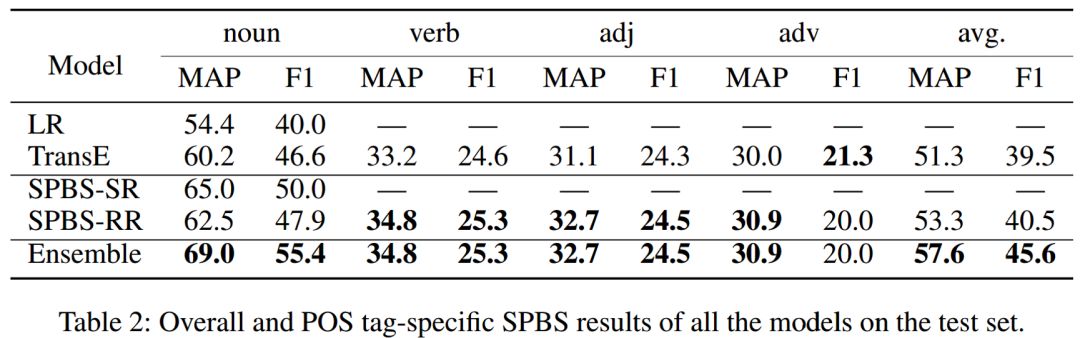
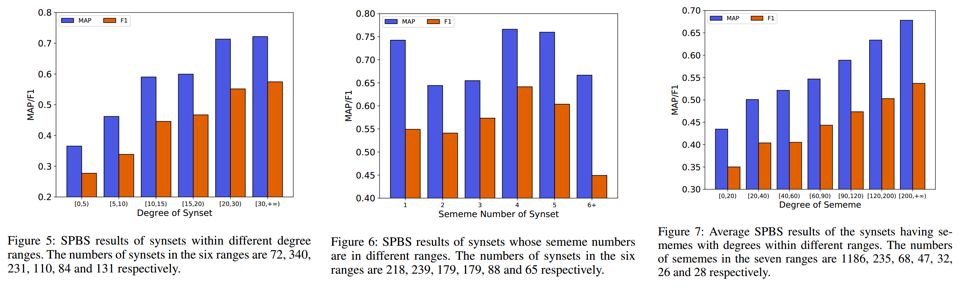
[1] Dong, Z., and Dong, Q. 2003. HowNet-a hybrid language and knowledge resource. In Proceedings of NLP-KE.[2] Liu, Q., and Li, S. 2002. Word similarity computing based on HowNet. International Journal of Computational Linguistics & Chinese Language Processing 7(2):59–76.[3] Duan, X.; Zhao, J.; and Xu, B. 2007. Word sense disambiguation through sememe labeling. In Proceedings of IJCAI.[4] Fu, X.; Liu, G.; Guo, Y.; and Wang, Z. 2013. Multi-aspect sentiment analysis for Chinese online social reviews based on topic modeling and HowNet lexicon. Knowledge-Based Systems 37:186–195.[5] Niu, Y.; Xie, R.; Liu, Z.; and Sun, M. 2017. Improved word representation learning with sememes. In Proceedings of ACL.[6] Gu, Y.; Yan, J.; Zhu, H.; Liu, Z.; Xie, R.; Sun, M.; Lin, F.; and Lin, L. 2018. Language modeling with sparse product of sememe experts. In Proceedings of EMNLP.[7] Qi, F.; Huang, J.; Yang, C.; Liu, Z.; Chen, X.; Liu, Q.; and Sun, M. 2019a. Modeling semantic compositionality with sememe knowledge. In Proceedings of ACL.[8] Luo, L.; Ao, X.; Song, Y.; Li, J.; Yang, X.; He, Q.; and Yu, Dong. 2019. Unsupervised Neural Aspect Extraction with Sememes. In Proceedings of IJCAI.[9] Zang, Y.; Yang, C.; Qi, F.; Liu, Z.; Zhang, M.; Liu, Q.; and Sun, M. 2019. Textual adversarial attack as combinatorial optimization. arXiv preprint arXiv:1910.12196.[10] Qin, Y.; Qi, F.; Ouyang, S.; Liu, Z.; Yang, C.; Wang, Y.; Liu, Q.; and Sun, M. 2019. Enhancing recurrent neural networks with sememes. arXiv preprint arXiv:1910.08910.[11] Qi, F.; Lin, Y.; Sun, M.; Zhu, H.; Xie, R.; and Liu, Z. 2018. Crosslingual lexical sememe prediction. In Proceedings of EMNLP.[12] Navigli, R., and Ponzetto, S. P. 2012a. BabelNet: The automatic construction, evaluation and application of a wide-coverage multilingual semantic network. Artificial Intelligence 193:217–250.[13] Camacho-Collados, J.; Pilehvar, M. T.; and Navigli, R. 2016. Nasari: Integrating explicit knowledge and corpus statistics for a multilingual representation of concepts and entities. Artificial Intelligence 240:36–64.



