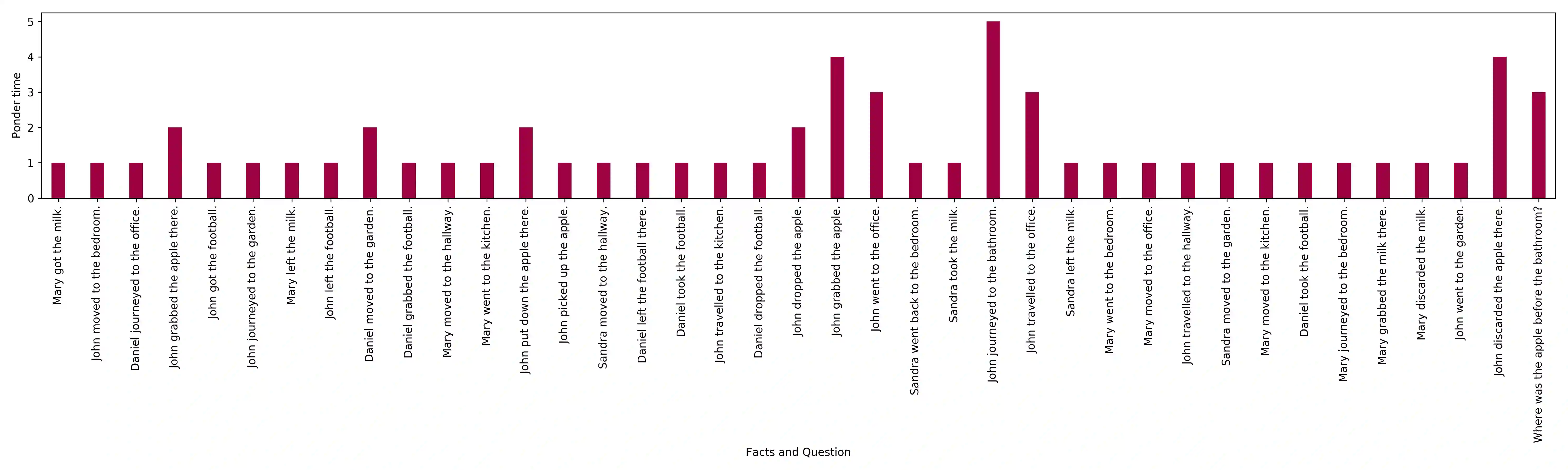
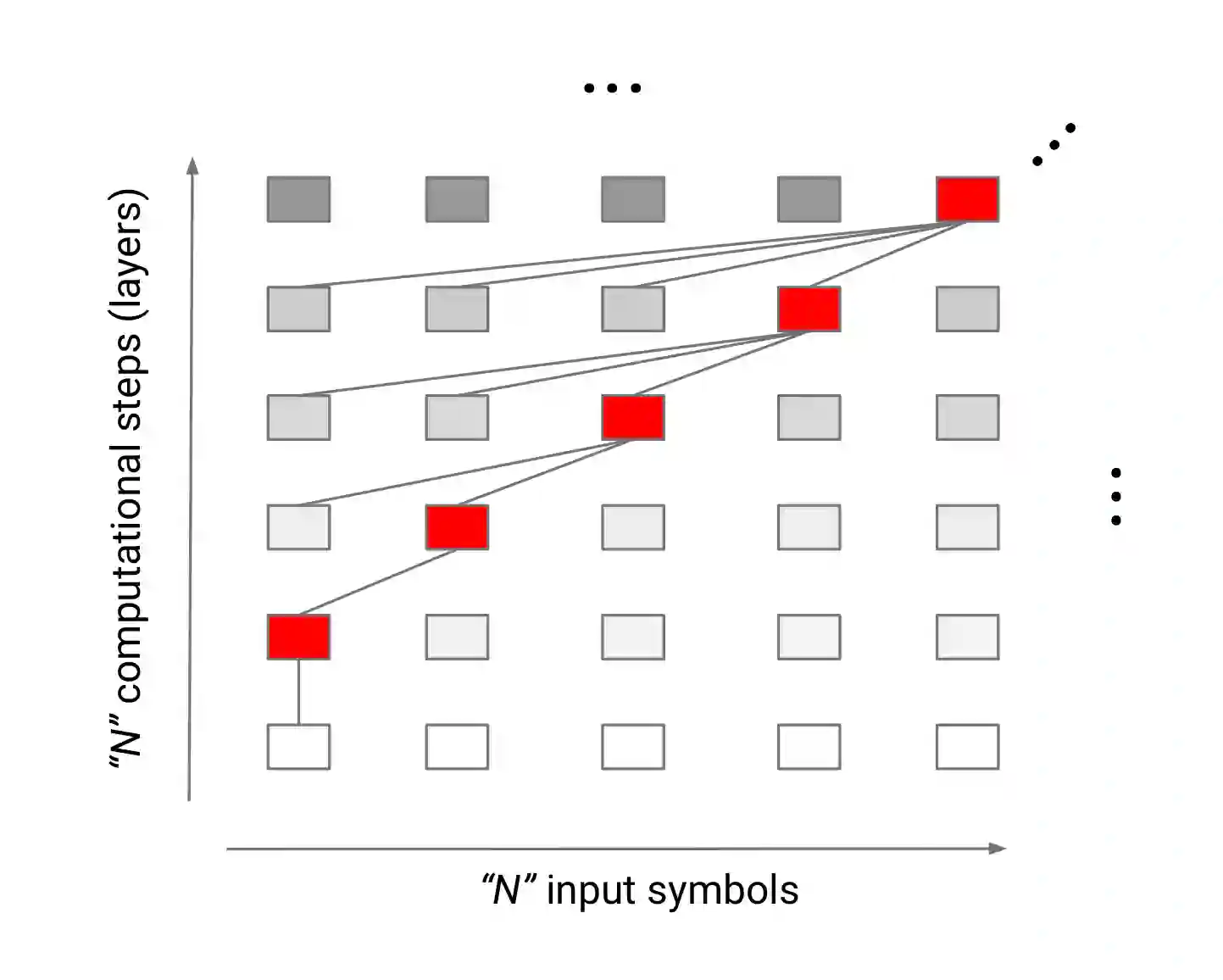
Recurrent neural networks (RNNs) sequentially process data by updating their state with each new data point, and have long been the de facto choice for sequence modeling tasks. However, their inherently sequential computation makes them slow to train. Feed-forward and convolutional architectures have recently been shown to achieve superior results on some sequence modeling tasks such as machine translation, with the added advantage that they concurrently process all inputs in the sequence, leading to easy parallelization and faster training times. Despite these successes, however, popular feed-forward sequence models like the Transformer fail to generalize in many simple tasks that recurrent models handle with ease, e.g. copying strings or even simple logical inference when the string or formula lengths exceed those observed at training time. We propose the Universal Transformer (UT), a parallel-in-time self-attentive recurrent sequence model which can be cast as a generalization of the Transformer model and which addresses these