干货丨Spark度量系统分析(送书福利)
点击上方“程序人生”,选择“置顶公众号”
第一时间关注程序猿(媛)身边的故事
对于一个系统而言,首先考虑要满足一些业务场景,并实现功能。随着系统功能越来越多,代码量级越来越高,系统的可维护性、可测试性、性能都会成为新的挑战,这是监控功能就变得越来越重要了。在国内,绝大多数IT公司的项目都以业务为导向,以完成功能为目标,这些项目在立项、设计、开发、上线的各个阶段,很少有人会考虑到监控的问题。在国内,开发人员能够认真的在代码段落中打印日志,就已经属于最优秀的程序员了。然而,在国外的很多项目则不会这样,看看久负盛名的Hadoop的监控系统就可见一斑,尤其是在Facebook,更是把功能、日志以及监控列为同等重要,作为一个合格工程师的三驾马车。
Spark作为优秀的开源系统,在监控方面也有自己的一整套体系。一个系统有了监控功能后将收获诸多益处,如可测试性、性能优化、运维评估、数据统计等。Spark的度量系统使用codahale提供的第三方度量仓库Metrics,本节将着重介绍Spark基于Metrics构建度量系统的原理与实现。对于Metrics感兴趣的读者,可以参考阅读笔者在博客http://blog.csdn.net/beliefer/article/details/77450039中的内容。
Spark的度量系统中有三个概念:
Instance:指定了度量系统的实例名。Spark按照Instance的不同,区分为Master、Worker、Application、Driver和Executor;
Source:指定了从哪里收集度量数据,即度量数据的来源。Spark提供了应用的度量来源(ApplicationSource)、Worker的度量来源(WorkerSource)、DAGScheduler的度量来源(DAGSchedulerSource)、BlockManager的度量来源(BlockManagerSource)等诸多实现,对各个服务或组件进行监控。
Sink:指定了往哪里输出度量数据,即度量数据的输出。Spark中使用MetricsServlet作为默认的Sink,此外还提供了ConsoleSink、CsvSink、JmxSink、MetricsServlet、GraphiteSink等实现。
为了更加直观地表现上述概念,我们以图1来表示Spark中度量系统的工作流程。
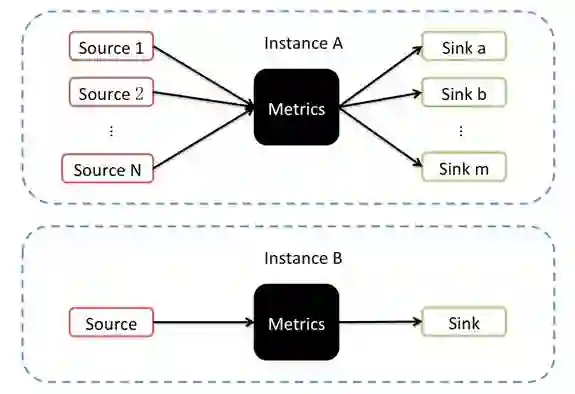
图1 度量系统的工作流程
1. Source继承体系
任何监控都离不开度量数据的采集,离线的数据采集很容易做到和被采集模块之间的解耦,但是对于实时度量数据,尤其是那些内存中数据的采集就很难解耦。这就类似于网页监控数据的埋点一样,你要在网页中加入一段额外的JS代码(例如Google分析,即便你只是引入一个js文件,这很难让前端工程师感到开心)。还有一类监控,比如在Java Web中增加一个负责监控的Servlet或者一个基于Spring3.0的拦截器,这种方式虽然将耦合度从代码级别降低到配置级别,但却无法有效的对内存中的数据结构进行监控。Spark的度量系统对系统功能来说是在代码层面耦合的,这种牺牲对于能够换取对实时的、处于内存中的数据进行更有效的监控是值得的。
Spark将度量来源抽象为Source,其定义见代码清单1。
代码清单1 度量源的定义
private[spark] trait Source {
def sourceName: String
def metricRegistry: MetricRegistry
}
从代码清单3-51,可以看到Source是一个特质,其中定义了两个方法:
sourceName:度量源的名称;
metricRegistry:当前度量源的注册表。MetricRegistry是Metrics库提供的API,在博客http://blog.csdn.net/beliefer/article/details/77450039中有更详细的介绍。
Spark中有很多Source的具体实现,可以通过图2 来了解。
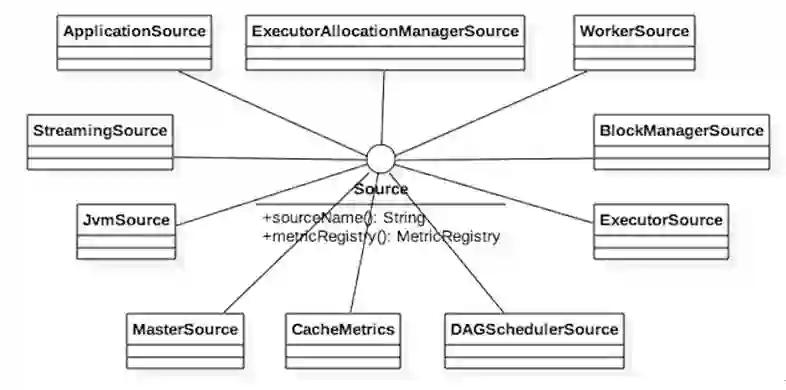
图2 Source的继承体系
为了说明Source该如何实现,我们选择ApplicationSource(也是因为其实现简单明了,足以说明问题)为例,其实现见代码清单2。