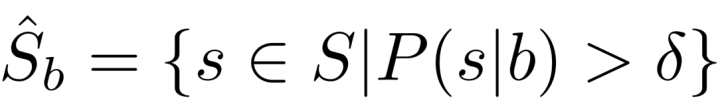
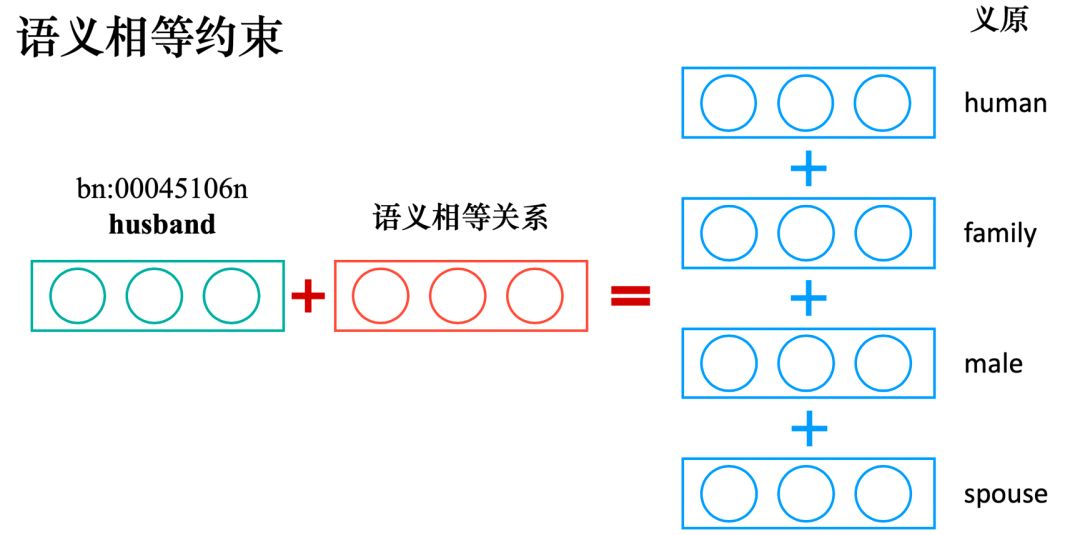
 为对 BabelNet 的某个 Synset “b” 的预测义原集合,P(s|b) 为给定 b 时,义原 s 的预测分数,
为对 BabelNet 的某个 Synset “b” 的预测义原集合,P(s|b) 为给定 b 时,义原 s 的预测分数,
 为义原预测分数阈值。
即为某个 synset 预测义原时,首先使用某种方法计算所有义原被预测给当前 synset 的分数,然后选取预测分数高于某个阈值的义原作为最终预测结果。
为义原预测分数阈值。
即为某个 synset 预测义原时,首先使用某种方法计算所有义原被预测给当前 synset 的分数,然后选取预测分数高于某个阈值的义原作为最终预测结果。
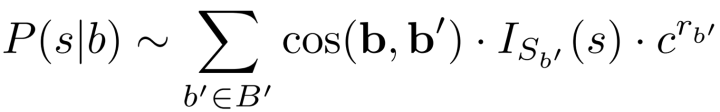
 为已有义原标注的 Synset 集合,
为已有义原标注的 Synset 集合,
 和
和
 分别表示 Synset 𝑏和𝑏′的 embedding,
分别表示 Synset 𝑏和𝑏′的 embedding,
 用来判断义原 s 是否在集合
用来判断义原 s 是否在集合
 中,
中,
 为递减置信因子。
为递减置信因子。
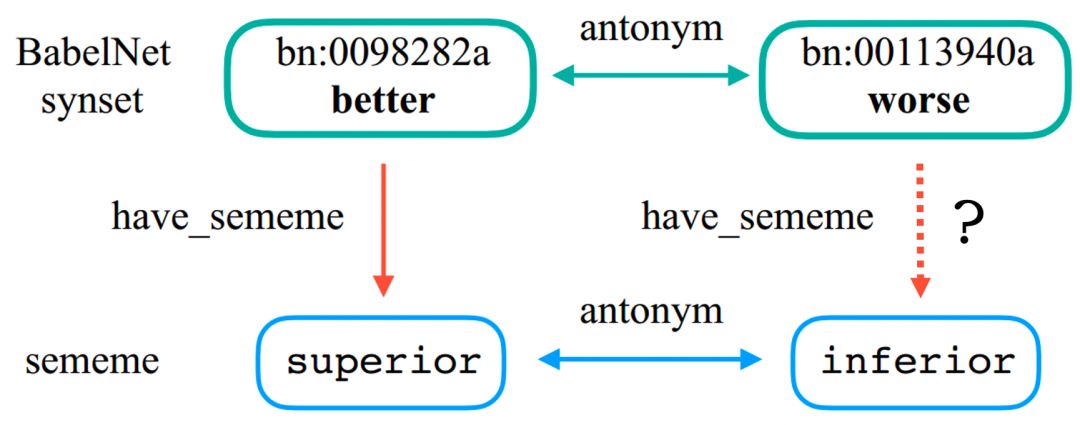
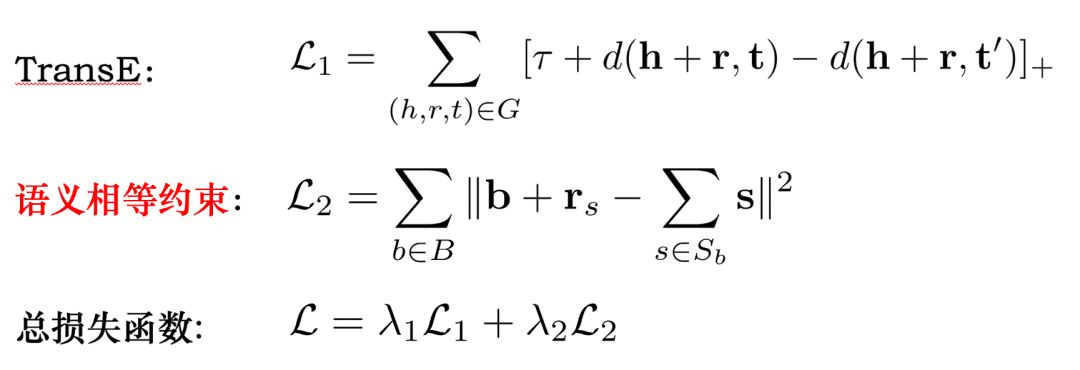
 。
。