issues. UTs combine the parallelizability and global receptive field of feed-forward sequence models like the Transformer with the recurrent inductive bias of RNNs. We also add a dynamic per-position halting mechanism and find that it improves accuracy on several tasks. In contrast to the standard Transformer, under certain assumptions, UTs can be shown to be Turing-complete. Our experiments show that UTs outperform standard Transformers on a wide range of algorithmic and language understanding tasks, including the challenging LAMBADA language modeling task where UTs achieve a new state of the art, and machine translation where UTs achieve a 0.9 BLEU improvement over Transformers on the WMT14 En-De dataset.
翻译:经常神经网络(RNNS) 以每个新数据点更新其状态, 并长期以来一直是对序列建模任务的实际选择。 但是, 它们的内在顺序计算使得它们训练速度缓慢。 最近显示, 某些序列建模任务( 如机器翻译) 取得了优异的结果, 其附加优势是, 它们同时处理序列中的所有输入, 导致容易的平行和更快的培训时间。 尽管取得了这些成功, 但是, 像变换器这样的广受欢迎的反馈向向前序列模型未能在经常模型轻松处理的许多简单任务中一概化, 例如, 复制字符串甚至简单的逻辑推论, 当字符串或公式长度超过培训时所观察到的。 我们提议通用变换器(UT), 是一个平行的自惯性重复序列模型, 它可以作为变换器模型的概括化和全局化语言向前变换顺序模型的组合, 比如, 复制字符串, 复制或更简单的逻辑推算, 在 RNNNSUT 的反复的变换时, 我们的变式变压的变压的变压系统将显示我们的标准的变压的变压的变压的变压的变压的变压模型, 。