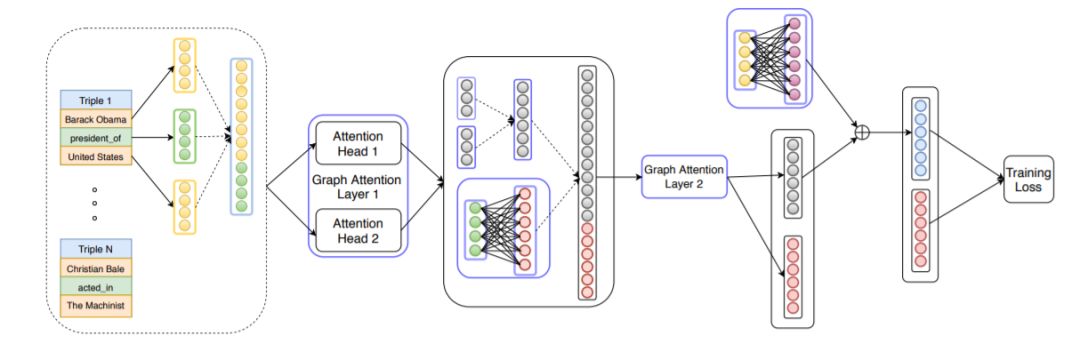
2. 知识图谱中的关系预测,Learning Attention-based Embeddings for Relation Prediction in Knowledge Graphs
ACL ’19
作者:Deepak Nathani, Jatin Chauhan, Charu Sharma, Manohar Kaul
摘要:近年来,知识图谱(KGs)的大量出现,实体间出现的缺失关系(链接)等不完全或部分信息,引发了对知识库补全(也称为关系预测)的大量研究。最近的一些研究表明,基于卷积神经网络(CNN)的模型能够生成更丰富、更有表现力的特征嵌入,因此在关系预测方面也表现得很好。然而,我们观察到这些KG嵌入独立地处理三元组,因此无法覆盖三元组周围的本地固有的隐含的复杂和隐藏信息。为此,本文提出了一种新的基于注意力的特征嵌入方法,该方法可以同时捕获任意给定实体邻域中的实体和关系特征。此外,我们还在模型中封装了关系集群和多跳关系。我们的实证研究为我们基于注意力的模型的有效性提供了深刻的验证,并且与所有数据集上最先进的方法相比,模型显示了显著的性能提升。
网址:
http://www.zhuanzhi.ai/paper/48c10eb0f286d7a84bbb250a76adac18
3. 知识图谱中的二面体群关系嵌入,Relation Embedding with Dihedral Group in Knowledge Graph
ACL ’19 ebay
作者:Deepak Nathani, Jatin Chauhan, Charu Sharma, Manohar Kaul
摘要:链接预测对于不完全知识图谱(KG)在下游任务中的应用至关重要。作为链接预测的一组有效方法,嵌入方法尝试学习实体和关系的低秩表示,使其中定义的双线性形式是一个良好的评分函数。现有的双线性形式虽然表现良好,但忽视了关系成分的建模,导致对KG推理缺乏可解释性。为了填补这一空白,我们提出了一种新的二面体模型,以二面体对称群命名。该模型学习知识图谱嵌入,能够自然地捕获关系组合。此外,我们的方法对离散值参数化的关系嵌入进行了建模,从而大大减小了求解空间。我们的实验表明,二面体能够捕获所有期望的性质,如(斜)对称,反演和(非)阿贝耳成分,并优于现有的基于双线性形式的方法,是可比或更好的深度学习模型,如ConvE。

网址:
http://www.zhuanzhi.ai/paper/52aaa05b176ea2973de99170d7464700
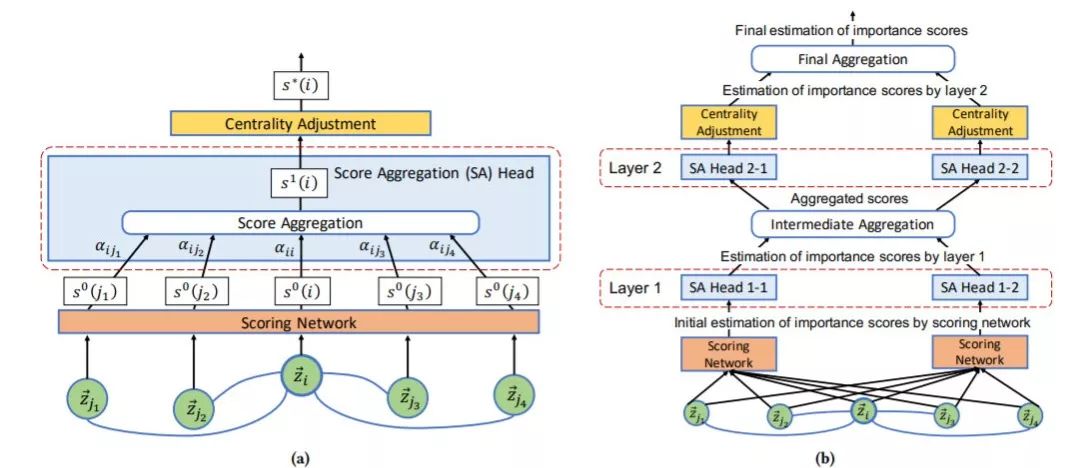