代码清单2 ApplicationSource的实现
private[master] class ApplicationSource(valapplication: ApplicationInfo) extends Source {
overridevalmetricRegistry = newMetricRegistry()
overridevalsourceName = "%s.%s.%s".format("application", application.desc.name,
System.currentTimeMillis())
metricRegistry.register(MetricRegistry.name("status"), newGauge[String] {
overridedef getValue:String = application.state.toString
})
metricRegistry.register(MetricRegistry.name("runtime_ms"), new Gauge[Long]{
overridedef getValue:Long = application.duration
})
metricRegistry.register(MetricRegistry.name("cores"), new Gauge[Int] {
overridedef getValue:Int = application.coresGranted
})
}
望文生义,ApplicationSource用于采集Spark应用程序相关的度量。代码清单3-52中ApplicationSource重载了metricRegistry和sourceName,并且向自身的注册表注册了status(即应用状态,包括:WAITING, RUNNING,FINISHED, FAILED, KILLED, UNKNOWN)、runtime_ms(运行持续时长)、cores(授权的内核数)等度量。这三个度量的取值分别来自于ApplicationInfo的state、duration和coresGranted三个属性。这三个度量都由Gauge的匿名内部类实现,Gauge是Metrics提供的用于估计度量值的特质。有关Gauge、MetricRegistry、MetricRegistry注册度量的方法register及命名方法name的更详细介绍请阅读博客http://blog.csdn.net/beliefer/article/details/77450039。
2. Sink继承体系
Source准备好度量数据后,我们就需要考虑如何输出和使用的问题。这里介绍一些常见的度量输出方式:阿里数据部门采用的一种度量使用方式就是输出到日志;在命令行运行过Hadoop任务(例如:mapreduce)的使用者也会发现控制台打印的内容中也包含度量信息;用户可能希望将有些度量信息保存到文件(例如CSV),以便将来能够查看;如果觉得使用CSV或者控制台等方式不够直观,还可以将采集到的度量数据输出到专用的监控系统界面。这些最终对度量数据的使用,或者说是输出方式,Spark将它们统一抽象为Sink。Sink的定义见代码清单3。
代码清单3 度量输出的定义
private[spark] trait Sink {
def start(): Unit
def stop(): Unit
def report(): Unit
}
从代码清单3-53可以看到Sink是一个特质,包含三个接口方法:
start:启动Sink;
stop:停止Sink;
report:输出到目的地;
从这三个方法的解释来看,很难让读者获得更多的信息。我们先把这些困惑放在一边,来看看Spark中Sink的类继承体系,如图3所示。
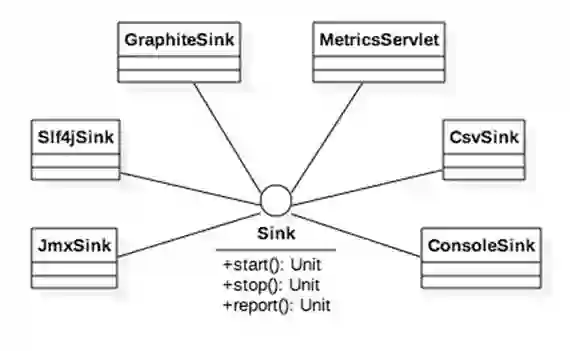
图3 Sink的类继承体系
图3中展示了6种Sink的具体实现。
ConsoleSink:借助Metrics提供的ConsoleReporter的API,将度量输出到System.out,因此可以输出到控制台。
CsvSink:借助Metrics提供的CsvReporter的API,将度量输出到CSV文件。
MetricsServlet:在Spark UI的jetty服务中创建ServletContextHandler,将度量数据通过Spark UI展示在浏览器中。
