学界 | 神经网络的气宗与剑宗之争:先验强大的网络甚至不需要训练

神经网络形态的新思考
AI 科技评论按:深度神经网络中有许多连接权重,这些权重的值对网络表现有巨大影响;通过反向传播可以定向优化这些权重,提高网络的表现,这个过程被称作「训练」;训练过程通常需要多轮迭代,需要大量的稠密矩阵运算;这些都是领域内的常识。因为训练过程如此地重要,深度学习研究人员们都会设立多 GPU 阵列加速训练过程,关于训练技巧的论文连篇累牍,甚至还有「深度学习调参师」、「玄学调参」、「希望上帝给我一个好的初始随机种子」之类的调侃。
那么连接权重是影响神经网络表现的唯一因素吗?应该也不是。不仅近几年中人类手工设计的许多网络架构以更少的参数、更高的表现证明了网络架构重要性,神经架构搜索(NAS)更在各种任务中分别找到了可以达到更高表现的网络架构。不过,这些网络架构都仍然需要经过适当的训练才能得到好的表现,似乎只是说明了「适当的架构和适当的训练可以相得益彰」。
本着对照实验的精神,我们似乎应该设计另一组实验:为了说明训练的影响,我们在相同架构的网络上做不同的训练;那为了说明架构的影响,我们需要在不同架构的网络上做相同的训练;根据实验结果我们就可以定性、定量地分析训练和架构各自的影响,厘清这场神经网络的「气宗与剑宗之争」(网络结构与训练的影响之争)。
说明架构影响的这件事并不好做,如何在不同架构的网络上做相同的训练就首先是一个难题。谷歌大脑的研究人员 Adam Gaier 和 David Ha 在近期的论文《Weight Agnostic Neural Networks》(https://arxiv.org/abs/1906.04358)中做出了自己的尝试,得到了有趣的结果。AI 科技评论简单介绍如下。
· 寻找连接权重不重要的神经网络
之前就有研究人员展示了权重随机初始化的 LSTM 和 CNN 网络具有意外地好的表现,在这篇论文中两位作者更进一步地提出要寻找 weight agnostic neural networks,WANN,权重不可知的神经网络,即具有强大的归纳偏倚、以至于只使用随机权重就能够执行多种任务的神经网络。
为了能够完成实验,作者们提出了新的实验思路:
网络中的每个连接都使用同一个随机参数作为权重 —— 最小化权重(也就是训练过程)的影响,同样也最大程度简化了模型表现的采样空间
在很大的范围内取这个参数的值,多次评估网络的表现 —— 不再以最优的权重设置作为网络表现评价的唯一目标