4. 图神经网络估计知识图谱节点重要性,Estimating Node Importance in Knowledge Graphs Using Graph Neural Networks
KDD ’19 亚马逊
作者:Namyong Park, Andrey Kan, Xin Luna Dong, Tong Zhao, Christos Faloutsos
摘要:如何估计知识图谱(KG)中节点的重要性?KG是一个多关系图,它被证明对于许多任务(包括问题回答和语义搜索)都很有价值。在本文中,我们提出了一种解决KGs中节点重要性估计问题的GENI方法,该方法支持项目推荐和资源分配等下游应用。虽然已经现有一些方法来解决一般图的这个问题,但是它们没有充分利用kg中可用的信息,或者缺乏建模实体与其重要性之间复杂关系所需的灵活性。为了解决这些限制,我们研究了监督机器学习算法,基于图神经网络进行,我们开发GENI GNN-based方法旨在处理涉及预测节点重要性在知识图谱的独特挑战。我们的方法执行一个聚合的重要性分数而不是嵌入聚合节点通过predicate-aware注意调整机制和灵活的中心。在我们对GENI和现有方法的评估中,GENI在预测具有不同特征的真实KGs中节点重要性方面比现有方法高出5-17%。
网址:
http://www.zhuanzhi.ai/paper/b6589e8b0f0c755769ae6f77776fbaaa
5. 跨语言知识图谱对齐,Cross-lingual Knowledge Graph Alignment via Graph Matching Neural Network
ACL ’19 腾讯AI Lab
作者:Kun Xu, Liwei Wang, Mo Yu, Yansong Feng, Yan Song, Zhiguo Wang, Dong Yu
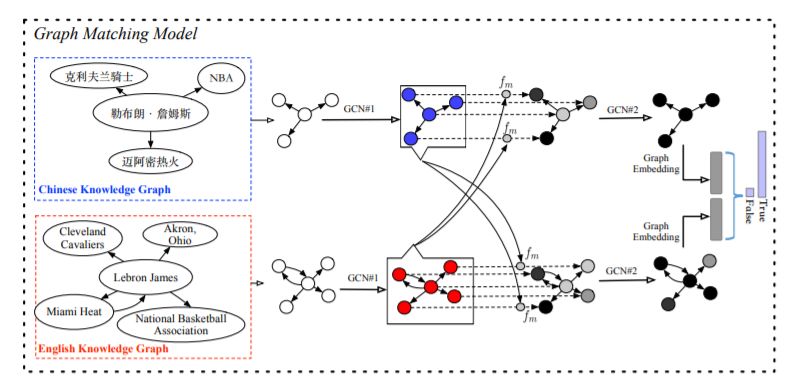
摘要:以前的跨语言知识图谱对齐的研究依赖于只来自单语知识图谱结构信息的实体嵌入, 它可能会在两个知识图谱匹配实体有不同的事实情况下失败。在本文中,我们介绍了主题实体图, 一个实体的局部子图,在知识图谱代表实体的上下文信息。从这个角度看,知识库对齐任务可以表示为一个图匹配问题;进一步提出了一种基于图注意力机制的解决方案,该方案首先匹配两个主题实体图中的所有实体,然后对局部匹配信息进行联合建模,得到一个图级匹配向量。实验表明,我们的模型大大优于以往最先进的方法。
网址:
http://www.zhuanzhi.ai/paper/7620eabdf10c14c9cb8dfcbd73885f5a
6. 利用知识图谱中的长关系依赖学习,Learning to Exploit Long-term Relational Dependencies in Knowledge Graphs