JmxSink:借助Metrics提供的JmxReporter的API,将度量输出到MBean中,这样就可以打开Java VisualVM,然后打开进程监控,给VisualVM安装MBeans插件后,选择MBeans标签页可以对JmxSink所有注册到JMX中的对象进行管理。
Slf4jSink:借助Metrics提供的Slf4jReporter的API,将度量输出到实现了Slf4j规范的日志输出。
GraphiteSink:借助Metrics提供的GraphiteReporter的API,将度量输出到Graphite(一个由Python实现的Web应用,采用django框架,用来收集服务器状态的监控系统)。
了解了Sink的类继承体系,我们挑选Slf4jSink作为Spark中Sink实现类的例子,来了解Sink具体该如何实现。Slf4jSink的实现见代码清单4。
代码清单4 Slf4jSink的实现
private[spark] class Slf4jSink(
valproperty:Properties,
valregistry:MetricRegistry,
securityMgr: SecurityManager)
extends Sink {
valSLF4J_DEFAULT_PERIOD = 10
valSLF4J_DEFAULT_UNIT = "SECONDS"
valSLF4J_KEY_PERIOD = "period"
valSLF4J_KEY_UNIT = "unit"
valpollPeriod = Option(property.getProperty(SLF4J_KEY_PERIOD)) match {
case Some(s) => s.toInt
case None => SLF4J_DEFAULT_PERIOD
}
valpollUnit: TimeUnit = Option(property.getProperty(SLF4J_KEY_UNIT)) match {
case Some(s) =>TimeUnit.valueOf(s.toUpperCase())
case None =>TimeUnit.valueOf(SLF4J_DEFAULT_UNIT)
}
MetricsSystem.checkMinimalPollingPeriod(pollUnit, pollPeriod)
valreporter: Slf4jReporter = Slf4jReporter.forRegistry(registry)
.convertDurationsTo(TimeUnit.MILLISECONDS)
.convertRatesTo(TimeUnit.SECONDS)
.build()
overridedef start() {
reporter.start(pollPeriod, pollUnit)
}
overridedef stop() {
reporter.stop()
}
overridedef report() {
reporter.report()
}
}
从Slf4jSink的实现可以看到Slf4jSink的start、stop及report实际都是代理了Metrics库中的Slf4jReporter的start、stop及report方法。Slf4jReporter的start方法实际是其父类ScheduledReporter的start实现。而传递的两个参数pollPeriod和pollUnit,正是被ScheduledReporter使用作为定时器获取数据的周期和时间单位。
——本文摘自《Spark内核设计的艺术》
评论有奖规则
如果你对哪本书感兴趣,可在本文下方以「书名+申请理由」的形式留言,根据你留言的申请理由,小编会从所有留言中挑出 5 名 参与评论的小伙伴送出该书的兑换码。
中奖者随机抽取,关键看你的留言是否足够真诚和打动小编啦~
中奖者会在发文后的2~3日内在留言区直接收到官方回复。
推荐阅读

内容简介:
1、多位专家联袂推荐,360大数据专家撰写,剖析Spark 2.1.0架构与实现精髓。
2、细化到方法级,提炼出多个流程图,立体呈现架构、环境、调度、存储、计算、部署、API七大核心设计。
点击图片get往期内容







