【泡泡图灵智库】DenseFusion:基于迭代密集融合的6D目标姿态估计
泡泡图灵智库,带你精读机器人顶级会议文章
标题:DenseFusion: 6D Object Pose Estimation by Iterative Dense Fusion
作者:Chen Wang, Danfei Xu, Li Fei-Fei, et al.( Stanford University && Shanghai Jiao Tong University)
来源:cvpr 2019
播音员:
编译:林瑞豪
审核:李鑫,万应才
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

大家好,今天为大家带来的文章是——DenseFusion: 6D Object Pose Estimation by Iterative Dense Fusion
根据RGB-D图像执行6D对象位姿估计的关键是充分利用两个互补数据源。先前的工作要么分别从RGB图像和深度数据中提取信息,要么使用高计算量的后处理步骤,限制它们在高度混乱的场景和实时应用中的性能。在这项工作中,我们提出了DenseFusion,这是一个用于估计RGB-D图像中一组已知对象的6D位姿的通用框架。DenseFusion是一种异构架构,可以单独处理两个数据源,并使用一种新颖的稠密融合网络来提取像素级的稠密特征嵌入值,并据此估计位姿。此外,我们集成了端到端迭代位姿细化步骤,该位姿进一步改善了位姿估计值,同时实现了近实时的推理。我们的实验表明,我们的方法在两个数据集YCB-Video和LineMOD中优于最先进的方法。我们还将我们提出的方法部署到真实的机器人,机器人根据估计的位姿来抓取和操纵对象。我们的代码和视频已上传至网址https://sites.google.com/view/densefusion/ 。
主要贡献
1. 提出了一种新的方式来结合RGB-D的颜色和深度信息。我们在一个嵌入空间中用2D信息增强了3D点,并且用这个新的颜色-深度空间来估计6D位姿。
2. 在神经网络架构中集成了迭代细化步骤,移除了先前的方法对于后处理ICP步骤的依赖。
算法流程
1. 架构预览
主要分为两个阶段。第一个阶段,以彩色图为输入,根据已知对象种类进行语义分割,对于每个分割出来的对象,提取它的深度信息和彩色信息。第二个阶段,主要分为四步,第一步,用一个全卷积网络处理色彩信息,并且将图像块上的每个像素映射到一个彩色特征嵌入值;第二步,一个基于PointNet的网络将3D点映射到几何特征嵌入值;第三步,一个像素级的融合网络结合两个嵌入值,并基于无监督置信度打分输出对象的6D位姿,第四步,一个迭代自细化方法训练网络优化估计值。
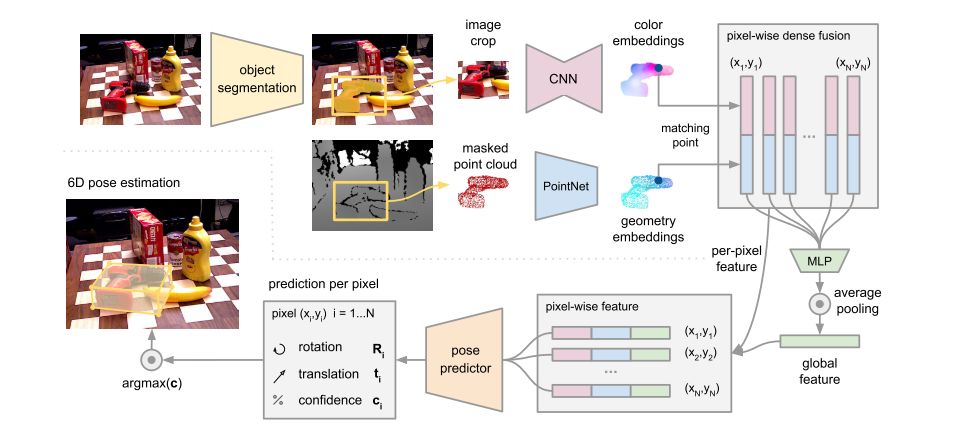
图1. 6D位姿估计模型框架
2. 语义分割
语义分割网络以图像为输入,生成一个N+1通道的语义分割地图。使用已经存在的分割架构,Posecnn: A convolutional neural network for 6d object pose estima- tion in cluttered scenes。
3. 稠密特征提取
分别在嵌入空间处理色彩和几何特征来保持数据源的内在结构。
3.1 稠密的3D点云特征嵌入值
首先利用相机的内参将分割后的深度像素转换为3D点云,然后使用类似PointNet的架构来提取几何特征。本文的几何嵌入值网络将P个分割后的点逐个映射到一个dgeo维的特征空间,生成稠密的单点特征。
3.2 稠密的彩色图像特征嵌入值
图像嵌入值网络是一个基于CNN的编码-解码架构,将H*W*3的图像映射到H*W*drgb嵌入空间。每个彩色图像特征嵌入值是一个drgb维的向量,代表了输入图像在该位置的纹理信息。
4. 像素级的稠密融合
利用相机内参将每个点的几何特征投影到图像平面,然后和对应的图像特征像素关联,最后将所有融合后的特征串联,输入到一个网络并利用一个对称下降函数来生成固定大小的全局特征向量。这里我们用全局特征来扩展单个稠密的像素特征,以提供全局语境。我们将单个像素特征输入到一个最终的网络并预测对象的位姿,注意,这里我们对每一个特征都预测一个位姿,对于有P个特征的对象,仅一个对象我们就得到P个位姿,然后适用一个自监督的方法来选择最好的预测值。这也就形成了我们的第一个学习目标。
5. 单像素自监督置信度
对于每一个像素,出了输出一个位姿估计值以外,还要输出一个置信度分数,用于形成我们的第二个学习目标。
6. 6D对象位姿估计
单个稠密像素的位姿估计损失为用真值位姿转换后的模型上的点与预测位姿转换后模型上对应点之间的距离。
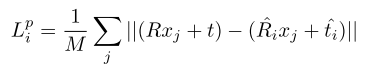
对于对称的对象,loss函数则为:
