案例分享 | TensorFlow 大规模稀疏模型异步训练的分布式优化

文 / 刘童璇,Alibaba PAI 团队
Alibaba PAI 团队从 16 年开始在 TensorFlow上进行优化,结合阿里巴巴推荐、搜索、广告等核心业务,打造锤炼 TensorFlow 对超大规模稀疏模型的训练能力。在 2018 年 9 月在上海举行的”谷歌开发者日”,和 2019 年 3 月在美国举行的 “TensorFlow Developer Summit” 都曾分享过 (PAI: Platform of A.I. in Alibaba)。后续会持续和 TensorFlow 团队保持紧密的合作,通过 RecSys SIG,逐步开源内部针对超大规模稀疏模型训练的核心能力。
PAI: Platform of A.I. in Alibaba
https://www.youtube.com/watch?v=bpoe33TfVAk
背景
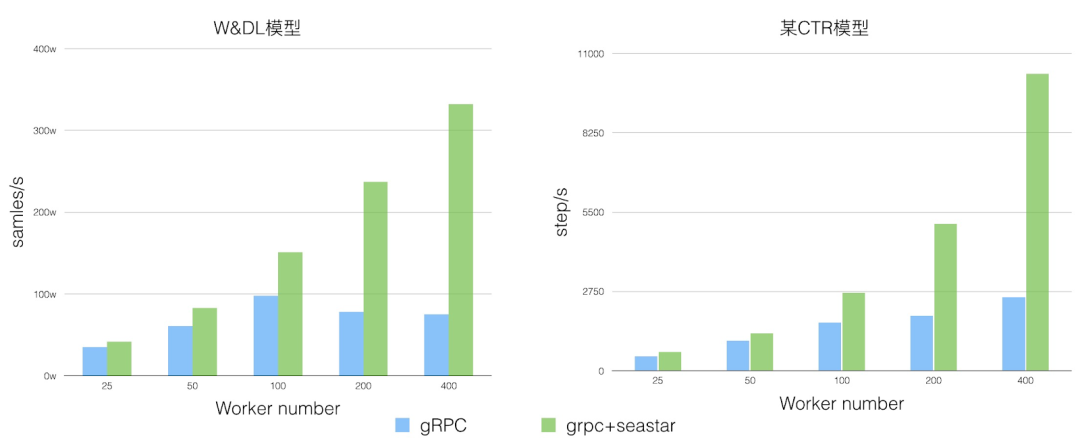
针对原生 TensorFlow 中进行超大规模稀疏训练时分布式扩展性不足的问题,Alibaba PAI 团队为 TensorFlow 社区贡献了 grpc+seastar 及 FuseRecv 两个功能。在一些典型的业务场景下,大大提升了稀疏模型训练的分布式扩展性。TensorFlow 社区内部分同学试用了这两个功能,在 400 worker 规模下能够提升 2-4 倍。
grpc+seastar
https://github.com/tensorflow/networking/pull/21
关键技术
原生 TensorFlow 中异步训练中,使用的 Send/Recv Op 进行跨节点的 Tensor 传输,其中 Recv 节点对应一个 RPC 请求来传输一个 Tensor,即使有 Recv Ops 输出到相同的目标 Op。而且每个即使接收到的张量是标量,Recv 节点也会触发一个 RPC 操作。如图:
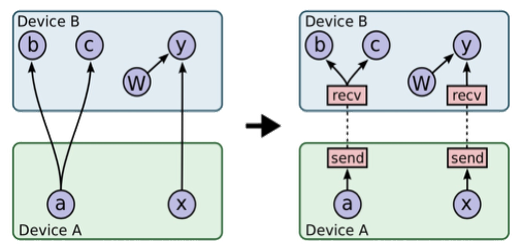
为了降低 RPC 的请求个数,同时确保不会因为 RPC 合并带来计算通信 Op 的无法很好 Overlap 问题。在图优化阶段,基于图拓扑进行 Recv Op 的合并,将多个 RecvOp 合并为 FuseRecvOp。RPC 在 WorkerInterface 增加 FuseRecvTensorAsync 接口,支持一个 RPC 传输多个 Rendezvous Key 和获取多个 Tensor。
如图所示,相比原生 TensorFlow 中 a, x 需要两个 Recv 节点进行两次 RPC,FuseRecv 节点会包含两个 slot,通过一次 RPC 将 a, x 从 Device A 中的 Rendezvous 中获取。
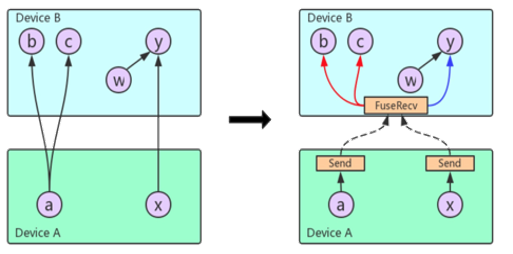
您可参考 FuseRecv 的详细设计文档,目前 RFC 已经过社区评审,被 TensorFlow 社区接受。我们正在将代码贡献给社区。
设计文档
https://github.com/tensorflow/community/pull/224
用户态零拷贝的数据传输
grpc+seastar 的 Request 及 Response 均由定长的 Header 附带一段或多段 Payload 组成。Header 与 Payload 可以独立的进行内存分配,并按照给定的顺序发送,从而在网络上形成完成的报文字节流。