ICML ’19 南京大学
作者:Lingbing Guo, Zequn Sun, Wei Hu
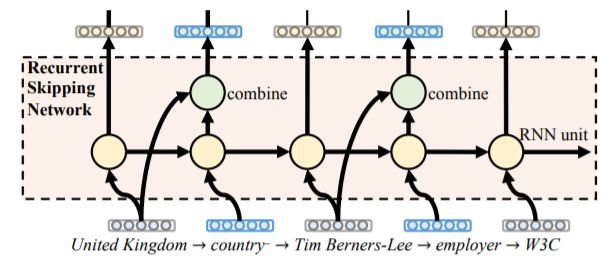
摘要:研究了知识图(KG)嵌入问题。对这个问题的一个广泛建立的假设是,相似的实体可能具有相似的关系角色。然而,现有的相关方法主要基于三元组学习来获取KG嵌入,缺乏获取实体长期关系依赖关系的能力。此外,三元组学习对于实体间语义信息的传播是不够的,尤其是在跨kg嵌入的情况下。在本文中,我们提出了一种循环跳网(RSNs),它采用一种跳网机制来消除实体之间的间隙。RSNs将递归神经网络(RNNs)与残差学习相结合,有效地捕获了KGs内部和KGs之间的长期关系依赖关系。我们的实验结果表明,RSNs在实体对齐方面优于目前最先进的基于嵌入式的方法,并且在KG补全方面具有竞争力。
网址:
http://www.zhuanzhi.ai/paper/b6589e8b0f0c755769ae6f77776fbaaa
7. 零样本学习知识图谱传播再思考,Rethinking Knowledge Graph Propagation for Zero-Shot Learning
CVPR ’19 CMU
作者:Michael Kampffmeyer, Yinbo Chen, Xiaodan Liang, Hao Wang, Yujia Zhang, Eric P. Xing
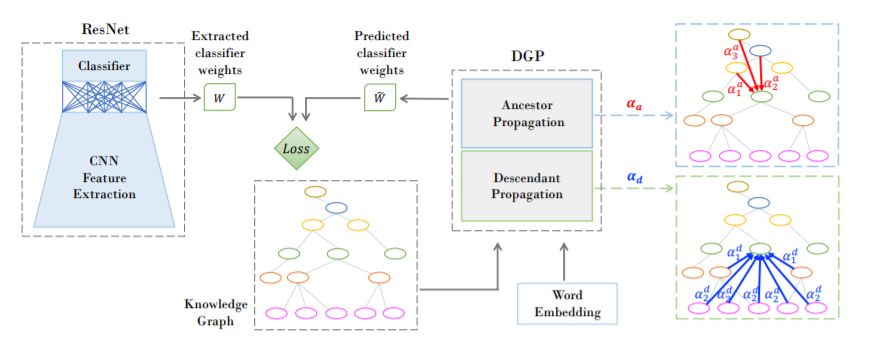
摘要:最近,图卷积神经网络在零样本学习任务中显示出了巨大的潜力。这些模型具有很高的样本效率,因为图结构中的相关概念具有相同的统计强度,允许在缺少数据时对新类进行泛化。然而,由于多层架构需要将知识传播到图中较远的节点,因此在每一层都进行了广泛的拉普拉斯平滑,从而稀释了知识,从而降低了性能。为了在保证图结构带来的好处的同时防止知识从遥远的节点被稀释,我们提出了一个密集图传播(DGP)模块,该模块在遥远的节点之间精心设计了直接链接。DGP允许我们通过额外的连接来利用知识图的层次图结构。这些连接是根据节点与其祖先和后代的关系添加的。为了提高图中信息的传播速度,进一步采用加权方案,根据到节点的距离对它们的贡献进行加权。结合两阶段训练方法中表示的细化,我们的方法优于目前最先进的零样本学习方法。
网址:
http://www.zhuanzhi.ai/paper/011b254f6780093cdf7d02560b9564da
8. 知识图谱注意力网络推荐,KGAT: Knowledge Graph Attention Network for Recommendation
KDD ’19 NUS