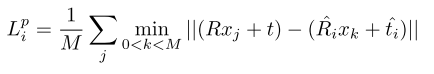
为了使我们的网络能够根据单个稠密像素预测值的置信度进行权衡,我们为每一个稠密像素损失加权,得到第二项置信度正则化项:
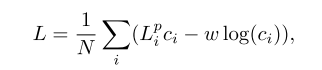
我们使用有最高置信度的位姿估计值作为最终的输出。
7.迭代细化:
这里我们提出了一个基于神经网络的迭代优化模型,该模型利用稠密融合的插入值改善最终的位姿估计结果而不需要额外的渲染引擎。
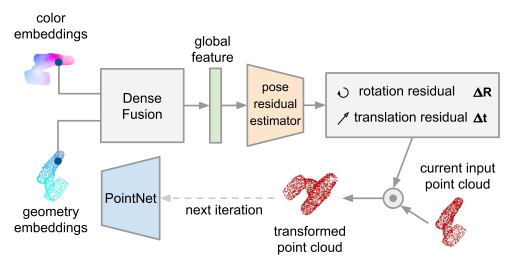
图2. 迭代位姿细化框架
主要结果
我们比较了四个模型来展示我们的设计的高效性。
PointFusion:单个CNN提取固定大小的特征向量,然后直接串联图像特征和几何特征进行融合;
Our(single):使用我们的稠密融合网络,直接使用全局特征向量输出一个预测值;
Ours(per-pixel):基于单个稠密融合特征实施单像素预测;
Ours(iterative):在Our(per-pixel)的基础上添加了迭代细化步骤(我们的完整的模型)。
1、在YCB-video数据集上的实验结果:我们选取了PoseCNN和我们的四个模型变量实验中ADD-S AUC(<0.1m)以及ADD-S<2cm的结果。
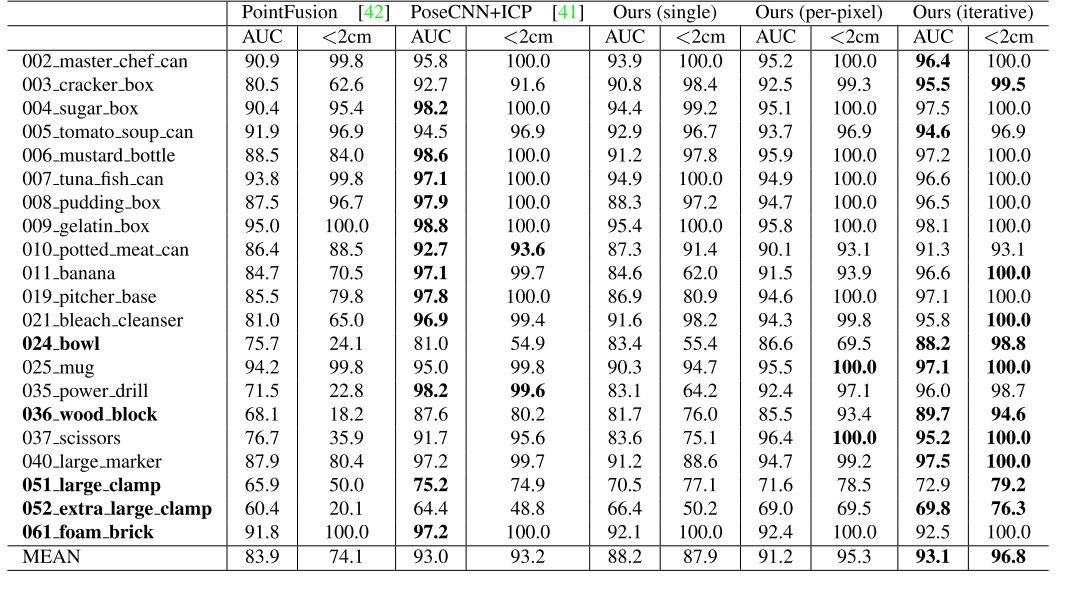
图3.YCB-Video数据集上定量评估结果,粗体的对象为对称对象
2、在LineMod数据集上的结果如下:

图4. LineMOD数据集上的定量评估结果

Abstract
A key technical challenge in performing 6D object pose estimation from RGB-D image is to fully leverage the two complementary data sources. Prior works either extract information from the RGB image and depth separately or use costly post-processing steps, limiting their performances in highly cluttered scenes and real-time applications. In this work, we present DenseFusion, a generic framework for estimating 6D pose of a set of known objects from RGB- D images. DenseFusion is a heterogeneous architecture that processes the two data sources individually and uses a novel dense fusion network to extract pixel-wise dense feature embedding, from which the pose is estimated. Furthermore, we integrate an end-to-end iterative pose refinement procedure that further improves the pose estimation while achieving near real-time inference. Our experiments show that our method outperforms state-of-the-art approaches in two datasets, YCB-Video and LineMOD.We also deploy our proposed method to a real robot to grasp and manipulate objects based on the estimated pose. Our code and video are available at https://sites.google.com/view/densefusion/.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号。
点击阅读原文,即可获取本文下载链接。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/bbs/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com