根据算法信息理论,作者们并不满足于能够找到满足要求的网络,而是能最简单地描述的网络。比如,有两个不同的网络能带来类似的表现的话,他们会留下更简单的那个 —— 网络大小也就成为了搜索过程中的一个附加目标。结合连接计算成本以及其它一些技巧,他们希望最终找到的网络要尽可能简单、模块化以及可演化,并且更复杂的网络必须能够带来更好的表现。
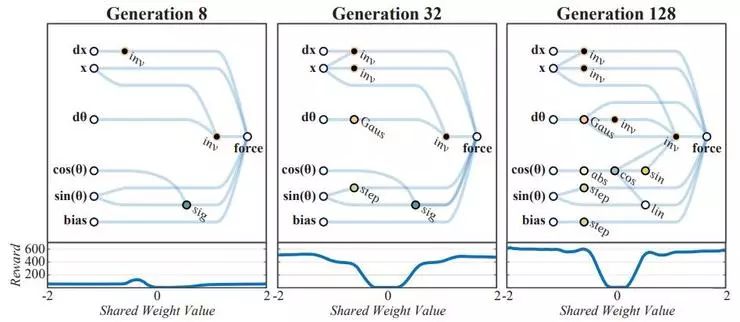
某个搜索过程的图示:早期的网络搜索结果在各种参数取值下表现都不好;后来网络建立起一些输入量之间的联系后,在某些范围的参数取值下可以达到较好的表现
具体搜索过程请参见论文原文。
· 实验结果
作者们在多个连续控制任务中评估了搜索得到的网络。
CartPoleSwingUp,一个小车上用铰链悬挂一根棍子,小车只能通过横向移动把棍子在上方直立起来并保持;这个过程里小车只能在有限的范围内运动。这个任务无法通过一个简单的线性控制器解决。
BipedalWalker,控制一个双足机器人的两个髋关节和两个膝关节,让它在随机地形上行走。
CarRacing,根据上帝视角的画面像素输入控制赛车在赛道上运动。
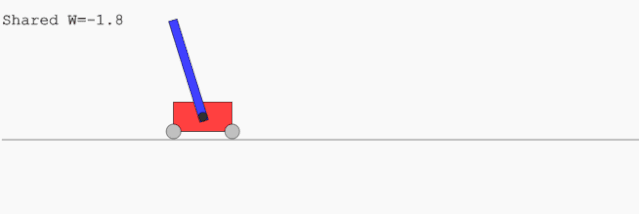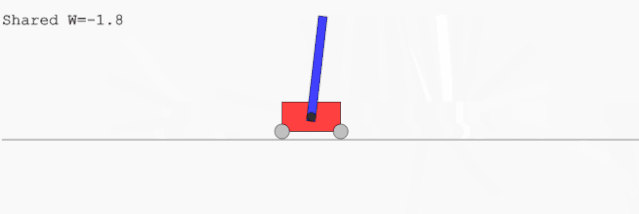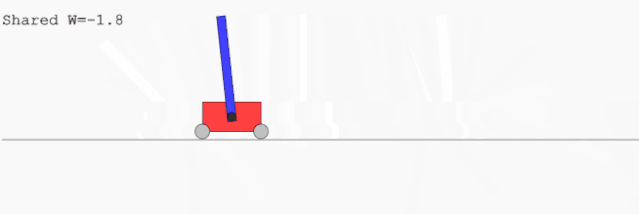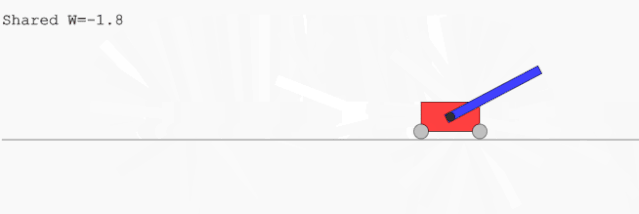
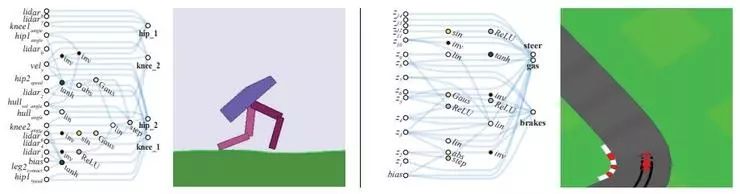
左图:为 BipedalWalker 任务找到的网络;右图:为 CarRacing 任务找到的网络
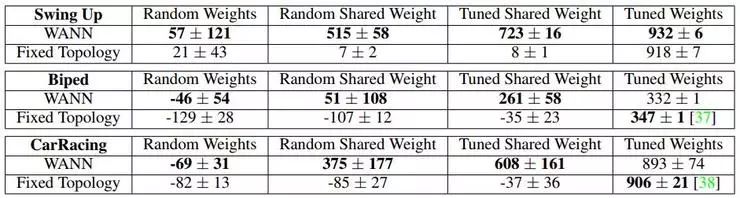
上图表格展示的是 WANN 找到的网络在超过 100 次试验中的表现(所以分数呈现为范围)。纵向对比的是传统的强化学习算法,横向的四项子分数分别是:
Random weights,每个连接权重分别从 (-2,2) 范围随机取值;
Random shared weight,所有连接使用同一个权重,从 (-2,2) 范围随机取值;
Tuned shared weight,所有连接使用同一个权重,从 (-2,2) 范围内取值时的最好表现;
Tuned weights,有权重优化过程,不同的权重允许有不同的变化(也就是传统的训练)
根据表格可以看到,传统强化学习算法中的权重必须经过训练以后才能得到好的表现,相比之下 WANN 寻找到的网络只需要所有连接都使用同一个随机权重就有机会得到好的表现。