作者:Xiang Wang, Xiangnan He, Yixin Cao, Meng Liu, Tat-Seng Chua
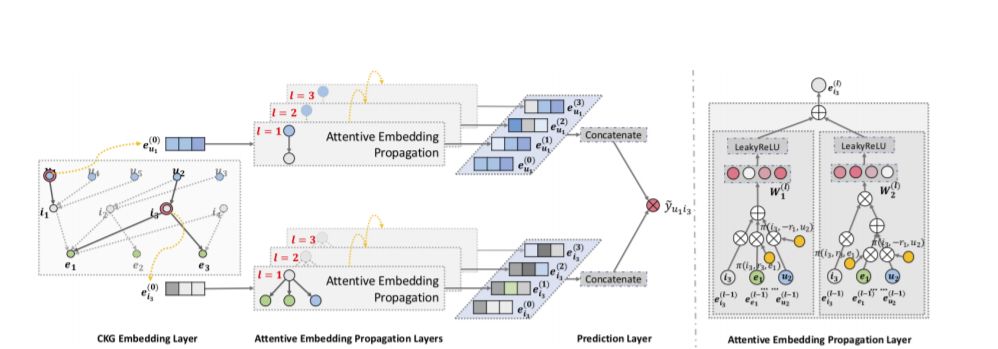
摘要:为了提供更准确、多样化和可解释的推荐,必须超越对用户-物品交互进行建模并考虑侧边信息。传统的方法,如因子分解机(FM)将其转换为一个监督学习问题,它假设每一个交互都是一个独立的实例,并对边信息进行编码。由于忽略了实例或项目之间的关系(例如,一个电影的导演同时也是另一个电影的演员),这些方法不足以从用户的集体行为中提取协作信号。在本文中,我们研究了知识图谱(KG)的效用,它通过将项目与其属性链接起来,打破了独立交互的假设。我们认为,在KG和用户-项目图谱的这种混合结构中,高阶关系——用一个或多个链接属性连接两个项目——是成功推荐的一个重要因素。提出了一种新的知识图注意网络(KGAT)方法,该方法以KG为单位,以端到端方式显式地建模高阶连接度。它递归地从节点的邻居(可以是用户、项或属性)传播嵌入,以改进节点的嵌入,并使用注意力机制来区分邻居的重要性。我们的KGAT在概念上优于现有的基于kg的推荐方法,这些方法要么通过提取路径来利用高阶关系,要么通过正则化对它们进行隐式建模。三个公共基准测试的经验结果表明,KGAT的性能显著优于最先进的方法,如神经FM和rippleet。进一步的研究验证了嵌入传播对高阶关系建模的有效性以及注意机制带来的可解释性好处。
网址:
http://www.zhuanzhi.ai/paper/ba34bb70dbf906e4423ca23a4b9274f9
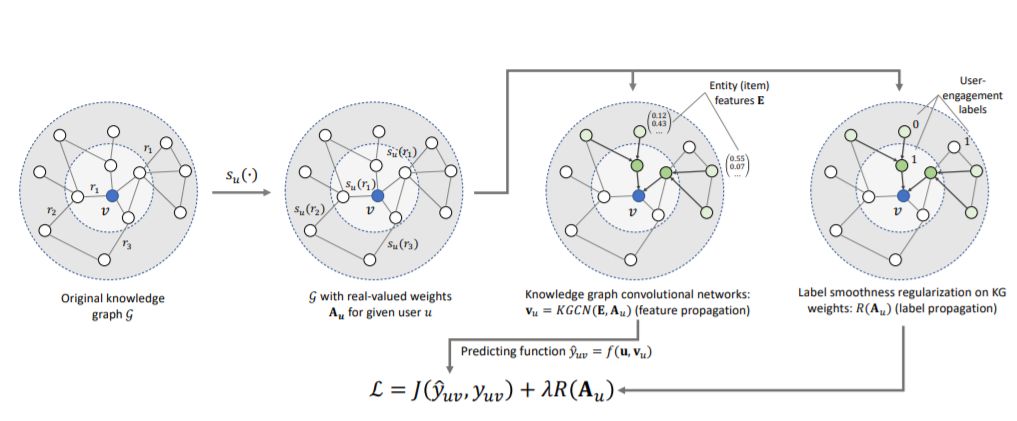
9. 知识图谱卷积神经网络,Knowledge Graph Convolutional Networks for Recommender Systems with Label Smoothness Regularization
KDD ’19
作者:Hongwei Wang, Fuzheng Zhang, Mengdi Zhang, Jure Leskovec, Miao Zhao, Wenjie Li, Zhongyuan Wang
摘要:知识图谱捕捉实体之间的相互关联的信息,表示结构化信息,可以用于推荐系统。然而,现有的推荐引擎通过手工设计功能来使用知识图谱,不支持端到端训练,或者提供较差的可伸缩性。在这里,我们提出了知识图谱卷积网络(KGCN),这是一个端到端可训练的框架,利用知识图捕获的物品关系提供更好的建议。从概念上讲,KGCN首先应用一个可训练的函数来计算特定于用户的项嵌入,该函数识别给定用户的重要知识图谱关系,然后将知识图谱转换为特定于用户的加权图。