在 RPC 的设计中,一个重要的问题是要在 wire format 层面解决 Response 消息与 Request 消息的关联。一种比较容易的想到的做法是将每次 RPC 请求用一个自增的 id 进行标识,然后再通过类似 map 的数据结构将 id 与 RPC 请求上下文进行关联。每次 Request 及 Response 的 wire format message 结构中,都需要携带该 RPC id,从而关联至上层逻辑。对于这种设计来说,一个显而易见的问题即是基于 RPC id 寻找上下文的“查表”开销会随着并发请求量的增大而迅速上涨,尤其在 TensorFlow 这种异步多线程场景下,很难做到无锁操作。
为了避免上述问题,我们采用了直接指针消息映射的策略:在我们的 Request 的 RPC Header 中,会有字段专门存放 context 的指针,而这一指针会在 Response 的 RPC Header 中被原样回传,从而实现直接内存映射,我们以 RPC client 端的场景为例,展示详细的数据结构如下图所示:
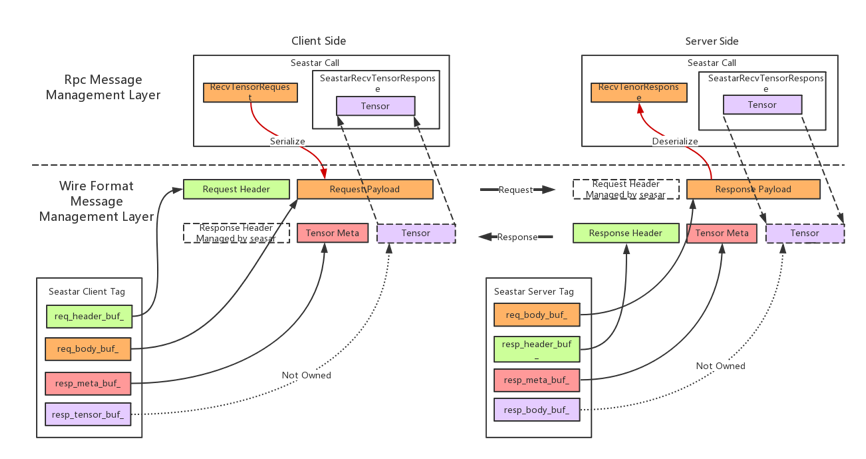
在 Tensor 的接收端,在完成定长的 tensor meta 字段的接收过程后,接收端的代码会直接调用对应 TensorFlow 中 Device 的 Allocator 为待接收的 Tensor 分配出适当的内存空间,底层通信层可以直接将 Tensor 的数据接收到该内存空间内。
通信收发链路无锁化
我们基于 Seastar 的设计特点,在通信收发链路的设计中延续了 Share-nothing 的设计,在完整的通信收发链路中整个流程通过 tls 实现了多线程的 share-nothing,并且基于 Message-Passing By Queue 的方式和外部的 TensorFlow 工作线程进行交互。
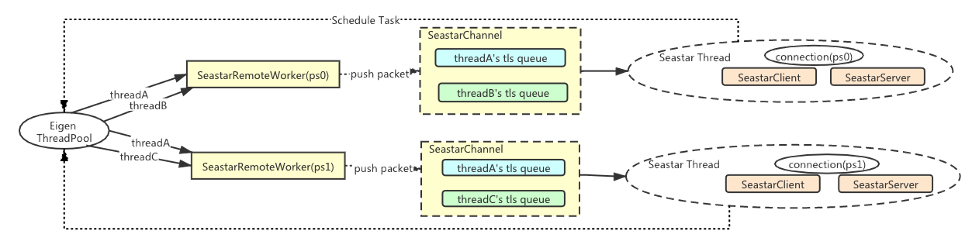
目前代码已经贡献给 TensorFlow 社区,请参考 RFC,代码和设计文档。
RFC
https://github.com/tensorflow/networking/pull/21代码
https://github.com/tensorflow/networking/tree/master/tensorflow_networking/seastar设计文档
https://docs.google.com/document/d/1f1m-98rbH33WE0qNb3tP0yt9Jjbb-rprvweLobRbTCA/edit
效果
经验分享
-
提供良好的覆盖很多细节的设计文档,可以帮助沟通,特别是比较少写英文文档的同学。 -
可以找相关 TensorFlow 团队同事,线下提前沟通,在提交给社区前有一些初步意见和迭代。而提交 RFC 给社区的时候,强有力的 TensorFlow 团队 Sponsor,也可以加速此过程。 -
TensorFlow 有很多 SIG 组织,一些贡献可以考虑通过 SIG 组织来获取反馈,比如 SIG AddOns,SIG IO,SIG Networking 等。grpc+seastar 的贡献过程得到了 SIG Networking 的 Bairen Yi 和 Jeroen Bédorf 的大力支持,给了很多建议。 -
获取社区中其他开发者的反馈也很有帮助。在以上功能的开发过程中,社区中其他同学提前尝试了我们的功能,并给了很好的反馈。
SIG
https://github.com/tensorflow/community/tree/master/sigs
致谢
🌟将我们设为星标
第一时间收到更新提醒
不再错过精彩内容!

分享 💬 点赞 👍 在看 ❤️
以“三连”行动支持优质内容!