所有连接使用同一个权重时得到的最好表现是喜人的,晃悠几次就可以让小棍平衡,走路时可以有高效的步法,开赛车的时候甚至还能从内侧切弯。而进一步进行传统意义上的训练以后,网络的表现还能有进一步的改善。
另外,作者们也做了监督学习(MNIST 数字识别)实验,也找到了能够比随机权值 CNN 得到更好表现的网络。
· 结果解读
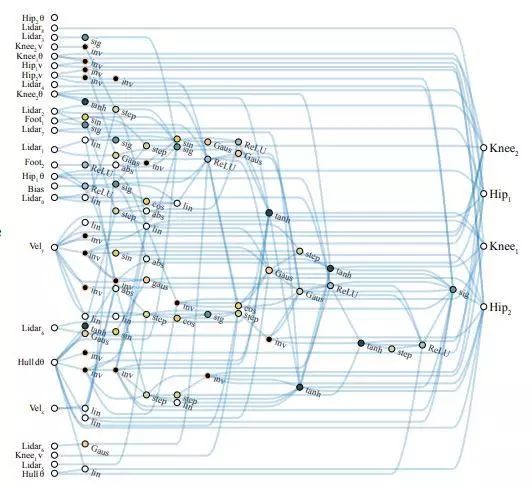
搜索到的在 BipedalWalker 中表现最好的网络结构
由于 WANN 搜索到的网络相对简单,作者们也尝试解读这些网络架构。首先,网络架构中明显地为任务编码了强大的偏倚,在如此浅层的连接中可以明显看到网络对不同输入信号的处理加工过程;但同时,找到的网络的表现也并不是与权重的值完全无关,在某些随机值下还是会出现不好的表现。可以看作,WANN 搜索到的网络对输入输出间的关系进行了强大的编码,虽然权值的大小相比之下变得不重要,但信号的连续性、符号一致性还是有影响的。观察搜索过程中网络如何一步步变得复杂的也能得到类似的感受。
WANN 搜索到的网络的最佳表现最终还是比不上 CNN 的最佳表现,这并不奇怪,毕竟 CNN 本身也是带有很强的视觉偏倚的架构,而且经过了如此多年的持续优化改进。
在这项研究中雷锋网 AI 科技评论感觉到的是,解决指定任务所需的偏倚总需要通过某种方式编码到网络内。传统的深度学习研究中都是固定网络架构(基础模块和连接方式),用连接权重的更新体现这些偏倚;在 WANN 中,架构和权重的位置调换,用随机取值且不要求优化过程的共享权重限制了偏倚在权重中的储存,从而得以让偏倚显式地体现为架构的更新。作者们也在论文的讨论章节中指出,这种思路在小样本学习、在线学习、终生学习中都可能能够派上用场(持续地优化更新网络架构)。这不仅新奇,也是继续探索神经网络潜力的一条新的道路。「气」和「剑法」并重,也许未来我们有机会能够改进神经网络的更多弱点。
论文原文地址:https://arxiv.org/abs/1906.04358
互动式论文页面(带有 demo):https://weightagnostic.github.io/
2019 年 7 月 12 日至 14 日,由中国计算机学会(CCF)主办、雷锋网和香港中文大学(深圳)联合承办,深圳市人工智能与机器人研究院协办的 2019 全球人工智能与机器人峰会(简称 CCF-GAIR 2019)将于深圳正式启幕。
届时,诺贝尔奖得主JamesJ. Heckman、中外院士、世界顶会主席、知名Fellow,多位重磅嘉宾将亲自坐阵,一起探讨人工智能和机器人领域学、产、投等复杂的生存态势。