然后,KGCN应用一个图卷积神经网络,通过传播和聚合知识图邻域信息来计算项节点的嵌入。此外,为了提供更好的归纳偏置,KGCN使用标签平滑(LS),它提供了超过边缘权值的正则化,我们证明了它等价于图上的标签传播方案。最后,我们将KGCN和LS规范化相结合,提出了一种适用于KGCN-LS模型的可伸缩的小批量实现。实验表明,KGCN-LS在四个数据集中都优于Baseline。KGCN-LS还在稀疏场景中获得了很好的性能,并且在知识图谱大小方面具有很高的可伸缩性。。
网址:
http://www.zhuanzhi.ai/paper/e4d171cb4c7db417f16783e8cd4a27ff
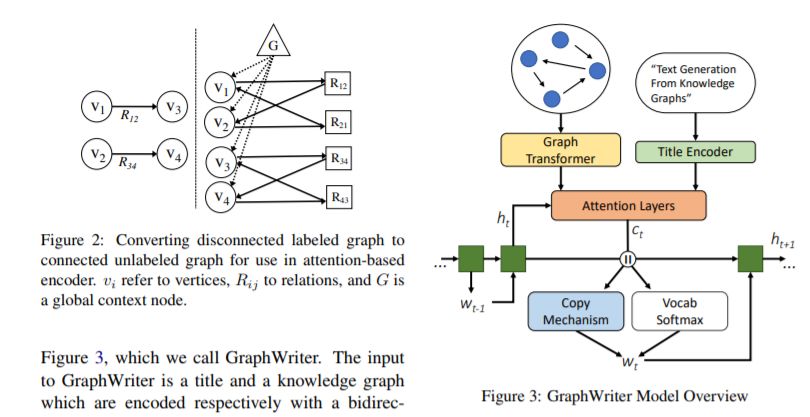
10. 知识图谱文本生成,Text Generation from Knowledge Graphs with Graph Transformers
NAACL ’19
作者:Rik Koncel-Kedziorski, Dhanush Bekal, Yi Luan, Mirella Lapata, Hannaneh Hajishirzi
摘要:生成表达跨越多个句子的复杂思想的文本需要对其内容进行结构化表示,但是手工生成这些表示非常昂贵。在这项工作中,我们解决了从一个信息提取系统的输出,特别是一个知识图谱生成连贯的多句文本的问题。图形化知识表示在计算中是普遍存在的,但由于其非层次性、远程依赖关系的崩溃和结构的多样性,给文本生成技术带来了巨大的挑战。本文介绍了一种新的图形转换编码器,它可以利用这些知识图谱的关系结构,而不需要施加线性化或层次约束。结合编解码器的设置,我们提供了一个端到端可训练的系统,用于生成应用于科学文本领域的图形到文本的生成。自动和人工评估表明,我们的技术产生了更多的信息文本,显示出更好的文档结构比竞争的编译码方法。
网址:
http://www.zhuanzhi.ai/paper/e9b54cb43678590fe738f2fbebaeed60
请关注专知公众号(点击上方蓝色专知关注)
后台回复“KG2019” 就可以获取《十篇论文》的下载链接~
-END-
专 · 知
专知,专业可信的人工智能知识分发,让认知协作更快更好!欢迎登录www.zhuanzhi.ai,注册登录专知,获取更多AI知识资料!

欢迎微信扫一扫加入专知人工智能知识星球群,获取最新AI专业干货知识教程视频资料和与专家交流咨询!

请加专知小助手微信(扫一扫如下二维码添加),加入专知人工智能主题群,咨询技术商务合作~

专知《深度学习:算法到实战》课程全部完成!550+位同学在学习,现在报名,限时优惠!网易云课堂人工智能畅销榜首位!

点击“阅读原文”,了解报名专知《深度学习:算法到实战》课程




